 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Study of Data Modalities and Strategies for Co-training Large Behavior Models for Robot Manipulation
Feb 01, 2026Large behavior models have shown strong dexterous manipulation capabilities by extending imitation learning to large-scale training on multi-task robot data, yet their generalization remains limited by the insufficient robot data coverage. To expand this coverage without costly additional data collection, recent work relies on co-training: jointly learning from target robot data and heterogeneous data modalities. However, how different co-training data modalities and strategies affect policy performance remains poorly understood. We present a large-scale empirical study examining five co-training data modalities: standard vision-language data, dense language annotations for robot trajectories, cross-embodiment robot data, human videos, and discrete robot action tokens across single- and multi-phase training strategies. Our study leverages 4,000 hours of robot and human manipulation data and 50M vision-language samples to train vision-language-action policies. We evaluate 89 policies over 58,000 simulation rollouts and 2,835 real-world rollouts. Our results show that co-training with forms of vision-language and cross-embodiment robot data substantially improves generalization to distribution shifts, unseen tasks, and language following, while discrete action token variants yield no significant benefits. Combining effective modalities produces cumulative gains and enables rapid adaptation to unseen long-horizon dexterous tasks via fine-tuning. Training exclusively on robot data degrades the visiolinguistic understanding of the vision-language model backbone, while co-training with effective modalities restores these capabilities. Explicitly conditioning action generation on chain-of-thought traces learned from co-training data does not improve performance in our simulation benchmark. Together, these results provide practical guidance for building scalable generalist robot policies.
OpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
Should VLMs be Pre-trained with Image Data?
Mar 10, 2025Pre-trained LLMs that are further trained with image data perform well on vision-language tasks. While adding images during a second training phase effectively unlocks this capability, it is unclear how much of a gain or loss this two-step pipeline gives over VLMs which integrate images earlier into the training process. To investigate this, we train models spanning various datasets, scales, image-text ratios, and amount of pre-training done before introducing vision tokens. We then fine-tune these models and evaluate their downstream performance on a suite of vision-language and text-only tasks. We find that pre-training with a mixture of image and text data allows models to perform better on vision-language tasks while maintaining strong performance on text-only evaluations. On an average of 6 diverse tasks, we find that for a 1B model, introducing visual tokens 80% of the way through pre-training results in a 2% average improvement over introducing visual tokens to a fully pre-trained model.
Espresso: High Compression For Rich Extraction From Videos for Your Vision-Language Model
Dec 06, 2024Most of the current vision-language models (VLMs) for videos struggle to understand videos longer than a few seconds. This is primarily due to the fact that they do not scale to utilizing a large number of frames. In order to address this limitation, we propose Espresso, a novel method that extracts and compresses spatial and temporal information separately. Through extensive evaluations, we show that spatial and temporal compression in Espresso each have a positive impact on the long-form video understanding capabilities; when combined, their positive impact increases. Furthermore, we show that Espresso's performance scales well with more training data, and that Espresso is far more effective than the existing projectors for VLMs in long-form video understanding. Moreover, we devise a more difficult evaluation setting for EgoSchema called "needle-in-a-haystack" that multiplies the lengths of the input videos. Espresso achieves SOTA performance on this task, outperforming the SOTA VLMs that have been trained on much more training data.
DataComp-LM: In search of the next generation of training sets for language models
Jun 18, 2024



We introduce DataComp for Language Models (DCLM), a testbed for controlled dataset experiments with the goal of improving language models. As part of DCLM, we provide a standardized corpus of 240T tokens extracted from Common Crawl, effective pretraining recipes based on the OpenLM framework, and a broad suite of 53 downstream evaluations. Participants in the DCLM benchmark can experiment with data curation strategies such as deduplication, filtering, and data mixing at model scales ranging from 412M to 7B parameters. As a baseline for DCLM, we conduct extensive experiments and find that model-based filtering is key to assembling a high-quality training set. The resulting dataset, DCLM-Baseline enables training a 7B parameter language model from scratch to 64% 5-shot accuracy on MMLU with 2.6T training tokens. Compared to MAP-Neo, the previous state-of-the-art in open-data language models, DCLM-Baseline represents a 6.6 percentage point improvement on MMLU while being trained with 40% less compute. Our baseline model is also comparable to Mistral-7B-v0.3 and Llama 3 8B on MMLU (63% & 66%), and performs similarly on an average of 53 natural language understanding tasks while being trained with 6.6x less compute than Llama 3 8B. Our results highlight the importance of dataset design for training language models and offer a starting point for further research on data curation.
Linearizing Large Language Models
May 10, 2024



