 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning, Fast and Slow: Towards LLMs That Adapt Continually
May 14, 2026Large language models (LLMs) are trained for downstream tasks by updating their parameters (e.g., via RL). However, updating parameters forces them to absorb task-specific information, which can result in catastrophic forgetting and loss of plasticity. In contrast, in-context learning with fixed LLM parameters can cheaply and rapidly adapt to task-specific requirements (e.g., prompt optimization), but cannot by itself typically match the performance gains available through updating LLM parameters. There is no good reason for restricting learning to being in-context or in-weights. Moreover, humans also likely learn at different time scales (e.g., System 1 vs 2). To this end, we introduce a fast-slow learning framework for LLMs, with model parameters as "slow" weights and optimized context as "fast" weights. These fast "weights" can learn from textual feedback to absorb the task-specific information, while allowing slow weights to stay closer to the base model and persist general reasoning behaviors. Fast-Slow Training (FST) is up to 3x more sample-efficient than only slow learning (RL) across reasoning tasks, while consistently reaching a higher performance asymptote. Moreover, FST-trained models remain closer to the base LLM (up to 70% less KL divergence), resulting in less catastrophic forgetting than RL-training. This reduced drift also preserves plasticity: after training on one task, FST trained models adapt more effectively to a subsequent task than parameter-only trained models. In continual learning scenarios, where task domains change on the fly, FST continues to acquire each new task while parameter-only RL stalls.
Shape of Thought: When Distribution Matters More than Correctness in Reasoning Tasks
Dec 24, 2025We present the surprising finding that a language model's reasoning capabilities can be improved by training on synthetic datasets of chain-of-thought (CoT) traces from more capable models, even when all of those traces lead to an incorrect final answer. Our experiments show this approach can yield better performance on reasoning tasks than training on human-annotated datasets. We hypothesize that two key factors explain this phenomenon: first, the distribution of synthetic data is inherently closer to the language model's own distribution, making it more amenable to learning. Second, these `incorrect' traces are often only partially flawed and contain valid reasoning steps from which the model can learn. To further test the first