 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVET: A Framework for Analyzing AI Discourse
Jun 01, 2026Public discourse on AI has become polarized; exaggerated positions on AI in traditional and social media threaten the development of AI Literacy among the general public. In this article, I introduce the VET Framework, a method for categorizing AI discourse along the dimensions of valence, effectiveness, and trajectory. I show how this framework can be used to identify, compare, and critique prevalent narratives of AI Hype, AI Doom, AI Denial, and AI Normalcy. Using VET, I analyze how each of these four stances exaggerates some aspects of the current state and/or likely evolution of AI, and illustrate how the VET framework can serve as an AI Literacy tool by supporting the ``vetting'' of polarized AI discourse.
Measuring Progress Toward AGI: A Cognitive Framework
May 27, 2026Despite widespread discussion of AGI, there is no clear framework for measuring progress toward it. This ambiguity fuels subjective claims, makes it difficult to track progress, and risks hindering responsible governance. As a starting point to address this gap, we present a framework for understanding system capabilities in relation to human cognitive abilities. Drawing from decades of research in psychology, neuroscience, and cognitive science, we introduce a Cognitive Taxonomy that deconstructs general intelligence into 10 key cognitive faculties. We then propose a rigorous evaluation protocol in which a system's performance is measured across a suite of targeted, held-out cognitive tasks, generating a 'cognitive profile' that can be used to understand a system's strengths and weaknesses. We hope this framework will provide a practical roadmap and an initial step toward more rigorous, empirical evaluation of AGI.
Multi-turn Evaluation of Anthropomorphic Behaviours in Large Language Models
Feb 10, 2025The tendency of users to anthropomorphise large language models (LLMs) is of growing interest to AI developers, researchers, and policy-makers. Here, we present a novel method for empirically evaluating anthropomorphic LLM behaviours in realistic and varied settings. Going beyond single-turn static benchmarks, we contribute three methodological advances in state-of-the-art (SOTA) LLM evaluation. First, we develop a multi-turn evaluation of 14 anthropomorphic behaviours. Second, we present a scalable, automated approach by employing simulations of user interactions. Third, we conduct an interactive, large-scale human subject study (N=1101) to validate that the model behaviours we measure predict real users' anthropomorphic perceptions. We find that all SOTA LLMs evaluated exhibit similar behaviours, characterised by relationship-building (e.g., empathy and validation) and first-person pronoun use, and that the majority of behaviours only first occur after multiple turns. Our work lays an empirical foundation for investigating how design choices influence anthropomorphic model behaviours and for progressing the ethical debate on the desirability of these behaviours. It also showcases the necessity of multi-turn evaluations for complex social phenomena in human-AI interaction.
Generative Agent Simulations of 1,000 People
Nov 15, 2024



The promise of human behavioral simulation--general-purpose computational agents that replicate human behavior across domains--could enable broad applications in policymaking and social science. We present a novel agent architecture that simulates the attitudes and behaviors of 1,052 real individuals--applying large language models to qualitative interviews about their lives, then measuring how well these agents replicate the attitudes and behaviors of the individuals that they represent. The generative agents replicate participants' responses on the General Social Survey 85% as accurately as participants replicate their own answers two weeks later, and perform comparably in predicting personality traits and outcomes in experimental replications. Our architecture reduces accuracy biases across racial and ideological groups compared to agents given demographic descriptions. This work provides a foundation for new tools that can help investigate individual and collective behavior.
