 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOLMoASR: Open Models and Data for Training Robust Speech Recognition Models
Aug 28, 2025Improvements in training data scale and quality have led to significant advances, yet its influence in speech recognition remains underexplored. In this paper, we present a large-scale dataset, OLMoASR-Pool, and series of models, OLMoASR, to study and develop robust zero-shot speech recognition models. Beginning from OLMoASR-Pool, a collection of 3M hours of English audio and 17M transcripts, we design text heuristic filters to remove low-quality or mistranscribed data. Our curation pipeline produces a new dataset containing 1M hours of high-quality audio-transcript pairs, which we call OLMoASR-Mix. We use OLMoASR-Mix to train the OLMoASR-Mix suite of models, ranging from 39M (tiny.en) to 1.5B (large.en) parameters. Across all model scales, OLMoASR achieves comparable average performance to OpenAI's Whisper on short and long-form speech recognition benchmarks. Notably, OLMoASR-medium.en attains a 12.8\% and 11.0\% word error rate (WER) that is on par with Whisper's largest English-only model Whisper-medium.en's 12.4\% and 10.5\% WER for short and long-form recognition respectively (at equivalent parameter count). OLMoASR-Pool, OLMoASR models, and filtering, training and evaluation code will be made publicly available to further research on robust speech processing.
OpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
DataComp-LM: In search of the next generation of training sets for language models
Jun 18, 2024



We introduce DataComp for Language Models (DCLM), a testbed for controlled dataset experiments with the goal of improving language models. As part of DCLM, we provide a standardized corpus of 240T tokens extracted from Common Crawl, effective pretraining recipes based on the OpenLM framework, and a broad suite of 53 downstream evaluations. Participants in the DCLM benchmark can experiment with data curation strategies such as deduplication, filtering, and data mixing at model scales ranging from 412M to 7B parameters. As a baseline for DCLM, we conduct extensive experiments and find that model-based filtering is key to assembling a high-quality training set. The resulting dataset, DCLM-Baseline enables training a 7B parameter language model from scratch to 64% 5-shot accuracy on MMLU with 2.6T training tokens. Compared to MAP-Neo, the previous state-of-the-art in open-data language models, DCLM-Baseline represents a 6.6 percentage point improvement on MMLU while being trained with 40% less compute. Our baseline model is also comparable to Mistral-7B-v0.3 and Llama 3 8B on MMLU (63% & 66%), and performs similarly on an average of 53 natural language understanding tasks while being trained with 6.6x less compute than Llama 3 8B. Our results highlight the importance of dataset design for training language models and offer a starting point for further research on data curation.
Can Language Models Use Forecasting Strategies?
Jun 06, 2024



Advances in deep learning systems have allowed large models to match or surpass human accuracy on a number of skills such as image classification, basic programming, and standardized test taking. As the performance of the most capable models begin to saturate on tasks where humans already achieve high accuracy, it becomes necessary to benchmark models on increasingly complex abilities. One such task is forecasting the future outcome of events. In this work we describe experiments using a novel dataset of real world events and associated human predictions, an evaluation metric to measure forecasting ability, and the accuracy of a number of different LLM based forecasting designs on the provided dataset. Additionally, we analyze the performance of the LLM forecasters against human predictions and find that models still struggle to make accurate predictions about the future. Our follow-up experiments indicate this is likely due to models' tendency to guess that most events are unlikely to occur (which tends to be true for many prediction datasets, but does not reflect actual forecasting abilities). We reflect on next steps for developing a systematic and reliable approach to studying LLM forecasting.
DataComp: In search of the next generation of multimodal datasets
May 03, 2023Large multimodal datasets have been instrumental in recent breakthroughs such as CLIP, Stable Diffusion, and GPT-4. At the same time, datasets rarely receive the same research attention as model architectures or training algorithms. To address this shortcoming in the machine learning ecosystem, we introduce DataComp, a benchmark where the training code is fixed and researchers innovate by proposing new training sets. We provide a testbed for dataset experiments centered around a new candidate pool of 12.8B image-text pairs from Common Crawl. Participants in our benchmark design new filtering techniques or curate new data sources and then evaluate their new dataset by running our standardized CLIP training code and testing on 38 downstream test sets. Our benchmark consists of multiple scales, with four candidate pool sizes and associated compute budgets ranging from 12.8M to 12.8B samples seen during training. This multi-scale design facilitates the study of scaling trends and makes the benchmark accessible to researchers with varying resources. Our baseline experiments show that the DataComp workflow is a promising way of improving multimodal datasets. We introduce DataComp-1B, a dataset created by applying a simple filtering algorithm to the 12.8B candidate pool. The resulting 1.4B subset enables training a CLIP ViT-L/14 from scratch to 79.2% zero-shot accuracy on ImageNet. Our new ViT-L/14 model outperforms a larger ViT-g/14 trained on LAION-2B by 0.7 percentage points while requiring 9x less training compute. We also outperform OpenAI's CLIP ViT-L/14 by 3.7 percentage points, which is trained with the same compute budget as our model. These gains highlight the potential for improving model performance by carefully curating training sets. We view DataComp-1B as only the first step and hope that DataComp paves the way toward the next generation of multimodal datasets.
