 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Latent Generalization Using Test-time Compute
Apr 01, 2026Language Models (LMs) exhibit two distinct mechanisms for knowledge acquisition: in-weights learning (i.e., encoding information within the model weights) and in-context learning (ICL). Although these two modes offer complementary strengths, in-weights learning frequently struggles to facilitate deductive reasoning over the internalized knowledge. We characterize this limitation as a deficit in latent generalization, of which the reversal curse is one example. Conversely, in-context learning demonstrates highly robust latent generalization capabilities. To improve latent generalization from in-weights knowledge, prior approaches rely on train-time data augmentation, yet these techniques are task-specific, scale poorly, and fail to generalize to out-of-distribution knowledge. To overcome these shortcomings, this work studies how models can be taught to use test-time compute, or 'thinking', specifically to improve latent generalization. We use Reinforcement Learning (RL) from correctness feedback to train models to produce long chains-of-thought (CoTs) to improve latent generalization. Our experiments show that this thinking approach not only resolves many instances of latent generalization failures on in-distribution knowledge but also, unlike augmentation baselines, generalizes to new knowledge for which no RL was performed. Nevertheless, on pure reversal tasks, we find that thinking does not unlock direct knowledge inversion, but the generate-and-verify ability of thinking models enables them to get well above chance performance. The brittleness of factual self-verification means thinking models still remain well below the performance of in-context learning for this task. Overall, our results establish test-time thinking as a flexible and promising direction for improving the latent generalization of LMs.
Latent learning: episodic memory complements parametric learning by enabling flexible reuse of experiences
Sep 19, 2025When do machine learning systems fail to generalize, and what mechanisms could improve their generalization? Here, we draw inspiration from cognitive science to argue that one weakness of machine learning systems is their failure to exhibit latent learning -- learning information that is not relevant to the task at hand, but that might be useful in a future task. We show how this perspective links failures ranging from the reversal curse in language modeling to new findings on agent-based navigation. We then highlight how cognitive science points to episodic memory as a potential part of the solution to these issues. Correspondingly, we show that a system with an oracle retrieval mechanism can use learning experiences more flexibly to generalize better across many of these challenges. We also identify some of the essential components for effectively using retrieval, including the importance of within-example in-context learning for acquiring the ability to use information across retrieved examples. In summary, our results illustrate one possible contributor to the relative data inefficiency of current machine learning systems compared to natural intelligence, and help to understand how retrieval methods can complement parametric learning to improve generalization.
On the generalization of language models from in-context learning and finetuning: a controlled study
May 01, 2025Large language models exhibit exciting capabilities, yet can show surprisingly narrow generalization from finetuning -- from failing to generalize to simple reversals of relations they are trained on, to missing logical deductions that can be made from trained information. These failures to generalize from fine-tuning can hinder practical application of these models. However, language models' in-context learning shows different inductive biases, and can generalize better in some of these cases. Here, we explore these differences in generalization between in-context- and fine-tuning-based learning. To do so, we constructed several novel datasets to evaluate and improve models' ability to generalize from finetuning data. The datasets are constructed to isolate the knowledge in the dataset from that in pretraining, to create clean tests of generalization. We expose pretrained large models to controlled subsets of the information in these datasets -- either in context, or through fine-tuning -- and evaluate their performance on test sets that require various types of generalization. We find overall that in data-matched settings, in-context learning can generalize more flexibly than fine-tuning (though we also find some qualifications of prior findings, such as cases when fine-tuning can generalize to reversals embedded in a larger structure of knowledge). We build on these findings to propose a method to enable improved generalization from fine-tuning: adding in-context inferences to finetuning data. We show that this method improves generalization across various splits of our datasets and other benchmarks. Our results have implications for understanding the inductive biases of different modes of learning in language models, and practically improving their performance.
