 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinetuning Language Models to Emit Linguistic Expressions of Uncertainty
Paper and Code
Sep 18, 2024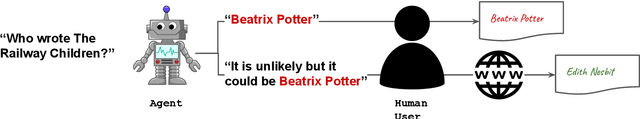

Large language models (LLMs) are increasingly employed in information-seeking and decision-making tasks. Despite their broad utility, LLMs tend to generate information that conflicts with real-world facts, and their persuasive style can make these inaccuracies appear confident and convincing. As a result, end-users struggle to consistently align the confidence expressed by LLMs with the accuracy of their predictions, often leading to either blind trust in all outputs or a complete disregard for their reliability. In this work, we explore supervised finetuning on uncertainty-augmented predictions as a method to develop models that produce linguistic expressions of uncertainty. Specifically, we measure the calibration of pre-trained models and then fine-tune language models to generate calibrated linguistic expressions of uncertainty. Through experiments on various question-answering datasets, we demonstrate that LLMs are well-calibrated in assessing their predictions, and supervised finetuning based on the model's own confidence leads to well-calibrated expressions of uncertainty, particularly for single-claim answers.