Linear transformers have emerged as a subquadratic-time alternative to softmax attention and have garnered significant interest due to their fixed-size recurrent state that lowers inference cost. However, their original formulation suffers from poor scaling and underperforms compute-matched transformers. Recent linear models such as RWKV and Mamba have attempted to address these shortcomings by proposing novel time-mixing and gating architectures, but pre-training large language models requires significant data and compute investments. Thus, the search for subquadratic architectures is limited by the availability of compute and quality pre-training datasets. As a cost-effective alternative to pre-training linear transformers, we propose Scalable UPtraining for Recurrent Attention (SUPRA). We present a method to uptrain existing large pre-trained transformers into Recurrent Neural Networks (RNNs) with a modest compute budget. This allows us to leverage the strong pre-training data and performance of existing transformer LLMs, while requiring 5% of the training cost. We find that our linearization technique leads to competitive performance on standard benchmarks, but we identify persistent in-context learning and long-context modeling shortfalls for even the largest linear models. Our code and models can be found at https://github.com/TRI-ML/linear_open_lm.
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
Language models scale reliably with over-training and on downstream tasks
Mar 13, 2024



Scaling laws are useful guides for developing language models, but there are still gaps between current scaling studies and how language models are ultimately trained and evaluated. For instance, scaling is usually studied in the compute-optimal training regime (i.e., "Chinchilla optimal" regime); however, in practice, models are often over-trained to reduce inference costs. Moreover, scaling laws mostly predict loss on next-token prediction, but ultimately models are compared based on downstream task performance. In this paper, we address both shortcomings. To do so, we create a testbed of 104 models with 0.011B to 6.9B parameters trained with various numbers of tokens on three data distributions. First, we investigate scaling in the over-trained regime. We fit scaling laws that extrapolate in both the number of model parameters and the ratio of training tokens to parameters. This enables us to predict the validation loss of a 1.4B parameter, 900B token run (i.e., 32$\times$ over-trained) and a 6.9B parameter, 138B token run$\unicode{x2014}$each from experiments that take 300$\times$ less compute. Second, we relate the perplexity of a language model to its downstream task performance via a power law. We use this law to predict top-1 error averaged over downstream tasks for the two aforementioned models using experiments that take 20$\times$ less compute. Our experiments are available at https://github.com/mlfoundations/scaling.
Residual Q-Learning: Offline and Online Policy Customization without Value
Jun 15, 2023



Imitation Learning (IL) is a widely used framework for learning imitative behavior from demonstrations. It is especially appealing for solving complex real-world tasks where handcrafting reward function is difficult, or when the goal is to mimic human expert behavior. However, the learned imitative policy can only follow the behavior in the demonstration. When applying the imitative policy, we may need to customize the policy behavior to meet different requirements coming from diverse downstream tasks. Meanwhile, we still want the customized policy to maintain its imitative nature. To this end, we formulate a new problem setting called policy customization. It defines the learning task as training a policy that inherits the characteristics of the prior policy while satisfying some additional requirements imposed by a target downstream task. We propose a novel and principled approach to interpret and determine the trade-off between the two task objectives. Specifically, we formulate the customization problem as a Markov Decision Process (MDP) with a reward function that combines 1) the inherent reward of the demonstration; and 2) the add-on reward specified by the downstream task. We propose a novel framework, Residual Q-learning, which can solve the formulated MDP by leveraging the prior policy without knowing the inherent reward or value function of the prior policy. We derive a family of residual Q-learning algorithms that can realize offline and online policy customization, and show that the proposed algorithms can effectively accomplish policy customization tasks in various environments.
RAP: Risk-Aware Prediction for Robust Planning
Oct 04, 2022
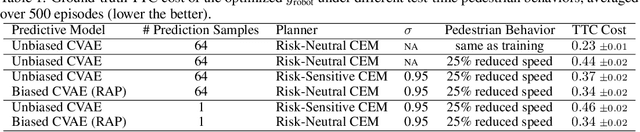
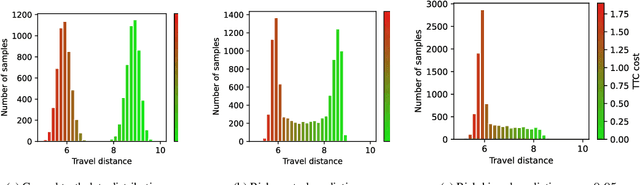
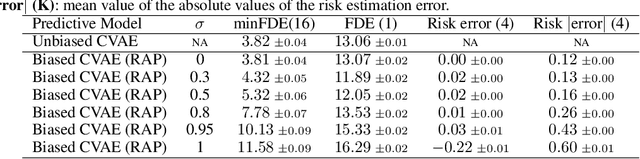
Robust planning in interactive scenarios requires predicting the uncertain future to make risk-aware decisions. Unfortunately, due to long-tail safety-critical events, the risk is often under-estimated by finite-sampling approximations of probabilistic motion forecasts. This can lead to overconfident and unsafe robot behavior, even with robust planners. Instead of assuming full prediction coverage that robust planners require, we propose to make prediction itself risk-aware. We introduce a new prediction objective to learn a risk-biased distribution over trajectories, so that risk evaluation simplifies to an expected cost estimation under this biased distribution. This reduces the sample complexity of the risk estimation during online planning, which is needed for safe real-time performance. Evaluation results in a didactic simulation environment and on a real-world dataset demonstrate the effectiveness of our approach.