 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEA-Guard: Culturally Grounded Multilingual Safeguard for Southeast Asia
Feb 02, 2026Culturally aware safeguards are crucial for AI alignment in real-world settings, where safety extends beyond common sense and encompasses diverse local values, norms, and region-specific regulations. However, building large-scale, culturally grounded datasets is challenging due to limited resources and a scarcity of native annotators. Consequently, many safeguard models rely on machine translation of English datasets, often missing regional and cultural nuances. We present a novel agentic data-generation framework to scalably create authentic, region-specific safety datasets for Southeast Asia (SEA). On this foundation, we introduce the SEA-Guard family, the first multilingual safeguard models grounded in SEA cultural contexts. Evaluated across multiple benchmarks and cultural variants, SEA-Guard consistently outperforms existing safeguards at detecting regionally sensitive or harmful content while maintaining strong general safety performance.
LoraxBench: A Multitask, Multilingual Benchmark Suite for 20 Indonesian Languages
Aug 17, 2025As one of the world's most populous countries, with 700 languages spoken, Indonesia is behind in terms of NLP progress. We introduce LoraxBench, a benchmark that focuses on low-resource languages of Indonesia and covers 6 diverse tasks: reading comprehension, open-domain QA, language inference, causal reasoning, translation, and cultural QA. Our dataset covers 20 languages, with the addition of two formality registers for three languages. We evaluate a diverse set of multilingual and region-focused LLMs and found that this benchmark is challenging. We note a visible discrepancy between performance in Indonesian and other languages, especially the low-resource ones. There is no clear lead when using a region-specific model as opposed to the general multilingual model. Lastly, we show that a change in register affects model performance, especially with registers not commonly found in social media, such as high-level politeness `Krama' Javanese.
TULUN: Transparent and Adaptable Low-resource Machine Translation
May 24, 2025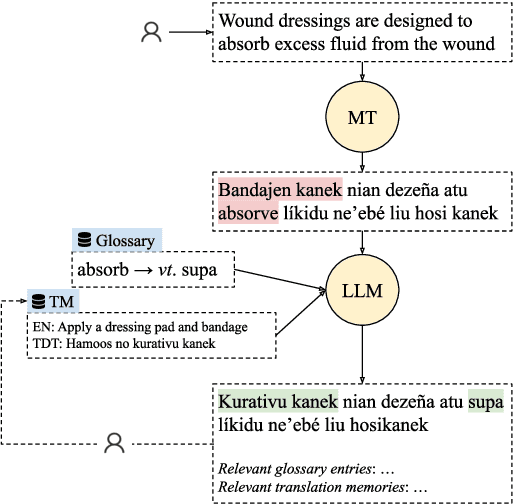
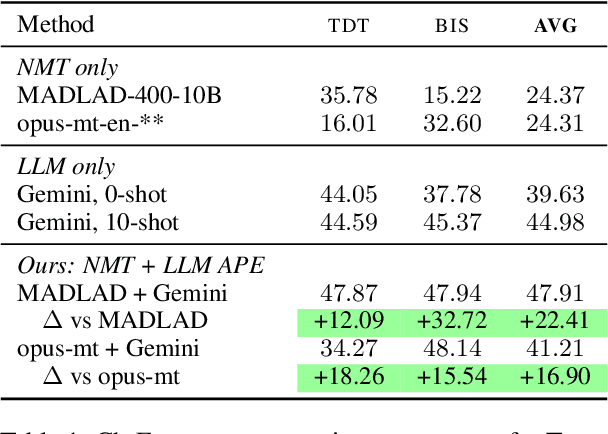
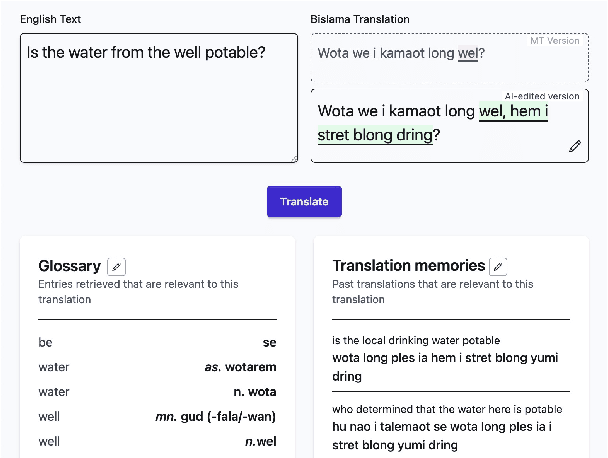
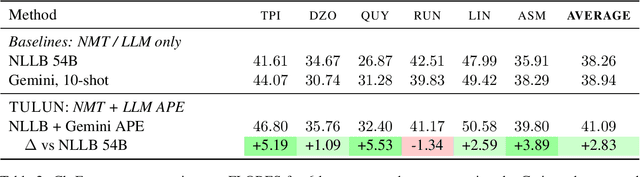
Machine translation (MT) systems that support low-resource languages often struggle on specialized domains. While researchers have proposed various techniques for domain adaptation, these approaches typically require model fine-tuning, making them impractical for non-technical users and small organizations. To address this gap, we propose Tulun, a versatile solution for terminology-aware translation, combining neural MT with large language model (LLM)-based post-editing guided by existing glossaries and translation memories. Our open-source web-based platform enables users to easily create, edit, and leverage terminology resources, fostering a collaborative human-machine translation process that respects and incorporates domain expertise while increasing MT accuracy. Evaluations show effectiveness in both real-world and benchmark scenarios: on medical and disaster relief translation tasks for Tetun and Bislama, our system achieves improvements of 16.90-22.41 ChrF++ points over baseline MT systems. Across six low-resource languages on the FLORES dataset, Tulun outperforms both standalone MT and LLM approaches, achieving an average improvement of 2.8 ChrF points over NLLB-54B.
Bridging Sign and Spoken Languages: Pseudo Gloss Generation for Sign Language Translation