Towards Bidirectional Human-AI Alignment: A Systematic Review for Clarifications, Framework, and Future Directions
Jun 17, 2024Recent advancements in general-purpose AI have highlighted the importance of guiding AI systems towards the intended goals, ethical principles, and values of individuals and groups, a concept broadly recognized as alignment. However, the lack of clarified definitions and scopes of human-AI alignment poses a significant obstacle, hampering collaborative efforts across research domains to achieve this alignment. In particular, ML- and philosophy-oriented alignment research often views AI alignment as a static, unidirectional process (i.e., aiming to ensure that AI systems' objectives match humans) rather than an ongoing, mutual alignment problem [429]. This perspective largely neglects the long-term interaction and dynamic changes of alignment. To understand these gaps, we introduce a systematic review of over 400 papers published between 2019 and January 2024, spanning multiple domains such as Human-Computer Interaction (HCI), Natural Language Processing (NLP), Machine Learning (ML), and others. We characterize, define and scope human-AI alignment. From this, we present a conceptual framework of "Bidirectional Human-AI Alignment" to organize the literature from a human-centered perspective. This framework encompasses both 1) conventional studies of aligning AI to humans that ensures AI produces the intended outcomes determined by humans, and 2) a proposed concept of aligning humans to AI, which aims to help individuals and society adjust to AI advancements both cognitively and behaviorally. Additionally, we articulate the key findings derived from literature analysis, including discussions about human values, interaction techniques, and evaluations. To pave the way for future studies, we envision three key challenges for future directions and propose examples of potential future solutions.
Can Language Models Use Forecasting Strategies?
Jun 06, 2024



Advances in deep learning systems have allowed large models to match or surpass human accuracy on a number of skills such as image classification, basic programming, and standardized test taking. As the performance of the most capable models begin to saturate on tasks where humans already achieve high accuracy, it becomes necessary to benchmark models on increasingly complex abilities. One such task is forecasting the future outcome of events. In this work we describe experiments using a novel dataset of real world events and associated human predictions, an evaluation metric to measure forecasting ability, and the accuracy of a number of different LLM based forecasting designs on the provided dataset. Additionally, we analyze the performance of the LLM forecasters against human predictions and find that models still struggle to make accurate predictions about the future. Our follow-up experiments indicate this is likely due to models' tendency to guess that most events are unlikely to occur (which tends to be true for many prediction datasets, but does not reflect actual forecasting abilities). We reflect on next steps for developing a systematic and reliable approach to studying LLM forecasting.
Using Large Language Models to Accelerate Communication for Users with Severe Motor Impairments
Dec 03, 2023



Finding ways to accelerate text input for individuals with profound motor impairments has been a long-standing area of research. Closing the speed gap for augmentative and alternative communication (AAC) devices such as eye-tracking keyboards is important for improving the quality of life for such individuals. Recent advances in neural networks of natural language pose new opportunities for re-thinking strategies and user interfaces for enhanced text-entry for AAC users. In this paper, we present SpeakFaster, consisting of large language models (LLMs) and a co-designed user interface for text entry in a highly-abbreviated form, allowing saving 57% more motor actions than traditional predictive keyboards in offline simulation. A pilot study with 19 non-AAC participants typing on a mobile device by hand demonstrated gains in motor savings in line with the offline simulation, while introducing relatively small effects on overall typing speed. Lab and field testing on two eye-gaze typing users with amyotrophic lateral sclerosis (ALS) demonstrated text-entry rates 29-60% faster than traditional baselines, due to significant saving of expensive keystrokes achieved through phrase and word predictions from context-aware LLMs. These findings provide a strong foundation for further exploration of substantially-accelerated text communication for motor-impaired users and demonstrate a direction for applying LLMs to text-based user interfaces.
Levels of AGI: Operationalizing Progress on the Path to AGI
Nov 04, 2023

We propose a framework for classifying the capabilities and behavior of Artificial General Intelligence (AGI) models and their precursors. This framework introduces levels of AGI performance, generality, and autonomy. It is our hope that this framework will be useful in an analogous way to the levels of autonomous driving, by providing a common language to compare models, assess risks, and measure progress along the path to AGI. To develop our framework, we analyze existing definitions of AGI, and distill six principles that a useful ontology for AGI should satisfy. These principles include focusing on capabilities rather than mechanisms; separately evaluating generality and performance; and defining stages along the path toward AGI, rather than focusing on the endpoint. With these principles in mind, we propose 'Levels of AGI' based on depth (performance) and breadth (generality) of capabilities, and reflect on how current systems fit into this ontology. We discuss the challenging requirements for future benchmarks that quantify the behavior and capabilities of AGI models against these levels. Finally, we discuss how these levels of AGI interact with deployment considerations such as autonomy and risk, and emphasize the importance of carefully selecting Human-AI Interaction paradigms for responsible and safe deployment of highly capable AI systems.
