 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-Aware Fine-Tuning for Best-of-N Sampling in Large Language Models
Dec 18, 2024
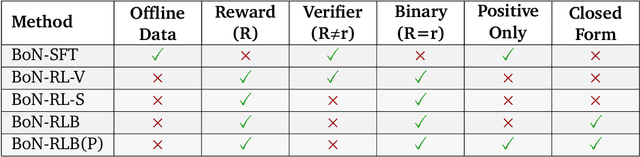
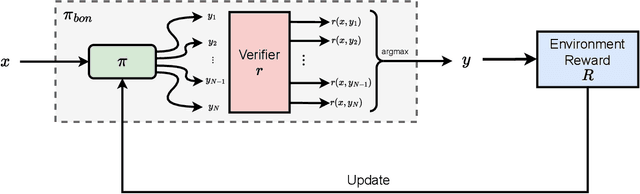
Recent studies have indicated that effectively utilizing inference-time compute is crucial for attaining better performance from large language models (LLMs). In this work, we propose a novel inference-aware fine-tuning paradigm, in which the model is fine-tuned in a manner that directly optimizes the performance of the inference-time strategy. We study this paradigm using the simple yet effective Best-of-N (BoN) inference strategy, in which a verifier selects the best out of a set of LLM-generated responses. We devise the first imitation learning and reinforcement learning~(RL) methods for BoN-aware fine-tuning, overcoming the challenging, non-differentiable argmax operator within BoN. We empirically demonstrate that our BoN-aware models implicitly learn a meta-strategy that interleaves best responses with more diverse responses that might be better suited to a test-time input -- a process reminiscent of the exploration-exploitation trade-off in RL. Our experiments demonstrate the effectiveness of BoN-aware fine-tuning in terms of improved performance and inference-time compute. In particular, we show that our methods improve the Bo32 performance of Gemma 2B on Hendrycks MATH from 26.8% to 30.8%, and pass@32 from 60.0% to 67.0%, as well as the pass@16 on HumanEval from 61.6% to 67.1%.
Finetuning Language Models to Emit Linguistic Expressions of Uncertainty
Sep 18, 2024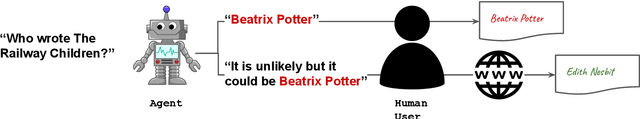

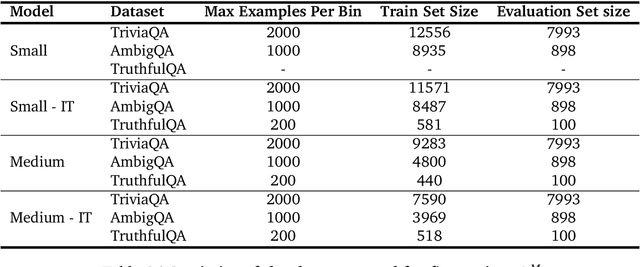
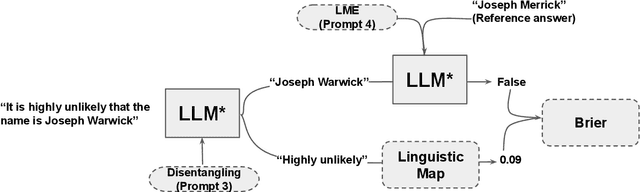
Large language models (LLMs) are increasingly employed in information-seeking and decision-making tasks. Despite their broad utility, LLMs tend to generate information that conflicts with real-world facts, and their persuasive style can make these inaccuracies appear confident and convincing. As a result, end-users struggle to consistently align the confidence expressed by LLMs with the accuracy of their predictions, often leading to either blind trust in all outputs or a complete disregard for their reliability. In this work, we explore supervised finetuning on uncertainty-augmented predictions as a method to develop models that produce linguistic expressions of uncertainty. Specifically, we measure the calibration of pre-trained models and then fine-tune language models to generate calibrated linguistic expressions of uncertainty. Through experiments on various question-answering datasets, we demonstrate that LLMs are well-calibrated in assessing their predictions, and supervised finetuning based on the model's own confidence leads to well-calibrated expressions of uncertainty, particularly for single-claim answers.
Sample Efficient Deep Reinforcement Learning via Local Planning
Jan 29, 2023



The focus of this work is sample-efficient deep reinforcement learning (RL) with a simulator. One useful property of simulators is that it is typically easy to reset the environment to a previously observed state. We propose an algorithmic framework, named uncertainty-first local planning (UFLP), that takes advantage of this property. Concretely, in each data collection iteration, with some probability, our meta-algorithm resets the environment to an observed state which has high uncertainty, instead of sampling according to the initial-state distribution. The agent-environment interaction then proceeds as in the standard online RL setting. We demonstrate that this simple procedure can dramatically improve the sample cost of several baseline RL algorithms on difficult exploration tasks. Notably, with our framework, we can achieve super-human performance on the notoriously hard Atari game, Montezuma's Revenge, with a simple (distributional) double DQN. Our work can be seen as an efficient approximate implementation of an existing algorithm with theoretical guarantees, which offers an interpretation of the positive empirical results.