May 21, 2025Sign Language Translation (SLT) aims to map sign language videos to spoken language text. A common approach relies on gloss annotations as an intermediate representation, decomposing SLT into two sub-tasks: video-to-gloss recognition and gloss-to-text translation. While effective, this paradigm depends on expert-annotated gloss labels, which are costly and rarely available in existing datasets, limiting its scalability. To address this challenge, we propose a gloss-free pseudo gloss generation framework that eliminates the need for human-annotated glosses while preserving the structured intermediate representation. Specifically, we prompt a Large Language Model (LLM) with a few example text-gloss pairs using in-context learning to produce draft sign glosses from spoken language text. To enhance the correspondence between LLM-generated pseudo glosses and the sign sequences in video, we correct the ordering in the pseudo glosses for better alignment via a weakly supervised learning process. This reordering facilitates the incorporation of auxiliary alignment objectives, and allows for the use of efficient supervision via a Connectionist Temporal Classification (CTC) loss. We train our SLT mode, which consists of a vision encoder and a translator, through a three-stage pipeline, which progressively narrows the modality gap between sign language and spoken language. Despite its simplicity, our approach outperforms previous state-of-the-art gloss-free frameworks on two SLT benchmarks and achieves competitive results compared to gloss-based methods.
Understanding Cross-Lingual Inconsistency in Large Language Models
May 19, 2025Large language models (LLMs) are demonstrably capable of cross-lingual transfer, but can produce inconsistent output when prompted with the same queries written in different languages. To understand how language models are able to generalize knowledge from one language to the others, we apply the logit lens to interpret the implicit steps taken by LLMs to solve multilingual multi-choice reasoning questions. We find LLMs predict inconsistently and are less accurate because they rely on subspaces of individual languages, rather than working in a shared semantic space. While larger models are more multilingual, we show their hidden states are more likely to dissociate from the shared representation compared to smaller models, but are nevertheless more capable of retrieving knowledge embedded across different languages. Finally, we demonstrate that knowledge sharing can be modulated by steering the models' latent processing towards the shared semantic space. We find reinforcing utilization of the shared space improves the models' multilingual reasoning performance, as a result of more knowledge transfer from, and better output consistency with English.
Few-Shot Multilingual Open-Domain QA from 5 Examples
Feb 27, 2025Recent approaches to multilingual open-domain question answering (MLODQA) have achieved promising results given abundant language-specific training data. However, the considerable annotation cost limits the application of these methods for underrepresented languages. We introduce a \emph{few-shot learning} approach to synthesise large-scale multilingual data from large language models (LLMs). Our method begins with large-scale self-supervised pre-training using WikiData, followed by training on high-quality synthetic multilingual data generated by prompting LLMs with few-shot supervision. The final model, \textsc{FsModQA}, significantly outperforms existing few-shot and supervised baselines in MLODQA and cross-lingual and monolingual retrieval. We further show our method can be extended for effective zero-shot adaptation to new languages through a \emph{cross-lingual prompting} strategy with only English-supervised data, making it a general and applicable solution for MLODQA tasks without costly large-scale annotation.
