 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLA Foundry: A Unified Framework for Training Vision-Language-Action Models
Apr 21, 2026We present VLA Foundry, an open-source framework that unifies LLM, VLM, and VLA training in a single codebase. Most open-source VLA efforts specialize on the action training stage, often stitching together incompatible pretraining pipelines. VLA Foundry instead provides a shared training stack with end-to-end control, from language pretraining to action-expert fine-tuning. VLA Foundry supports both from-scratch training and pretrained backbones from Hugging Face. To demonstrate the utility of our framework, we train and release two types of models: the first trained fully from scratch through our LLM-->VLM-->VLA pipeline and the second built on the pretrained Qwen3-VL backbone. We evaluate closed-loop policy performance of both models on LBM Eval, an open-data, open-source simulator. We also contribute usability improvements to the simulator and the STEP analysis tools for easier public use. In the nominal evaluation setting, our fully-open from-scratch model is on par with our prior closed-source work and substituting in the Qwen3-VL backbone leads to a strong multi-task table top manipulation policy outperforming our baseline by a wide margin. The VLA Foundry codebase is available at https://github.com/TRI-ML/vla_foundry and all multi-task model weights are released on https://huggingface.co/collections/TRI-ML/vla-foundry. Additional qualitative videos are available on the project website https://tri-ml.github.io/vla_foundry.
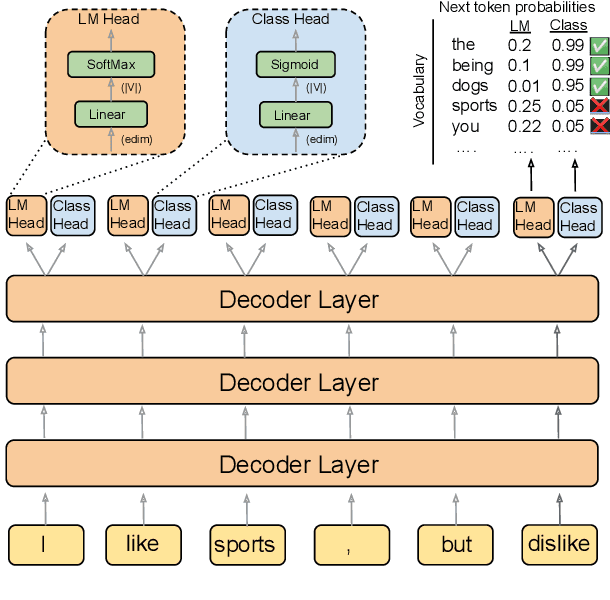
A Systematic Study of Data Modalities and Strategies for Co-training Large Behavior Models for Robot Manipulation
Feb 01, 2026Large behavior models have shown strong dexterous manipulation capabilities by extending imitation learning to large-scale training on multi-task robot data, yet their generalization remains limited by the insufficient robot data coverage. To expand this coverage without costly additional data collection, recent work relies on co-training: jointly learning from target robot data and heterogeneous data modalities. However, how different co-training data modalities and strategies affect policy performance remains poorly understood. We present a large-scale empirical study examining five co-training data modalities: standard vision-language data, dense language annotations for robot trajectories, cross-embodiment robot data, human videos, and discrete robot action tokens across single- and multi-phase training strategies. Our study leverages 4,000 hours of robot and human manipulation data and 50M vision-language samples to train vision-language-action policies. We evaluate 89 policies over 58,000 simulation rollouts and 2,835 real-world rollouts. Our results show that co-training with forms of vision-language and cross-embodiment robot data substantially improves generalization to distribution shifts, unseen tasks, and language following, while discrete action token variants yield no significant benefits. Combining effective modalities produces cumulative gains and enables rapid adaptation to unseen long-horizon dexterous tasks via fine-tuning. Training exclusively on robot data degrades the visiolinguistic understanding of the vision-language model backbone, while co-training with effective modalities restores these capabilities. Explicitly conditioning action generation on chain-of-thought traces learned from co-training data does not improve performance in our simulation benchmark. Together, these results provide practical guidance for building scalable generalist robot policies.
OpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
Should VLMs be Pre-trained with Image Data?
