 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear representations in language models can change dramatically over a conversation
Jan 28, 2026Language model representations often contain linear directions that correspond to high-level concepts. Here, we study the dynamics of these representations: how representations evolve along these dimensions within the context of (simulated) conversations. We find that linear representations can change dramatically over a conversation; for example, information that is represented as factual at the beginning of a conversation can be represented as non-factual at the end and vice versa. These changes are content-dependent; while representations of conversation-relevant information may change, generic information is generally preserved. These changes are robust even for dimensions that disentangle factuality from more superficial response patterns, and occur across different model families and layers of the model. These representation changes do not require on-policy conversations; even replaying a conversation script written by an entirely different model can produce similar changes. However, adaptation is much weaker from simply having a sci-fi story in context that is framed more explicitly as such. We also show that steering along a representational direction can have dramatically different effects at different points in a conversation. These results are consistent with the idea that representations may evolve in response to the model playing a particular role that is cued by a conversation. Our findings may pose challenges for interpretability and steering -- in particular, they imply that it may be misleading to use static interpretations of features or directions, or probes that assume a particular range of features consistently corresponds to a particular ground-truth value. However, these types of representational dynamics also point to exciting new research directions for understanding how models adapt to context.
A Brain-like Synergistic Core in LLMs Drives Behaviour and Learning
Jan 11, 2026The independent evolution of intelligence in biological and artificial systems offers a unique opportunity to identify its fundamental computational principles. Here we show that large language models spontaneously develop synergistic cores -- components where information integration exceeds individual parts -- remarkably similar to those in the human brain. Using principles of information decomposition across multiple LLM model families and architectures, we find that areas in middle layers exhibit synergistic processing while early and late layers rely on redundancy, mirroring the informational organisation in biological brains. This organisation emerges through learning and is absent in randomly initialised networks. Crucially, ablating synergistic components causes disproportionate behavioural changes and performance loss, aligning with theoretical predictions about the fragility of synergy. Moreover, fine-tuning synergistic regions through reinforcement learning yields significantly greater performance gains than training redundant components, yet supervised fine-tuning shows no such advantage. This convergence suggests that synergistic information processing is a fundamental property of intelligence, providing targets for principled model design and testable predictions for biological intelligence.
The Xeno Sutra: Can Meaning and Value be Ascribed to an AI-Generated "Sacred" Text?
Jul 28, 2025

This paper presents a case study in the use of a large language model to generate a fictional Buddhist "sutr"', and offers a detailed analysis of the resulting text from a philosophical and literary point of view. The conceptual subtlety, rich imagery, and density of allusion found in the text make it hard to causally dismiss on account of its mechanistic origin. This raises questions about how we, as a society, should come to terms with the potentially unsettling possibility of a technology that encroaches on human meaning-making. We suggest that Buddhist philosophy, by its very nature, is well placed to adapt.
Does It Make Sense to Speak of Introspection in Large Language Models?
Jun 06, 2025Large language models (LLMs) exhibit compelling linguistic behaviour, and sometimes offer self-reports, that is to say statements about their own nature, inner workings, or behaviour. In humans, such reports are often attributed to a faculty of introspection and are typically linked to consciousness. This raises the question of how to interpret self-reports produced by LLMs, given their increasing linguistic fluency and cognitive capabilities. To what extent (if any) can the concept of introspection be meaningfully applied to LLMs? Here, we present and critique two examples of apparent introspective self-report from LLMs. In the first example, an LLM attempts to describe the process behind its own "creative" writing, and we argue this is not a valid example of introspection. In the second example, an LLM correctly infers the value of its own temperature parameter, and we argue that this can be legitimately considered a minimal example of introspection, albeit one that is (presumably) not accompanied by conscious experience.
On the generalization of language models from in-context learning and finetuning: a controlled study
May 01, 2025Large language models exhibit exciting capabilities, yet can show surprisingly narrow generalization from finetuning -- from failing to generalize to simple reversals of relations they are trained on, to missing logical deductions that can be made from trained information. These failures to generalize from fine-tuning can hinder practical application of these models. However, language models' in-context learning shows different inductive biases, and can generalize better in some of these cases. Here, we explore these differences in generalization between in-context- and fine-tuning-based learning. To do so, we constructed several novel datasets to evaluate and improve models' ability to generalize from finetuning data. The datasets are constructed to isolate the knowledge in the dataset from that in pretraining, to create clean tests of generalization. We expose pretrained large models to controlled subsets of the information in these datasets -- either in context, or through fine-tuning -- and evaluate their performance on test sets that require various types of generalization. We find overall that in data-matched settings, in-context learning can generalize more flexibly than fine-tuning (though we also find some qualifications of prior findings, such as cases when fine-tuning can generalize to reversals embedded in a larger structure of knowledge). We build on these findings to propose a method to enable improved generalization from fine-tuning: adding in-context inferences to finetuning data. We show that this method improves generalization across various splits of our datasets and other benchmarks. Our results have implications for understanding the inductive biases of different modes of learning in language models, and practically improving their performance.
Palatable Conceptions of Disembodied Being: Terra Incognita in the Space of Possible Minds
Mar 20, 2025Is it possible to articulate a conception of consciousness that is compatible with the exotic characteristics of contemporary, disembodied AI systems, and that can stand up to philosophical scrutiny? How would subjective time and selfhood show up for an entity that conformed to such a conception? Trying to answer these questions, even metaphorically, stretches the language of consciousness to breaking point. Ultimately, the attempt yields something like emptiness, in the Buddhist sense, and helps to undermine our dualistic inclinations towards subjectivity and selfhood.
Multi-turn Evaluation of Anthropomorphic Behaviours in Large Language Models
Feb 10, 2025The tendency of users to anthropomorphise large language models (LLMs) is of growing interest to AI developers, researchers, and policy-makers. Here, we present a novel method for empirically evaluating anthropomorphic LLM behaviours in realistic and varied settings. Going beyond single-turn static benchmarks, we contribute three methodological advances in state-of-the-art (SOTA) LLM evaluation. First, we develop a multi-turn evaluation of 14 anthropomorphic behaviours. Second, we present a scalable, automated approach by employing simulations of user interactions. Third, we conduct an interactive, large-scale human subject study (N=1101) to validate that the model behaviours we measure predict real users' anthropomorphic perceptions. We find that all SOTA LLMs evaluated exhibit similar behaviours, characterised by relationship-building (e.g., empathy and validation) and first-person pronoun use, and that the majority of behaviours only first occur after multiple turns. Our work lays an empirical foundation for investigating how design choices influence anthropomorphic model behaviours and for progressing the ethical debate on the desirability of these behaviours. It also showcases the necessity of multi-turn evaluations for complex social phenomena in human-AI interaction.
Transformers Use Causal World Models in Maze-Solving Tasks
Dec 16, 2024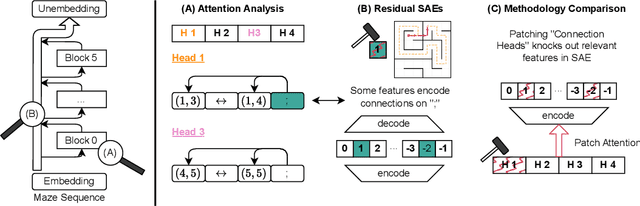