AI Alignment in the Design of Interactive AI: Specification Alignment, Process Alignment, and Evaluation Support
Oct 23, 2023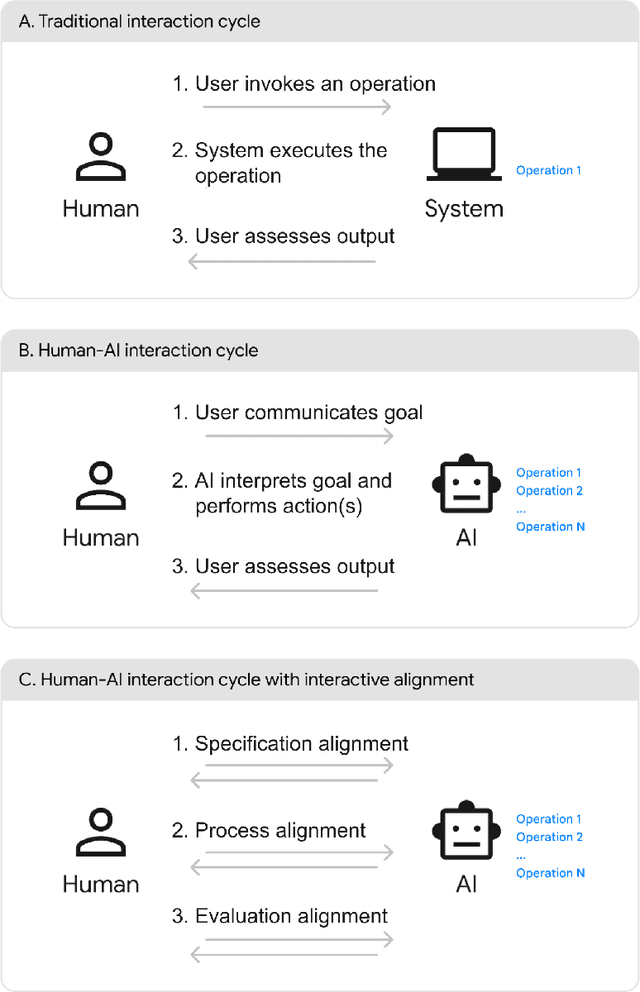
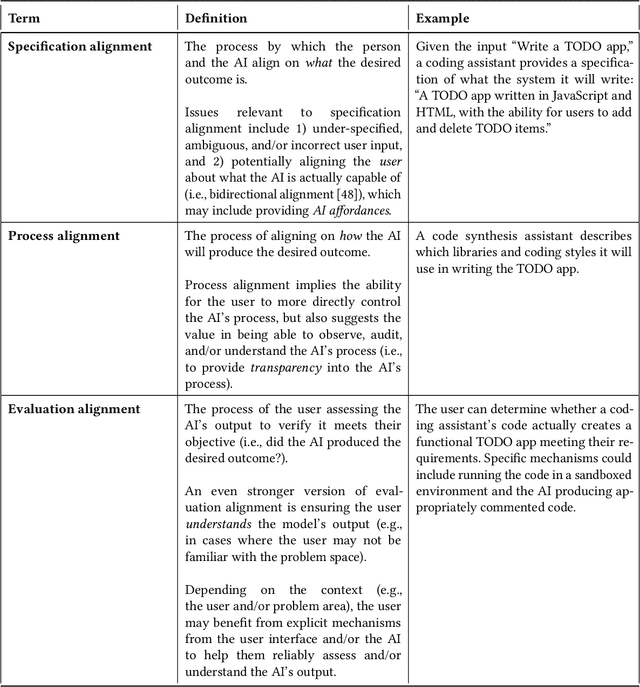
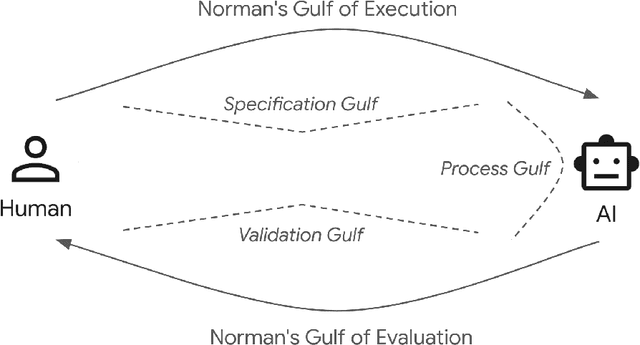
AI alignment considers the overall problem of ensuring an AI produces desired outcomes, without undesirable side effects. While often considered from the perspectives of safety and human values, AI alignment can also be considered in the context of designing and evaluating interfaces for interactive AI systems. This paper maps concepts from AI alignment onto a basic, three step interaction cycle, yielding a corresponding set of alignment objectives: 1) specification alignment: ensuring the user can efficiently and reliably communicate objectives to the AI, 2) process alignment: providing the ability to verify and optionally control the AI's execution process, and 3) evaluation support: ensuring the user can verify and understand the AI's output. We also introduce the concepts of a surrogate process, defined as a simplified, separately derived, but controllable representation of the AI's actual process; and the