 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Throw Away Data: Better Sequence Knowledge Distillation
Paper and Code
Jul 15, 2024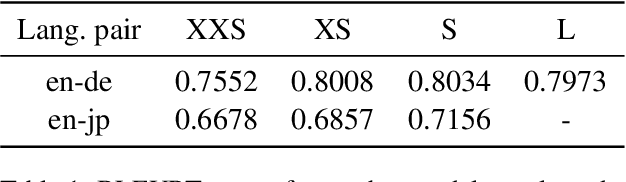
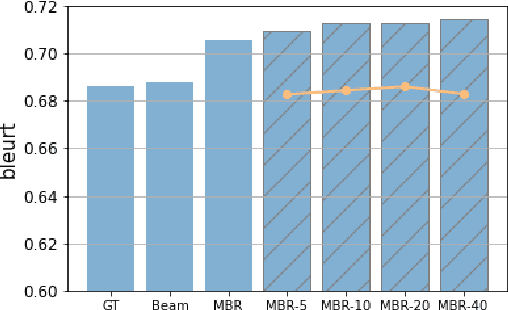
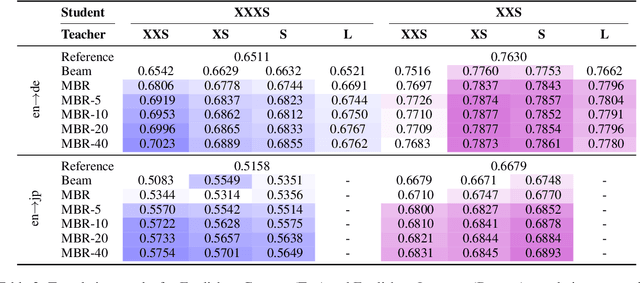
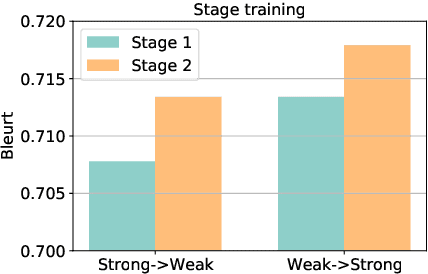
A critical component in knowledge distillation is the means of coupling the teacher and student. The predominant sequence knowledge distillation method involves supervised learning of the student against teacher-decoded outputs, and is exemplified by the current state of the art, which incorporates minimum Bayes risk (MBR) decoding. In this paper we seek to integrate MBR more tightly in distillation training, specifically by using several high scoring MBR translations, rather than a single selected sequence, thus capturing a rich diversity of teacher outputs. Our experiments on English to German and English to Japanese translation show consistent improvements over strong baseline methods for both tasks and with varying model sizes. Additionally, we conduct a detailed analysis focusing on data efficiency and capacity curse aspects to elucidate MBR-n and explore its further potential.