What does a platypus look like? Generating customized prompts for zero-shot image classification
Sep 07, 2022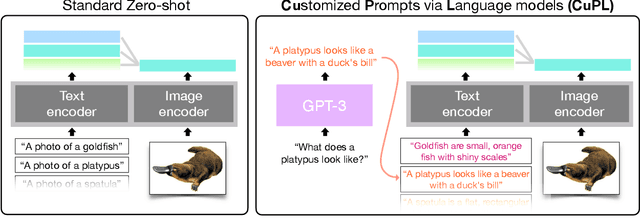
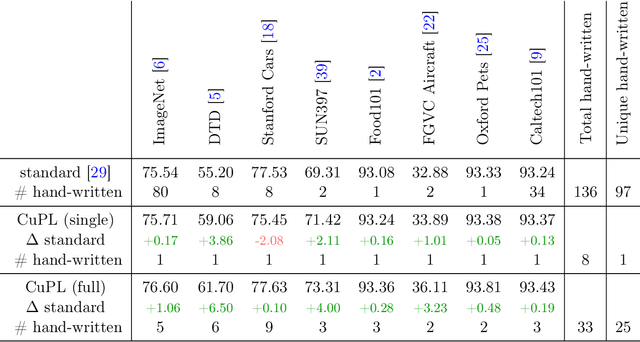
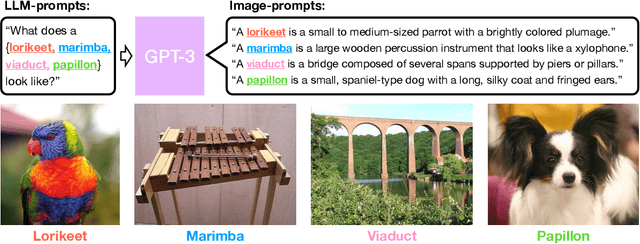
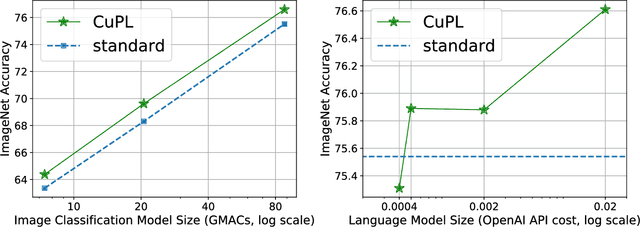
Open vocabulary models are a promising new paradigm for image classification. Unlike traditional classification models, open vocabulary models classify among any arbitrary set of categories specified with natural language during inference. This natural language, called "prompts", typically consists of a set of hand-written templates (e.g., "a photo of a {}") which are completed with each of the category names. This work introduces a simple method to generate higher accuracy prompts, without using explicit knowledge of the image domain and with far fewer hand-constructed sentences. To achieve this, we combine open vocabulary models with large language models (LLMs) to create Customized Prompts via Language models (CuPL, pronounced "couple"). In particular, we leverage the knowledge contained in LLMs in order to generate many descriptive sentences that are customized for each object category. We find that this straightforward and general approach improves accuracy on a range of zero-shot image classification benchmarks, including over one percentage point gain on ImageNet. Finally, this method requires no additional training and remains completely zero-shot. Code is available at https://github.com/sarahpratt/CuPL.
The Introspective Agent: Interdependence of Strategy, Physiology, and Sensing for Embodied Agents
Jan 02, 2022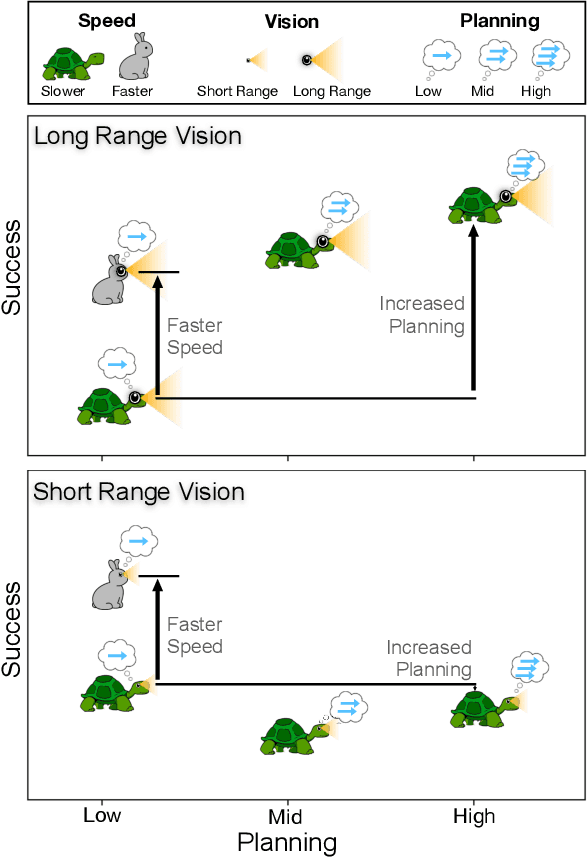
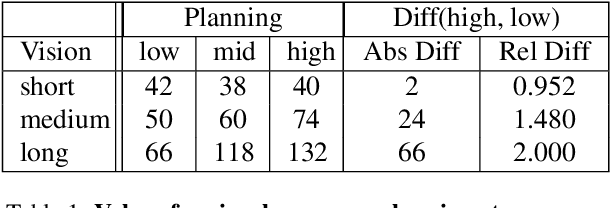
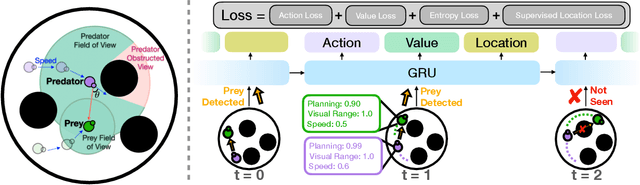

The last few years have witnessed substantial progress in the field of embodied AI where artificial agents, mirroring biological counterparts, are now able to learn from interaction to accomplish complex tasks. Despite this success, biological organisms still hold one large advantage over these simulated agents: adaptation. While both living and simulated agents make decisions to achieve goals (strategy), biological organisms have evolved to understand their environment (sensing) and respond to it (physiology). The net gain of these factors depends on the environment, and organisms have adapted accordingly. For