notion of a Process Gulf, which highlights how differences between human and AI processes can lead to challenges in AI control. To illustrate the value of this framework, we describe commercial and research systems along each of the three alignment dimensions, and show how interfaces that provide interactive alignment mechanisms can lead to qualitatively different and improved user experiences.
The Design Space of Generative Models
Apr 15, 2023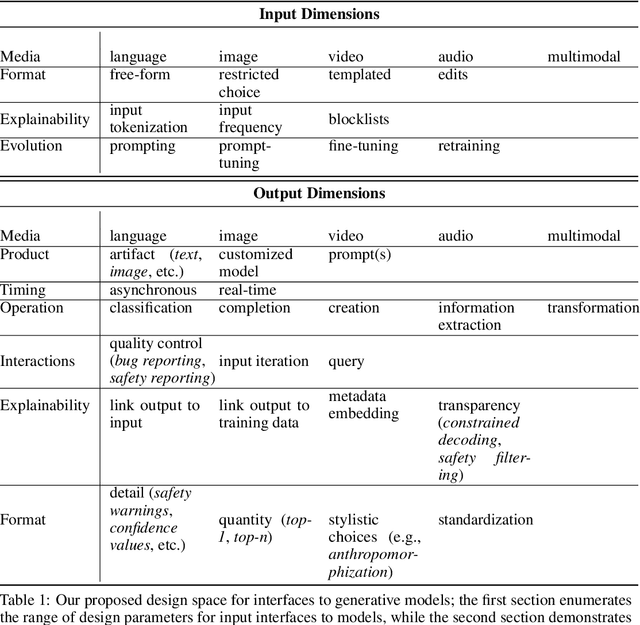
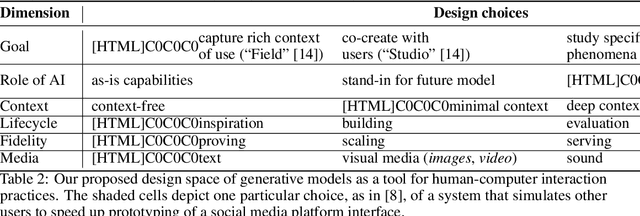
Card et al.'s classic paper "The Design Space of Input Devices" established the value of design spaces as a tool for HCI analysis and invention. We posit that developing design spaces for emerging pre-trained, generative AI models is necessary for supporting their integration into human-centered systems and practices. We explore what it means to develop an AI model design space by proposing two design spaces relating to generative AI models: the first considers how HCI can impact generative models (i.e., interfaces for models) and the second considers how generative models can impact HCI (i.e., models as an HCI prototyping material).