Mar 10, 2025Pre-trained LLMs that are further trained with image data perform well on vision-language tasks. While adding images during a second training phase effectively unlocks this capability, it is unclear how much of a gain or loss this two-step pipeline gives over VLMs which integrate images earlier into the training process. To investigate this, we train models spanning various datasets, scales, image-text ratios, and amount of pre-training done before introducing vision tokens. We then fine-tune these models and evaluate their downstream performance on a suite of vision-language and text-only tasks. We find that pre-training with a mixture of image and text data allows models to perform better on vision-language tasks while maintaining strong performance on text-only evaluations. On an average of 6 diverse tasks, we find that for a 1B model, introducing visual tokens 80% of the way through pre-training results in a 2% average improvement over introducing visual tokens to a fully pre-trained model.
DataComp-LM: In search of the next generation of training sets for language models
Jun 18, 2024



We introduce DataComp for Language Models (DCLM), a testbed for controlled dataset experiments with the goal of improving language models. As part of DCLM, we provide a standardized corpus of 240T tokens extracted from Common Crawl, effective pretraining recipes based on the OpenLM framework, and a broad suite of 53 downstream evaluations. Participants in the DCLM benchmark can experiment with data curation strategies such as deduplication, filtering, and data mixing at model scales ranging from 412M to 7B parameters. As a baseline for DCLM, we conduct extensive experiments and find that model-based filtering is key to assembling a high-quality training set. The resulting dataset, DCLM-Baseline enables training a 7B parameter language model from scratch to 64% 5-shot accuracy on MMLU with 2.6T training tokens. Compared to MAP-Neo, the previous state-of-the-art in open-data language models, DCLM-Baseline represents a 6.6 percentage point improvement on MMLU while being trained with 40% less compute. Our baseline model is also comparable to Mistral-7B-v0.3 and Llama 3 8B on MMLU (63% & 66%), and performs similarly on an average of 53 natural language understanding tasks while being trained with 6.6x less compute than Llama 3 8B. Our results highlight the importance of dataset design for training language models and offer a starting point for further research on data curation.
Linearizing Large Language Models
May 10, 2024



Linear transformers have emerged as a subquadratic-time alternative to softmax attention and have garnered significant interest due to their fixed-size recurrent state that lowers inference cost. However, their original formulation suffers from poor scaling and underperforms compute-matched transformers. Recent linear models such as RWKV and Mamba have attempted to address these shortcomings by proposing novel time-mixing and gating architectures, but pre-training large language models requires significant data and compute investments. Thus, the search for subquadratic architectures is limited by the availability of compute and quality pre-training datasets. As a cost-effective alternative to pre-training linear transformers, we propose Scalable UPtraining for Recurrent Attention (SUPRA). We present a method to uptrain existing large pre-trained transformers into Recurrent Neural Networks (RNNs) with a modest compute budget. This allows us to leverage the strong pre-training data and performance of existing transformer LLMs, while requiring 5% of the training cost. We find that our linearization technique leads to competitive performance on standard benchmarks, but we identify persistent in-context learning and long-context modeling shortfalls for even the largest linear models. Our code and models can be found at https://github.com/TRI-ML/linear_open_lm.