Recent studies in interpretability have explored the inner workings of transformer models trained on tasks across various domains, often discovering that these networks naturally develop surprisingly structured representations. When such representations comprehensively reflect the task domain's structure, they are commonly referred to as ``World Models'' (WMs). In this work, we discover such WMs in transformers trained on maze tasks. In particular, by employing Sparse Autoencoders (SAEs) and analysing attention patterns, we examine the construction of WMs and demonstrate consistency between the circuit analysis and the SAE feature-based analysis. We intervene upon the isolated features to confirm their causal role and, in doing so, find asymmetries between certain types of interventions. Surprisingly, we find that models are able to reason with respect to a greater number of active features than they see during training, even if attempting to specify these in the input token sequence would lead the model to fail. Futhermore, we observe that varying positional encodings can alter how WMs are encoded in a model's residual stream. By analyzing the causal role of these WMs in a toy domain we hope to make progress toward an understanding of emergent structure in the representations acquired by Transformers, leading to the development of more interpretable and controllable AI systems.
Still "Talking About Large Language Models": Some Clarifications
Dec 13, 2024My paper "Talking About Large Language Models" has more than once been interpreted as advocating a reductionist stance towards large language models. But the paper was not intended that way, and I do not endorse such positions. This short note situates the paper in the context of a larger philosophical project that is concerned with the (mis)use of words rather than metaphysics, in the spirit of Wittgenstein's later writing.
The broader spectrum of in-context learning
Dec 05, 2024

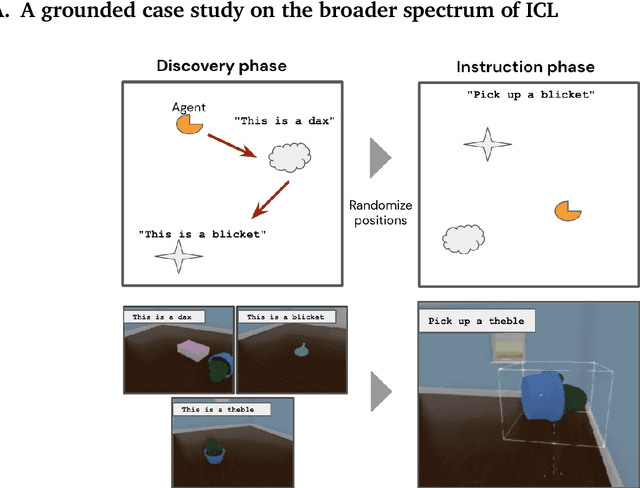
The ability of language models to learn a task from a few examples in context has generated substantial interest. Here, we provide a perspective that situates this type of supervised few-shot learning within a much broader spectrum of meta-learned in-context learning. Indeed, we suggest that any distribution of sequences in which context non-trivially decreases loss on subsequent predictions can be interpreted as eliciting a kind of in-context learning. We suggest that this perspective helps to unify the broad set of in-context abilities that language models exhibit $\unicode{x2014}$ such as adapting to tasks from instructions or role play, or extrapolating time series. This perspective also sheds light on potential roots of in-context learning in lower-level processing of linguistic dependencies (e.g. coreference or parallel structures). Finally, taking this perspective highlights the importance of generalization, which we suggest can be studied along several dimensions: not only the ability to learn something novel, but also flexibility in learning from different presentations, and in applying what is learned. We discuss broader connections to past literature in meta-learning and goal-conditioned agents, and other perspectives on learning and adaptation. We close by suggesting that research on in-context learning should consider this broader spectrum of in-context capabilities and types of generalization.