hypothesis, we use a language model to paraphrase human-annotated traces -- shifting their distribution closer to the model's own distribution -- and show that this improves performance. For the second hypothesis, we introduce increasingly flawed CoT traces and study to what extent models are tolerant to these flaws. We demonstrate our findings across various reasoning domains like math, algorithmic reasoning and code generation using MATH, GSM8K, Countdown and MBPP datasets on various language models ranging from 1.5B to 9B across Qwen, Llama, and Gemma models. Our study shows that curating datasets that are closer to the model's distribution is a critical aspect to consider. We also show that a correct final answer is not always a reliable indicator of a faithful reasoning process.
Putting the Value Back in RL: Better Test-Time Scaling by Unifying LLM Reasoners With Verifiers
May 07, 2025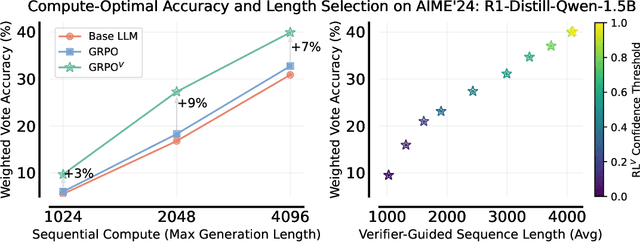
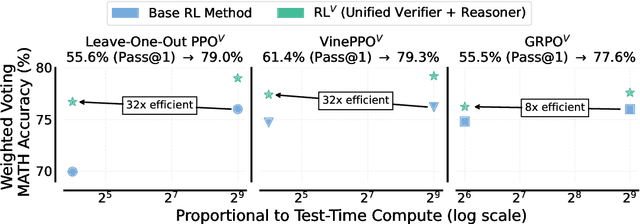
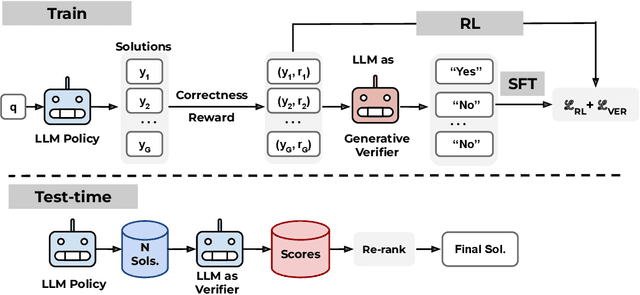
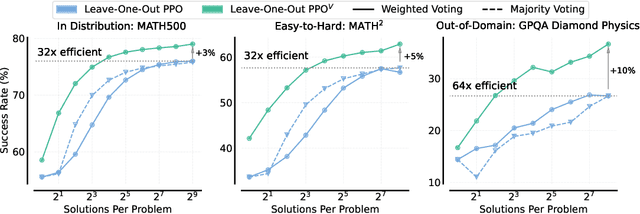
Prevalent reinforcement learning~(RL) methods for fine-tuning LLM reasoners, such as GRPO or Leave-one-out PPO, abandon the learned value function in favor of empirically estimated returns. This hinders test-time compute scaling that relies on using the value-function for verification. In this work, we propose RL$^V$ that augments any ``value-free'' RL method by jointly training the LLM as both a reasoner and a generative verifier using RL-generated data, adding verification capabilities without significant overhead. Empirically, RL$^V$ boosts MATH accuracy by over 20\% with parallel sampling and enables $8-32\times$ efficient test-time compute scaling compared to the base RL method. RL$^V$ also exhibits strong generalization capabilities for both easy-to-hard and out-of-domain tasks. Furthermore, RL$^V$ achieves $1.2-1.6\times$ higher performance when jointly scaling parallel and sequential test-time compute with a long reasoning R1 model.
Process Reward Models That Think
Apr 23, 2025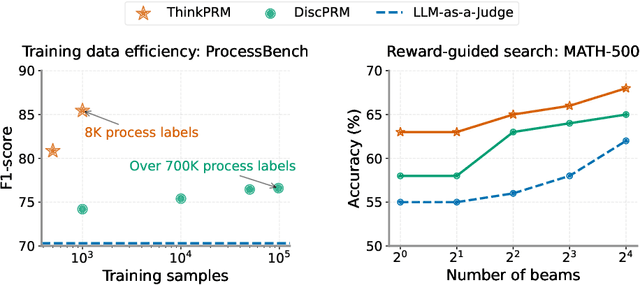
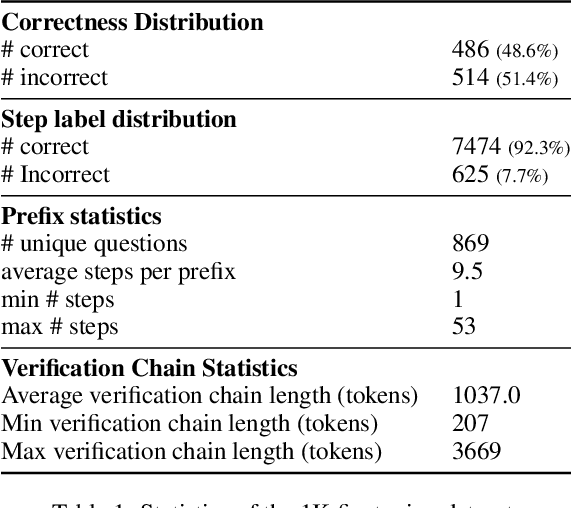
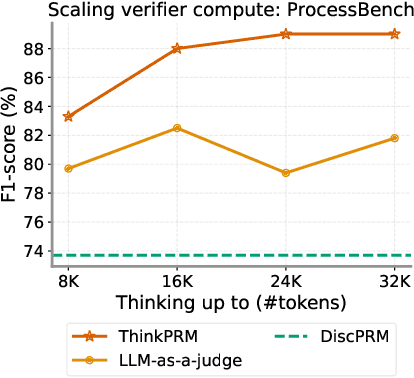
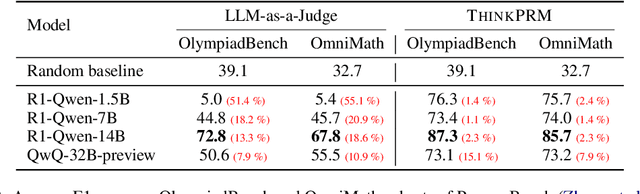