Finetuning Language Models to Emit Linguistic Expressions of Uncertainty
Sep 18, 2024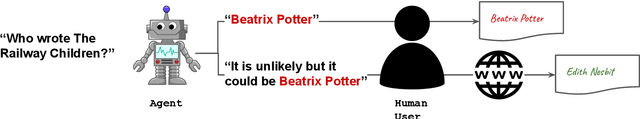

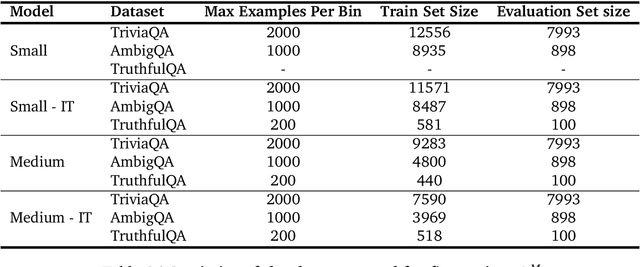
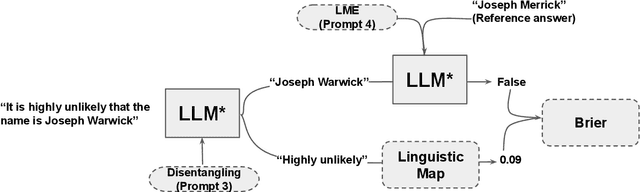
Large language models (LLMs) are increasingly employed in information-seeking and decision-making tasks. Despite their broad utility, LLMs tend to generate information that conflicts with real-world facts, and their persuasive style can make these inaccuracies appear confident and convincing. As a result, end-users struggle to consistently align the confidence expressed by LLMs with the accuracy of their predictions, often leading to either blind trust in all outputs or a complete disregard for their reliability. In this work, we explore supervised finetuning on uncertainty-augmented predictions as a method to develop models that produce linguistic expressions of uncertainty. Specifically, we measure the calibration of pre-trained models and then fine-tune language models to generate calibrated linguistic expressions of uncertainty. Through experiments on various question-answering datasets, we demonstrate that LLMs are well-calibrated in assessing their predictions, and supervised finetuning based on the model's own confidence leads to well-calibrated expressions of uncertainty, particularly for single-claim answers.
Is forgetting less a good inductive bias for forward transfer?
Mar 14, 2023



One of the main motivations of studying continual learning is that the problem setting allows a model to accrue knowledge from past tasks to learn new tasks more efficiently. However, recent studies suggest that the key metric that continual learning algorithms optimize, reduction in catastrophic forgetting, does not correlate well with the forward transfer of knowledge. We believe that the conclusion previous works reached is due to the way they measure forward transfer. We argue that the measure of forward transfer to a task should not be affected by the restrictions placed on the continual learner in order to preserve knowledge of previous tasks. Instead, forward transfer should be measured by how easy it is to learn a new task given a set of representations produced by continual learning on previous tasks. Under this notion of forward transfer, we evaluate different continual learning algorithms on a variety of image classification benchmarks. Our results indicate that less forgetful representations lead to a better forward transfer suggesting a strong correlation between retaining past information and learning efficiency on new tasks. Further, we found less forgetful representations to be more diverse and discriminative compared to their forgetful counterparts.
* Published as a conference paper at ICLR 2023
NEVIS'22: A Stream of 100 Tasks Sampled from 30 Years of Computer Vision Research
Nov 15, 2022We introduce the Never Ending VIsual-classification Stream (NEVIS'22), a benchmark consisting of a stream of over 100 visual classification tasks, sorted chronologically and extracted from papers sampled uniformly from computer vision proceedings spanning the last three decades. The resulting stream reflects what the research community thought was meaningful at any point in time. Despite being limited to classification, the resulting stream has a rich diversity of tasks from OCR, to texture analysis, crowd counting, scene recognition, and so forth. The diversity is also reflected in the wide range of dataset sizes, spanning over four orders of magnitude. Overall, NEVIS'22 poses an unprecedented challenge for current sequential learning approaches due to the scale and diversity of tasks, yet with a low entry barrier as it is limited to a single modality and each task is a classical supervised learning problem. Moreover, we provide a reference implementation including strong baselines and a simple evaluation protocol to compare methods in terms of their trade-off between accuracy and compute. We hope that NEVIS'22 can be useful to researchers working on continual learning, meta-learning, AutoML and more generally sequential learning, and help these communities join forces towards more robust and efficient models that efficiently adapt to a never ending stream of data. Implementations have been made available at https://github.com/deepmind/dm_nevis.