example, in a low vision aquatic environment some fish have evolved specific neurons which offer a predictable, but incredibly rapid, strategy to escape from predators. Mammals have lost these reactive systems, but they have a much larger fields of view and brain circuitry capable of understanding many future possibilities. While traditional embodied agents manipulate an environment to best achieve a goal, we argue for an introspective agent, which considers its own abilities in the context of its environment. We show that different environments yield vastly different optimal designs, and increasing long-term planning is often far less beneficial than other improvements, such as increased physical ability. We present these findings to broaden the definition of improvement in embodied AI passed increasingly complex models. Just as in nature, we hope to reframe strategy as one tool, among many, to succeed in an environment. Code is available at: https://github.com/sarahpratt/introspective.
Grounded Situation Recognition
Mar 26, 2020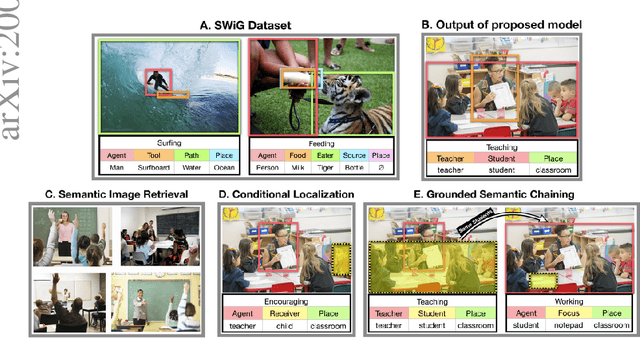
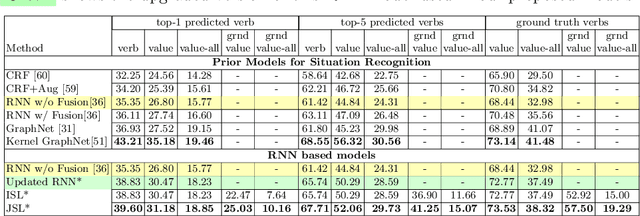
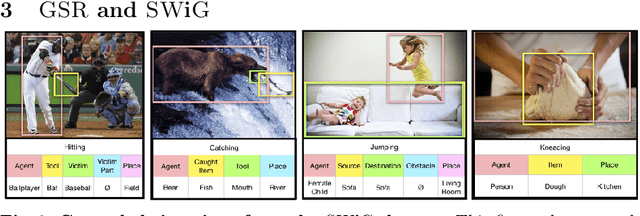

We introduce Grounded Situation Recognition (GSR), a task that requires producing structured semantic summaries of images describing: the primary activity, entities engaged in the activity with their roles (e.g. agent, tool), and bounding-box groundings of entities. GSR presents important technical challenges: identifying semantic saliency, categorizing and localizing a large and diverse set of entities, overcoming semantic sparsity, and disambiguating roles. Moreover, unlike in captioning, GSR is straightforward to evaluate. To study this new task we create the Situations With Groundings (SWiG) dataset which adds 278,336 bounding-box groundings to the 11,538 entity classes in the imsitu dataset. We propose a Joint Situation Localizer and find that jointly predicting situations and groundings with end-to-end training handily outperforms independent training on the entire grounding metric suite with relative gains between 8% and 32%. Finally, we show initial findings on three exciting future directions enabled by our models: conditional querying, visual chaining, and grounded semantic aware image retrieval. Code and data available at https://prior.allenai.org/projects/gsr.