Step-by-step verifiers -- also known as process reward models (PRMs) -- are a key ingredient for test-time scaling. PRMs require step-level supervision, making them expensive to train. This work aims to build data-efficient PRMs as verbalized step-wise reward models that verify every step in the solution by generating a verification chain-of-thought (CoT). We propose ThinkPRM, a long CoT verifier fine-tuned on orders of magnitude fewer process labels than those required by discriminative PRMs. Our approach capitalizes on the inherent reasoning abilities of long CoT models, and outperforms LLM-as-a-Judge and discriminative verifiers -- using only 1% of the process labels in PRM800K -- across several challenging benchmarks. Specifically, ThinkPRM beats the baselines on ProcessBench, MATH-500, and AIME '24 under best-of-N selection and reward-guided search. In an out-of-domain evaluation on a subset of GPQA-Diamond and LiveCodeBench, our PRM surpasses discriminative verifiers trained on the full PRM800K by 8% and 4.5%, respectively. Lastly, under the same token budget, ThinkPRM scales up verification compute more effectively compared to LLM-as-a-Judge, outperforming it by 7.2% on a subset of ProcessBench. Our work highlights the value of generative, long CoT PRMs that can scale test-time compute for verification while requiring minimal supervision for training. Our code, data, and models will be released at https://github.com/mukhal/thinkprm.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Inference-Aware Fine-Tuning for Best-of-N Sampling in Large Language Models
Dec 18, 2024
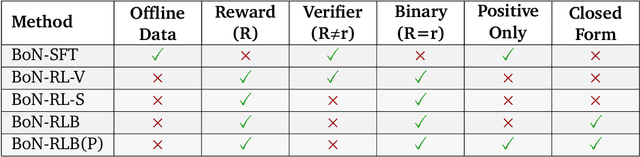
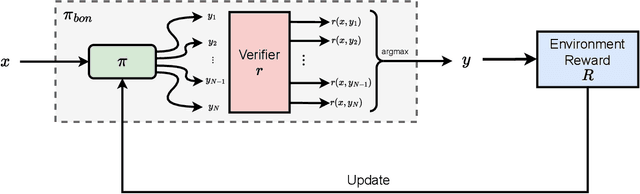
Recent studies have indicated that effectively utilizing inference-time compute is crucial for attaining better performance from large language models (LLMs). In this work, we propose a novel inference-aware fine-tuning paradigm, in which the model is fine-tuned in a manner that directly optimizes the performance of the inference-time strategy. We study this paradigm using the simple yet effective Best-of-N (BoN) inference strategy, in which a verifier selects the best out of a set of LLM-generated responses. We devise the first imitation learning and reinforcement learning~(RL) methods for BoN-aware fine-tuning, overcoming the challenging, non-differentiable argmax operator within BoN. We empirically demonstrate that our BoN-aware models implicitly learn a meta-strategy that interleaves best responses with more diverse responses that might be better suited to a test-time input -- a process reminiscent of the exploration-exploitation trade-off in RL. Our experiments demonstrate the effectiveness of BoN-aware fine-tuning in terms of improved performance and inference-time compute. In particular, we show that our methods improve the Bo32 performance of Gemma 2B on Hendrycks MATH from 26.8% to 30.8%, and pass@32 from 60.0% to 67.0%, as well as the pass@16 on HumanEval from 61.6% to 67.1%.