When does mixup promote local linearity in learned representations?
Oct 28, 2022



Mixup is a regularization technique that artificially produces new samples using convex combinations of original training points. This simple technique has shown strong empirical performance, and has been heavily used as part of semi-supervised learning techniques such as mixmatch~\citep{berthelot2019mixmatch} and interpolation consistent training (ICT)~\citep{verma2019interpolation}. In this paper, we look at Mixup through a \emph{representation learning} lens in a semi-supervised learning setup. In particular, we study the role of Mixup in promoting linearity in the learned network representations. Towards this, we study two questions: (1) how does the Mixup loss that enforces linearity in the \emph{last} network layer propagate the linearity to the \emph{earlier} layers?; and (2) how does the enforcement of stronger Mixup loss on more than two data points affect the convergence of training? We empirically investigate these properties of Mixup on vision datasets such as CIFAR-10, CIFAR-100 and SVHN. Our results show that supervised Mixup training does not make \emph{all} the network layers linear; in fact the \emph{intermediate layers} become more non-linear during Mixup training compared to a network that is trained \emph{without} Mixup. However, when Mixup is used as an unsupervised loss, we observe that all the network layers become more linear resulting in faster training convergence.
Architecture Matters in Continual Learning
Feb 01, 2022

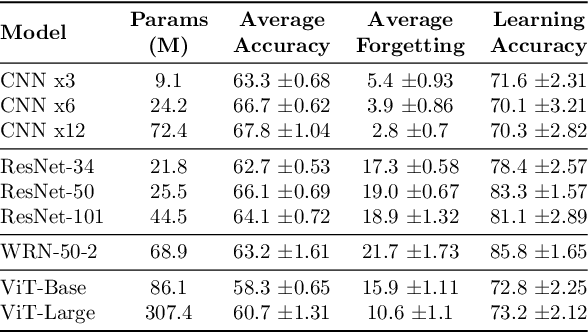

A large body of research in continual learning is devoted to overcoming the catastrophic forgetting of neural networks by designing new algorithms that are robust to the distribution shifts. However, the majority of these works are strictly focused on the "algorithmic" part of continual learning for a "fixed neural network architecture", and the implications of using different architectures are mostly neglected. Even the few existing continual learning methods that modify the model assume a fixed architecture and aim to develop an algorithm that efficiently uses the model throughout the learning experience. However, in this work, we show that the choice of architecture can significantly impact the continual learning performance, and different architectures lead to different trade-offs between the ability to remember previous tasks and learning new ones. Moreover, we study the impact of various architectural decisions, and our findings entail best practices and recommendations that can improve the continual learning performance.
Wide Neural Networks Forget Less Catastrophically
Oct 21, 2021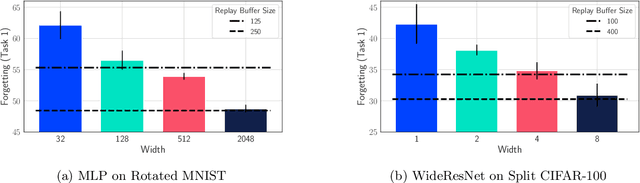
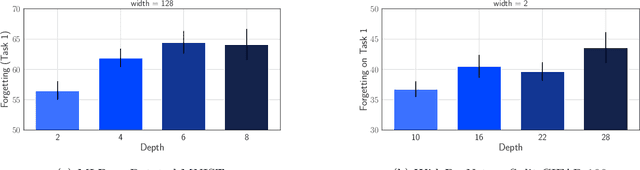
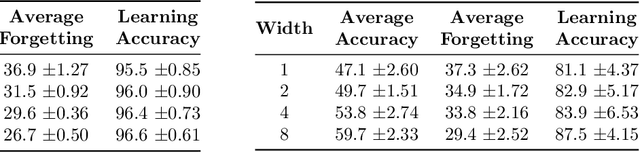
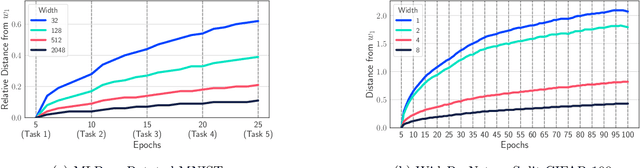
A growing body of research in continual learning is devoted to overcoming the "Catastrophic Forgetting" of neural networks by designing new algorithms that are more robust to the distribution shifts. While the recent progress in continual learning literature is encouraging, our understanding of what properties of neural networks contribute to catastrophic forgetting is still limited. To address this, instead of focusing on continual learning algorithms, in this work, we focus on the model itself and study the impact of "width" of the neural network architecture on catastrophic forgetting, and show that width has a surprisingly significant effect on forgetting. To explain this effect, we study the learning dynamics of the network from various perspectives such as gradient norm and sparsity, orthogonalization, and lazy training regime. We provide potential explanations that are consistent with the empirical results across different architectures and continual learning benchmarks.
