 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining and Evaluating Diffusion Policies with Long Context Lengths
Jun 15, 2026Imitation learning has enabled highly-dexterous robotic manipulation from RGB observations. Policies trained with these methods, however, typically condition robot actions on only a short history of observations. These policies cannot solve tasks that require memory and can get stuck repeatedly executing the same failing motions. In this work, we first benchmark policy performance as context length is incrementally increased from short to long, across a spectrum of tasks with varying local stability and memory requirements, and in multiple data regimes. To our knowledge, this is the first study to investigate context length in imitation learning at this level of detail. Our results challenge prior claims: naively scaling context length is not as brittle as advertised in literature. With an appropriate conditioning method and denoising backbone (UNet+Cross-Attention), single-task policies achieve high success rates on many tasks in the usual data regime even with naive scaling. Next, we propose a training algorithm to jointly train policies at multiple context lengths, further reducing the sample complexity of long-context learning. Finally, we apply our findings to re-evaluate some previously proposed solutions to long-context imitation learning.
Semidefinite Relaxations for Collision-Free Motion Planning
Jun 12, 2026We study semidefinite relaxations for collision-free motion planning. We focus on a point robot moving from start to goal through spherical obstacles in $\mathbb{R}^n$, subject to path continuity constraints and squared derivative costs; a setting that is conceptually simple yet captures the hardness of collision-free motion planning. We formulate this problem exactly as a nonconvex problem over polynomial curves, and present a natural semidefinite relaxation. We contribute two key theoretical insights; to our knowledge this is the first theoretical analysis of semidefinite relaxations for collision-free motion planning. First, we show that solving the convex relaxation is equivalent to solving, to global optimality, a related motion planning problem in a potentially higher-dimensional space. This geometric interpretation yields necessary and sufficient conditions for tightness, and a clear intuition for when the relaxation is loose. Second, we show that the relaxation admits a symmetry reduction that makes it significantly smaller than one might expect, with positive semidefinite cone sizes that scale linearly with the polynomial degree and are independent of the ambient dimension. The resulting relaxation is 10 to 100 times faster than direct nonlinear programming transcriptions solved with SNOPT and IPOPT, exhibits significantly lower variance in solve times, and reliably finds a locally optimal path for the original problem. We demonstrate its effectiveness as a convex steering function in an RRT planner for minimum-snap quadrotor planning with $C^4$ continuous trajectories.
Ambient Diffusion Policy: Imitation Learning from Suboptimal Data in Robotics
Jun 10, 2026We propose Ambient Diffusion Policy, a simple and principled method for imitation learning from suboptimal data in robotics. High-quality, task-specific robot data is expensive and time-consuming to collect, while suboptimal datasets with lower-quality or out-of-distribution demonstrations are abundant. Existing methods that co-train on both data sources in robotics often fail to separate the meaningful and the harmful features in the suboptimal samples. In contrast, our method extracts only the useful features by introducing a new axis to co-training in robotics: noise-dependent data usage. Ambient Diffusion Policy restricts the contribution of suboptimal data during training to only the high and low diffusion times. To rigorously justify our approach, we first observe that robot action data exhibits a spectral power law. This induces two important properties on the optimal Diffusion Policy that we exploit: a global-to-local hierarchy and locality. We theoretically formalize this discussion using a simplified model. Our experiments validate Ambient Diffusion Policy on four types of suboptimal action data (noisy trajectories, sim-to-real gap, task mismatch, and large-scale data mixtures) across six tasks. The results show that it effectively learns from arbitrary sources of suboptimal data. Notably, it outperforms existing co-training baselines by up to 33% when scaled to Open X-Embodiment - a large dataset with heterogeneous data quality and unstructured distribution shifts. Overall, Ambient Diffusion Policy increases the utility of suboptimal demonstrations and expands the set of usable data sources in robotics.