A Critical Evaluation of AI Feedback for Aligning Large Language Models
Feb 19, 2024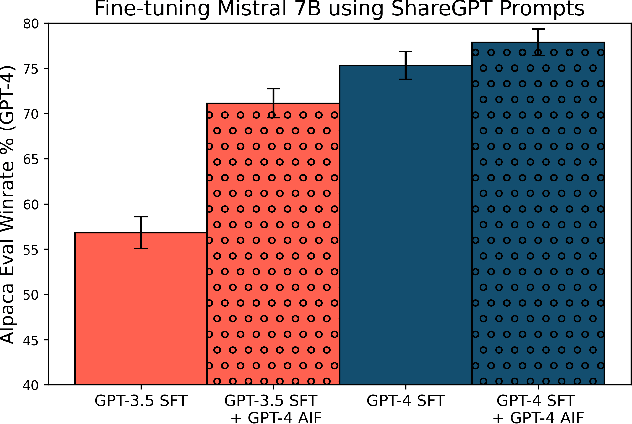

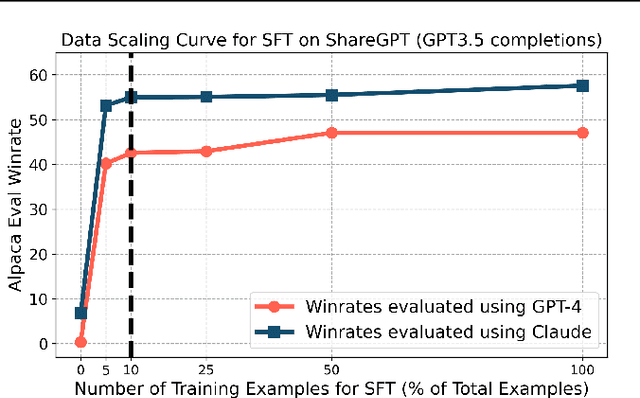
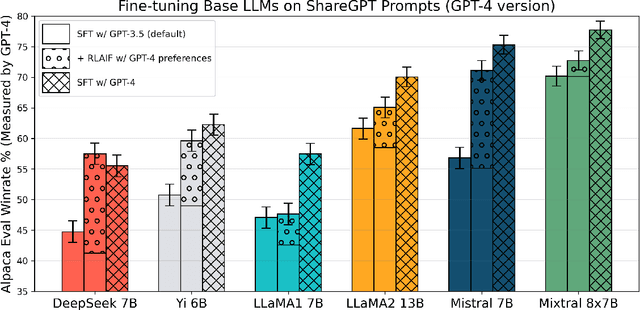
Reinforcement learning with AI feedback (RLAIF) is a popular paradigm for improving the instruction-following abilities of powerful pre-trained language models. RLAIF first performs supervised fine-tuning (SFT) using demonstrations from a teacher model and then further fine-tunes the model with reinforcement learning (RL), using feedback from a critic model. While recent popular open-source models have demonstrated substantial improvements in performance from the RL step, in this paper we question whether the complexity of this RL step is truly warranted for AI feedback. We show that the improvements of the RL step are virtually entirely due to the widespread practice of using a weaker teacher model (e.g. GPT-3.5) for SFT data collection than the critic (e.g., GPT-4) used for AI feedback generation. Specifically, we show that simple supervised fine-tuning with GPT-4 as the teacher outperforms existing RLAIF pipelines. More generally, we find that the gains from RLAIF vary substantially across base model families, test-time evaluation protocols, and critic models. Finally, we provide a mechanistic explanation for when SFT may outperform the full two-step RLAIF pipeline as well as suggestions for making RLAIF maximally useful in practice.
The Stable Entropy Hypothesis and Entropy-Aware Decoding: An Analysis and Algorithm for Robust Natural Language Generation
Feb 14, 2023



State-of-the-art language generation models can degenerate when applied to open-ended generation problems such as text completion, story generation, or dialog modeling. This degeneration usually shows up in the form of incoherence, lack of vocabulary diversity, and self-repetition or copying from the context. In this paper, we postulate that ``human-like'' generations usually lie in a narrow and nearly flat entropy band, and violation of these entropy bounds correlates with degenerate behavior. Our experiments show that this stable narrow entropy zone exists across models, tasks, and domains and confirm the hypothesis that violations of this zone correlate with degeneration. We then use this insight to propose an entropy-aware decoding algorithm that respects these entropy bounds resulting in less degenerate, more contextual, and "human-like" language generation in open-ended text generation settings.
Lexi: Self-Supervised Learning of the UI Language
Jan 23, 2023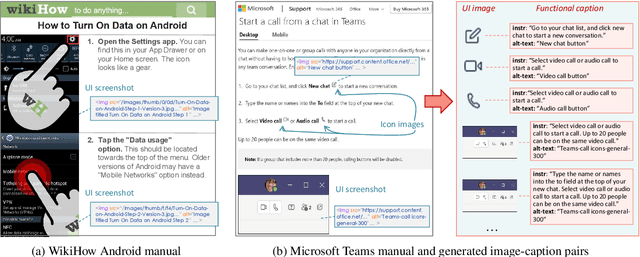

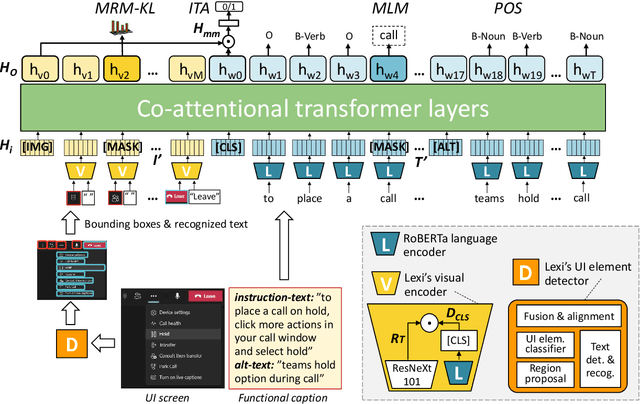

Humans can learn to operate the user interface (UI) of an application by reading an instruction manual or how-to guide. Along with text, these resources include visual content such as UI screenshots and images of application icons referenced in the text. We explore how to leverage this data to learn generic visio-linguistic representations of UI screens and their components. These representations are useful in many real applications, such as accessibility, voice navigation, and task automation. Prior UI representation models rely on UI metadata (UI trees and accessibility labels), which is often missing, incompletely defined, or not accessible. We avoid such a dependency, and propose Lexi, a pre-trained vision and language model designed to handle the unique features of UI screens, including their text richness and context sensitivity. To train Lexi we curate the UICaption dataset consisting of 114k UI images paired with descriptions of their functionality. We evaluate Lexi on four tasks: UI action entailment, instruction-based UI image retrieval, grounding referring expressions, and UI entity recognition.