Multilevel Knowledge Transfer for Cross-Domain Object Detection
Aug 03, 2021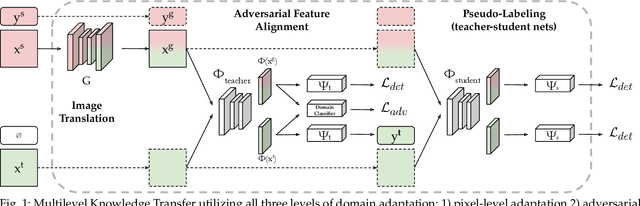
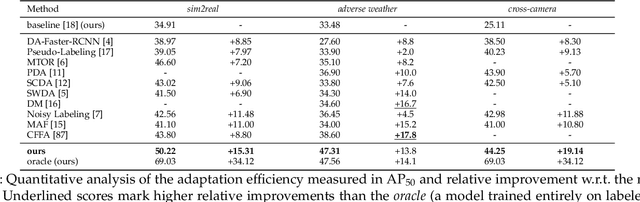
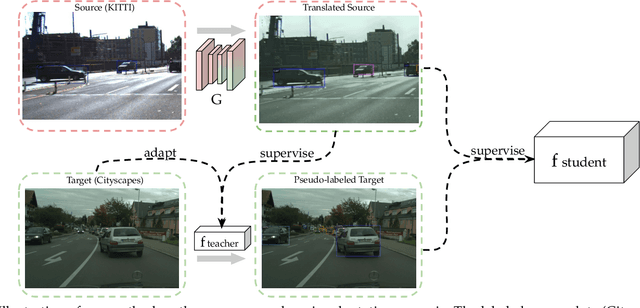
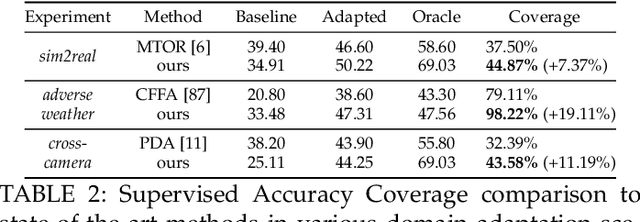
Domain shift is a well known problem where a model trained on a particular domain (source) does not perform well when exposed to samples from a different domain (target). Unsupervised methods that can adapt to domain shift are highly desirable as they allow effective utilization of the source data without requiring additional annotated training data from the target. Practically, obtaining sufficient amount of annotated data from the target domain can be both infeasible and extremely expensive. In this work, we address the domain shift problem for the object detection task. Our approach relies on gradually removing the domain shift between the source and the target domains. The key ingredients to our approach are -- (a) mapping the source to the target domain on pixel-level; (b) training a teacher network on the mapped source and the unannotated target domain using adversarial feature alignment; and (c) finally training a student network using the pseudo-labels obtained from the teacher. Experimentally, when tested on challenging scenarios involving domain shift, we consistently obtain significantly large performance gains over various recent state of the art approaches.