SceneSmith: Agentic Generation of Simulation-Ready Indoor Scenes
Feb 09, 2026Simulation has become a key tool for training and evaluating home robots at scale, yet existing environments fail to capture the diversity and physical complexity of real indoor spaces. Current scene synthesis methods produce sparsely furnished rooms that lack the dense clutter, articulated furniture, and physical properties essential for robotic manipulation. We introduce SceneSmith, a hierarchical agentic framework that generates simulation-ready indoor environments from natural language prompts. SceneSmith constructs scenes through successive stages$\unicode{x2013}$from architectural layout to furniture placement to small object population$\unicode{x2013}$each implemented as an interaction among VLM agents: designer, critic, and orchestrator. The framework tightly integrates asset generation through text-to-3D synthesis for static objects, dataset retrieval for articulated objects, and physical property estimation. SceneSmith generates 3-6x more objects than prior methods, with <2% inter-object collisions and 96% of objects remaining stable under physics simulation. In a user study with 205 participants, it achieves 92% average realism and 91% average prompt faithfulness win rates against baselines. We further demonstrate that these environments can be used in an end-to-end pipeline for automatic robot policy evaluation.
A Framework for Combining Optimization-Based and Analytic Inverse Kinematics
Feb 04, 2026Analytic and optimization methods for solving inverse kinematics (IK) problems have been deeply studied throughout the history of robotics. The two strategies have complementary strengths and weaknesses, but developing a unified approach to take advantage of both methods has proved challenging. A key challenge faced by optimization approaches is the complicated nonlinear relationship between the joint angles and the end-effector pose. When this must be handled concurrently with additional nonconvex constraints like collision avoidance, optimization IK algorithms may suffer high failure rates. We present a new formulation for optimization IK that uses an analytic IK solution as a change of variables, and is fundamentally easier for optimizers to solve. We test our methodology on three popular solvers, representing three different paradigms for constrained nonlinear optimization. Extensive experimental comparisons demonstrate that our new formulation achieves higher success rates than the old formulation and baseline methods across various challenging IK problems, including collision avoidance, grasp selection, and humanoid stability.
Large Video Planner Enables Generalizable Robot Control
Dec 17, 2025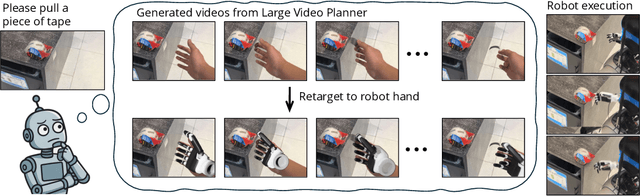
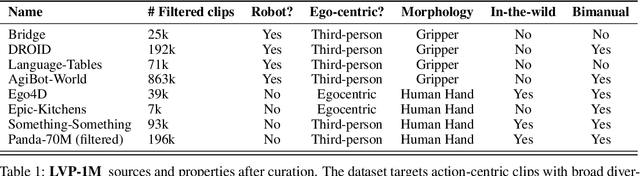
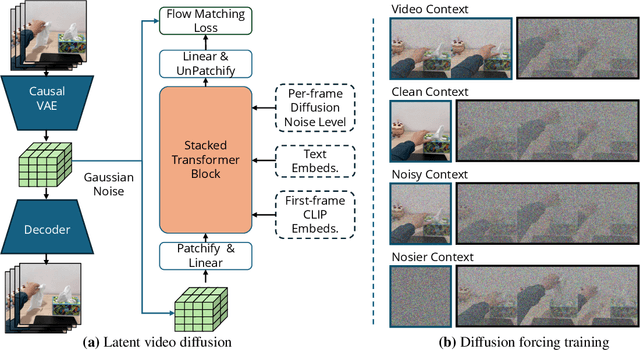

General-purpose robots require decision-making models that generalize across diverse tasks and environments. Recent works build robot foundation models by extending multimodal large language models (MLLMs) with action outputs, creating vision-language-action (VLA) systems. These efforts are motivated by the intuition that MLLMs' large-scale language and image pretraining can be effectively transferred to the action output modality. In this work, we explore an alternative paradigm of using large-scale video pretraining as a primary modality for building robot foundation models. Unlike static images and language, videos capture spatio-temporal sequences of states and actions in the physical world that are naturally aligned with robotic behavior. We curate an internet-scale video dataset of human activities and task demonstrations, and train, for the first time at a foundation-model scale, an open video model for generative robotics planning. The model produces zero-shot video plans for novel scenes and tasks, which we post-process to extract executable robot actions. We evaluate task-level generalization through third-party selected tasks in the wild and real-robot experiments, demonstrating successful physical execution. Together, these results show robust instruction following, strong generalization, and real-world feasibility. We release both the model and dataset to support open, reproducible video-based robot learning. Our website is available at https://www.boyuan.space/large-video-planner/.