Learning New Skills after Deployment: Improving open-domain internet-driven dialogue with human feedback
Aug 16, 2022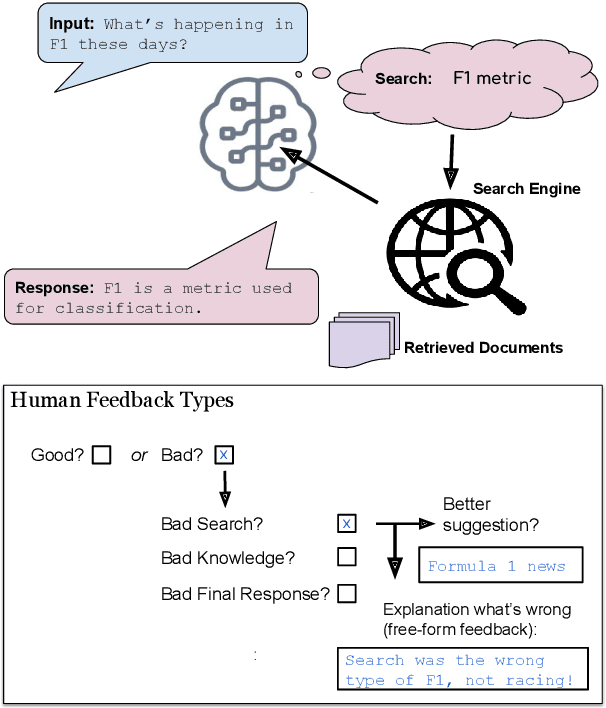
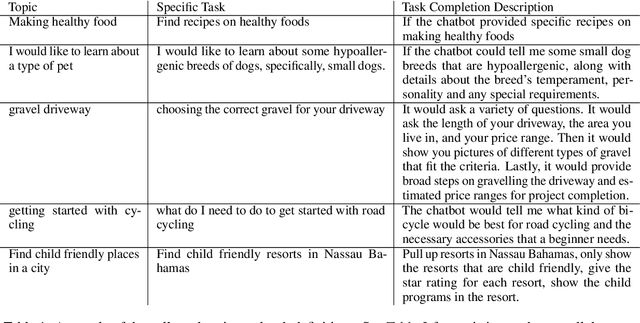
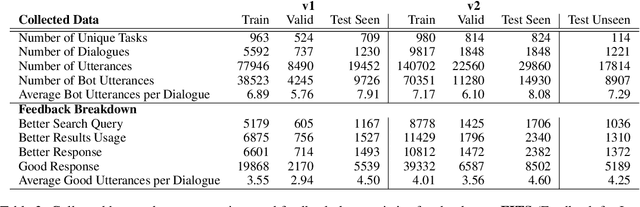
Frozen models trained to mimic static datasets can never improve their performance. Models that can employ internet-retrieval for up-to-date information and obtain feedback from humans during deployment provide the promise of both adapting to new information, and improving their performance. In this work we study how to improve internet-driven conversational skills in such a learning framework. We collect deployment data, which we make publicly available, of human interactions, and collect various types of human feedback -- including binary quality measurements, free-form text feedback, and fine-grained reasons for failure. We then study various algorithms for improving from such feedback, including standard supervised learning, rejection sampling, model-guiding and reward-based learning, in order to make recommendations on which type of feedback and algorithms work best. We find the recently introduced Director model (Arora et al., '22) shows significant improvements over other existing approaches.