Franken-Adapter: Cross-Lingual Adaptation of LLMs by Embedding Surgery
Feb 12, 2025The capabilities of Large Language Models (LLMs) in low-resource languages lag far behind those in English, making their universal accessibility a significant challenge. To alleviate this, we present $\textit{Franken-Adapter}$, a modular language adaptation approach for decoder-only LLMs with embedding surgery. Our method begins by creating customized vocabularies for target languages and performing language adaptation through embedding tuning on multilingual data. These pre-trained embeddings are subsequently integrated with LLMs that have been instruction-tuned on English alignment data to enable zero-shot cross-lingual transfer. Our experiments on $\texttt{Gemma2}$ models with up to 27B parameters demonstrate improvements of up to 20% across 96 languages, spanning both discriminative and generative tasks, with minimal regressions ($<$1%) in English. Further in-depth analysis reveals the critical role of customizing tokenizers in enhancing language adaptation, while boosting inference efficiency. Additionally, we show the versatility of our method by achieving a 14% improvement over a math-optimized LLM across 20 languages, offering a modular solution to transfer reasoning abilities across languages post hoc.
Chasing Progress, Not Perfection: Revisiting Strategies for End-to-End LLM Plan Generation
Dec 14, 2024The capability of Large Language Models (LLMs) to plan remains a topic of debate. Some critics argue that strategies to boost LLMs' reasoning skills are ineffective in planning tasks, while others report strong outcomes merely from training models on a planning corpus. This study reassesses recent strategies by developing an end-to-end LLM planner and employing diverse metrics for a thorough evaluation. We find that merely fine-tuning LLMs on a corpus of planning instances does not lead to robust planning skills, as indicated by poor performance on out-of-distribution test sets. At the same time, we find that various strategies, including Chain-of-Thought, do enhance the probability of a plan being executable. This indicates progress towards better plan quality, despite not directly enhancing the final validity rate. Among the strategies we evaluated, reinforcement learning with our novel `Longest Contiguous Common Subsequence' reward emerged as the most effective, contributing to both plan validity and executability. Overall, our research addresses key misconceptions in the LLM-planning literature; we validate incremental progress in plan executability, although plan validity remains a challenge. Hence, future strategies should focus on both these aspects, drawing insights from our findings.
Low-resource Machine Translation: what for? who for? An observational study on a dedicated Tetun language translation service
Nov 19, 2024The impact of machine translation (MT) on low-resource languages remains poorly understood. In particular, observational studies of actual usage patterns are scarce. Such studies could provide valuable insights into user needs and behaviours, complementing survey-based methods. Here we present an observational analysis of real-world MT usage for Tetun, the lingua franca of Timor-Leste, using server logs from a widely-used MT service with over $70,000$ monthly active users. Our analysis of $100,000$ translation requests reveals patterns that challenge assumptions based on existing corpora. We find that users, many of them students on mobile devices, typically translate short texts into Tetun across diverse domains including science, healthcare, and daily life. This contrasts sharply with available Tetun corpora, which are dominated by news articles covering government and social issues. Our results suggest that MT systems for languages like Tetun should prioritise translating into the low-resource language, handling brief inputs effectively, and covering a wide range of domains relevant to educational contexts. More broadly, this study demonstrates how observational analysis can inform low-resource language technology development, by grounding research in practical community needs.
Planning in the Dark: LLM-Symbolic Planning Pipeline without Experts
Sep 24, 2024Large Language Models (LLMs) have shown promise in solving natural language-described planning tasks, but their direct use often leads to inconsistent reasoning and hallucination. While hybrid LLM-symbolic planning pipelines have emerged as a more robust alternative, they typically require extensive expert intervention to refine and validate generated action schemas. It not only limits scalability but also introduces a potential for biased interpretation, as a single expert's interpretation of ambiguous natural language descriptions might not align with the user's actual intent. To address this, we propose a novel approach that constructs an action schema library to generate multiple candidates, accounting for the diverse possible interpretations of natural language descriptions. We further introduce a semantic validation and ranking module that automatically filter and rank the generated schemas and plans without expert-in-the-loop. The experiments showed our pipeline maintains superiority in planning over the direct LLM planning approach. These findings demonstrate the feasibility of a fully automated end-to-end LLM-symbolic planner that requires no expert intervention, opening up the possibility for a broader audience to engage with AI planning with less prerequisite of domain expertise.