How Well do Diffusion Policies Learn Kinematic Constraint Manifolds?
Oct 01, 2025Diffusion policies have shown impressive results in robot imitation learning, even for tasks that require satisfaction of kinematic equality constraints. However, task performance alone is not a reliable indicator of the policy's ability to precisely learn constraints in the training data. To investigate, we analyze how well diffusion policies discover these manifolds with a case study on a bimanual pick-and-place task that encourages fulfillment of a kinematic constraint for success. We study how three factors affect trained policies: dataset size, dataset quality, and manifold curvature. Our experiments show diffusion policies learn a coarse approximation of the constraint manifold with learning affected negatively by decreases in both dataset size and quality. On the other hand, the curvature of the constraint manifold showed inconclusive correlations with both constraint satisfaction and task success. A hardware evaluation verifies the applicability of our results in the real world. Project website with additional results and visuals: https://diffusion-learns-kinematic.github.io
Steerable Scene Generation with Post Training and Inference-Time Search
May 07, 2025Training robots in simulation requires diverse 3D scenes that reflect the specific challenges of downstream tasks. However, scenes that satisfy strict task requirements, such as high-clutter environments with plausible spatial arrangement, are rare and costly to curate manually. Instead, we generate large-scale scene data using procedural models that approximate realistic environments for robotic manipulation, and adapt it to task-specific goals. We do this by training a unified diffusion-based generative model that predicts which objects to place from a fixed asset library, along with their SE(3) poses. This model serves as a flexible scene prior that can be adapted using reinforcement learning-based post training, conditional generation, or inference-time search, steering generation toward downstream objectives even when they differ from the original data distribution. Our method enables goal-directed scene synthesis that respects physical feasibility and scales across scene types. We introduce a novel MCTS-based inference-time search strategy for diffusion models, enforce feasibility via projection and simulation, and release a dataset of over 44 million SE(3) scenes spanning five diverse environments. Website with videos, code, data, and model weights: https://steerable-scene-generation.github.io/
Dexterous Contact-Rich Manipulation via the Contact Trust Region
May 04, 2025What is a good local description of contact dynamics for contact-rich manipulation, and where can we trust this local description? While many approaches often rely on the Taylor approximation of dynamics with an ellipsoidal trust region, we argue that such approaches are fundamentally inconsistent with the unilateral nature of contact. As a remedy, we present the Contact Trust Region (CTR), which captures the unilateral nature of contact while remaining efficient for computation. With CTR, we first develop a Model-Predictive Control (MPC) algorithm capable of synthesizing local contact-rich plans. Then, we extend this capability to plan globally by stitching together local MPC plans, enabling efficient and dexterous contact-rich manipulation. To verify the performance of our method, we perform comprehensive evaluations, both in high-fidelity simulation and on hardware, on two contact-rich systems: a planar IiwaBimanual system and a 3D AllegroHand system. On both systems, our method offers a significantly lower-compute alternative to existing RL-based approaches to contact-rich manipulation. In particular, our Allegro in-hand manipulation policy, in the form of a roadmap, takes fewer than 10 minutes to build offline on a standard laptop using just its CPU, with online inference taking just a few seconds. Experiment data, video and code are available at ctr.theaiinstitute.com.
A New Semidefinite Relaxation for Linear and Piecewise-Affine Optimal Control with Time Scaling
Apr 17, 2025We introduce a semidefinite relaxation for optimal control of linear systems with time scaling. These problems are inherently nonconvex, since the system dynamics involves bilinear products between the discretization time step and the system state and controls. The proposed relaxation is closely related to the standard second-order semidefinite relaxation for quadratic constraints, but we carefully select a subset of the possible bilinear terms and apply a change of variables to achieve empirically tight relaxations while keeping the computational load light. We further extend our method to handle piecewise-affine (PWA) systems by formulating the PWA optimal-control problem as a shortest-path problem in a graph of convex sets (GCS). In this GCS, different paths represent different mode sequences for the PWA system, and the convex sets model the relaxed dynamics within each mode. By combining a tight convex relaxation of the GCS problem with our semidefinite relaxation with time scaling, we can solve PWA optimal-control problems through a single semidefinite program.