Evolving Alignment via Asymmetric Self-Play
Oct 31, 2024



Current RLHF frameworks for aligning large language models (LLMs) typically assume a fixed prompt distribution, which is sub-optimal and limits the scalability of alignment and generalizability of models. To address this, we introduce a general open-ended RLHF framework that casts alignment as an asymmetric game between two players: (i) a creator that generates increasingly informative prompt distributions using the reward model, and (ii) a solver that learns to produce more preferred responses on prompts produced by the creator. This framework of Evolving Alignment via Asymmetric Self-Play (eva), results in a simple and efficient approach that can utilize any existing RLHF algorithm for scalable alignment. eva outperforms state-of-the-art methods on widely-used benchmarks, without the need of any additional human crafted prompts. Specifically, eva improves the win rate of Gemma-2-9B-it on Arena-Hard from 51.6% to 60.1% with DPO, from 55.7% to 58.9% with SPPO, from 52.3% to 60.7% with SimPO, and from 54.8% to 60.3% with ORPO, surpassing its 27B version and matching claude-3-opus. This improvement is persistent even when new human crafted prompts are introduced. Finally, we show eva is effective and robust under various ablation settings.
Asynchronous RLHF: Faster and More Efficient Off-Policy RL for Language Models
Oct 23, 2024



The dominant paradigm for RLHF is online and on-policy RL: synchronously generating from the large language model (LLM) policy, labelling with a reward model, and learning using feedback on the LLM's own outputs. While performant, this paradigm is computationally inefficient. Inspired by classical deep RL literature, we propose separating generation and learning in RLHF. This enables asynchronous generation of new samples while simultaneously training on old samples, leading to faster training and more compute-optimal scaling. However, asynchronous training relies on an underexplored regime, online but off-policy RLHF: learning on samples from previous iterations of our model. To understand the challenges in this regime, we investigate a fundamental question: how much off-policyness can we tolerate for asynchronous training to speed up learning but maintain performance? Among several RLHF algorithms we tested, we find that online DPO is most robust to off-policy data, and robustness increases with the scale of the policy model. We study further compute optimizations for asynchronous RLHF but find that they come at a performance cost, giving rise to a trade-off. Finally, we verify the scalability of asynchronous RLHF by training LLaMA 3.1 8B on an instruction-following task 40% faster than a synchronous run while matching final performance.
Speculative Knowledge Distillation: Bridging the Teacher-Student Gap Through Interleaved Sampling
Oct 15, 2024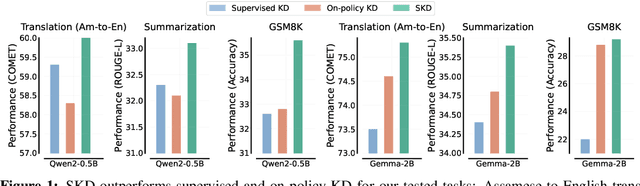
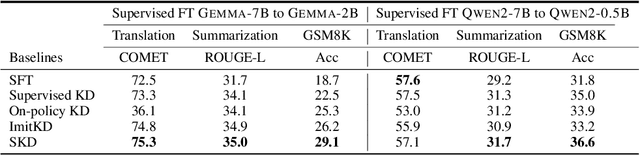

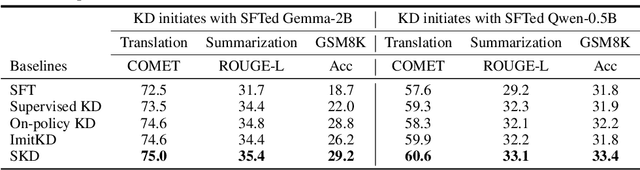
Recent advances in knowledge distillation (KD) have enabled smaller student models to approach the performance of larger teacher models. However, popular methods such as supervised KD and on-policy KD, are adversely impacted by the knowledge gaps between teacher-student in practical scenarios. Supervised KD suffers from a distribution mismatch between training with a static dataset and inference over final student-generated outputs. Conversely, on-policy KD, which uses student-generated samples for training, can suffer from low-quality training examples with which teacher models are not familiar, resulting in inaccurate teacher feedback. To address these limitations, we introduce Speculative Knowledge Distillation (SKD), a novel approach that leverages cooperation between student and teacher models to generate high-quality training data on-the-fly while aligning with the student's inference-time distribution. In SKD, the student proposes tokens, and the teacher replaces poorly ranked ones based on its own distribution, transferring high-quality knowledge adaptively. We evaluate SKD on various text generation tasks, including translation, summarization, math, and instruction following, and show that SKD consistently outperforms existing KD methods across different domains, data sizes, and model initialization strategies.
Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning
Oct 10, 2024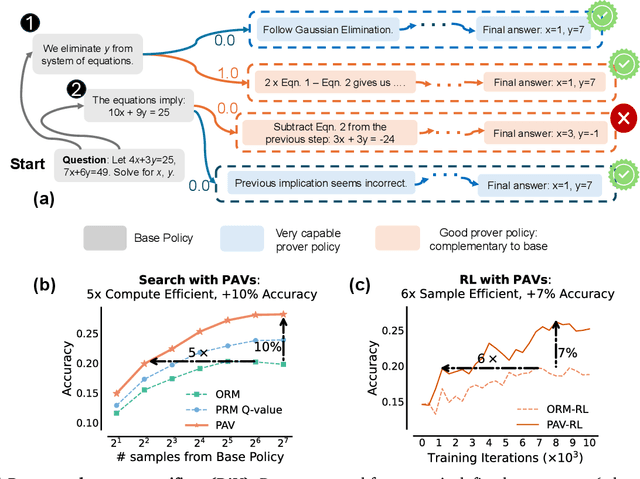
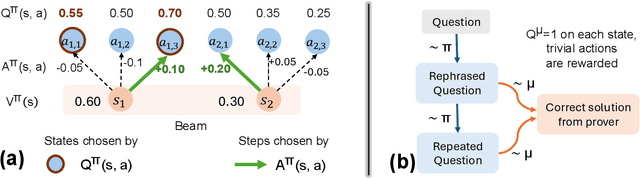
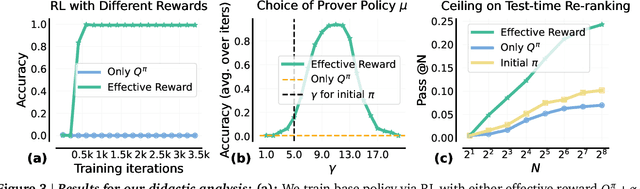
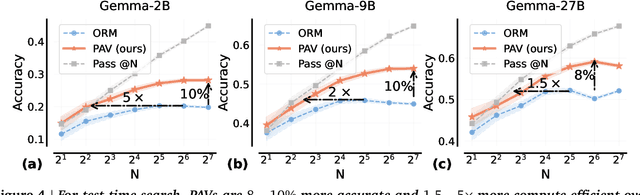
A promising approach for improving reasoning in large language models is to use process reward models (PRMs). PRMs provide feedback at each step of a multi-step reasoning trace, potentially improving credit assignment over outcome reward models (ORMs) that only provide feedback at the final step. However, collecting dense, per-step human labels is not scalable, and training PRMs from automatically-labeled data has thus far led to limited gains. To improve a base policy by running search against a PRM or using it as dense rewards for reinforcement learning (RL), we ask: "How should we design process rewards?". Our key insight is that, to be effective, the process reward for a step should measure progress: a change in the likelihood of producing a correct response in the future, before and after taking the step, corresponding to the notion of step-level advantages in RL. Crucially, this progress should be measured under a prover policy distinct from the base policy. We theoretically characterize the set of good provers and our results show that optimizing process rewards from such provers improves exploration during test-time search and online RL. In fact, our characterization shows that weak prover policies can substantially improve a stronger base policy, which we also observe empirically. We validate our claims by training process advantage verifiers (PAVs) to predict progress under such provers, and show that compared to ORMs, test-time search against PAVs is $>8\%$ more accurate, and $1.5-5\times$ more compute-efficient. Online RL with dense rewards from PAVs enables one of the first results with $5-6\times$ gain in sample efficiency, and $>6\%$ gain in accuracy, over ORMs.