 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
A Taxonomy for Evaluating Generalist Robot Policies
Mar 03, 2025


Machine learning for robotics promises to unlock generalization to novel tasks and environments. Guided by this promise, many recent works have focused on scaling up robot data collection and developing larger, more expressive policies to achieve this. But how do we measure progress towards this goal of policy generalization in practice? Evaluating and quantifying generalization is the Wild West of modern robotics, with each work proposing and measuring different types of generalization in their own, often difficult to reproduce, settings. In this work, our goal is (1) to outline the forms of generalization we believe are important in robot manipulation in a comprehensive and fine-grained manner, and (2) to provide reproducible guidelines for measuring these notions of generalization. We first propose STAR-Gen, a taxonomy of generalization for robot manipulation structured around visual, semantic, and behavioral generalization. We discuss how our taxonomy encompasses most prior notions of generalization in robotics. Next, we instantiate STAR-Gen with a concrete real-world benchmark based on the widely-used Bridge V2 dataset. We evaluate a variety of state-of-the-art models on this benchmark to demonstrate the utility of our taxonomy in practice. Our taxonomy of generalization can yield many interesting insights into existing models: for example, we observe that current vision-language-action models struggle with various types of semantic generalization, despite the promise of pre-training on internet-scale language datasets. We believe STAR-Gen and our guidelines can improve the dissemination and evaluation of progress towards generalization in robotics, which we hope will guide model design and future data collection efforts. We provide videos and demos at our website stargen-taxonomy.github.io.
The Ingredients for Robotic Diffusion Transformers
Oct 14, 2024In recent years roboticists have achieved remarkable progress in solving increasingly general tasks on dexterous robotic hardware by leveraging high capacity Transformer network architectures and generative diffusion models. Unfortunately, combining these two orthogonal improvements has proven surprisingly difficult, since there is no clear and well-understood process for making important design choices. In this paper, we identify, study and improve key architectural design decisions for high-capacity diffusion transformer policies. The resulting models can efficiently solve diverse tasks on multiple robot embodiments, without the excruciating pain of per-setup hyper-parameter tuning. By combining the results of our investigation with our improved model components, we are able to present a novel architecture, named \method, that significantly outperforms the state of the art in solving long-horizon ($1500+$ time-steps) dexterous tasks on a bi-manual ALOHA robot. In addition, we find that our policies show improved scaling performance when trained on 10 hours of highly multi-modal, language annotated ALOHA demonstration data. We hope this work will open the door for future robot learning techniques that leverage the efficiency of generative diffusion modeling with the scalability of large scale transformer architectures. Code, robot dataset, and videos are available at: https://dit-policy.github.io
Scaling Cross-Embodied Learning: One Policy for Manipulation, Navigation, Locomotion and Aviation
Aug 21, 2024



Modern machine learning systems rely on large datasets to attain broad generalization, and this often poses a challenge in robot learning, where each robotic platform and task might have only a small dataset. By training a single policy across many different kinds of robots, a robot learning method can leverage much broader and more diverse datasets, which in turn can lead to better generalization and robustness. However, training a single policy on multi-robot data is challenging because robots can have widely varying sensors, actuators, and control frequencies. We propose CrossFormer, a scalable and flexible transformer-based policy that can consume data from any embodiment. We train CrossFormer on the largest and most diverse dataset to date, 900K trajectories across 20 different robot embodiments. We demonstrate that the same network weights can control vastly different robots, including single and dual arm manipulation systems, wheeled robots, quadcopters, and quadrupeds. Unlike prior work, our model does not require manual alignment of the observation or action spaces. Extensive experiments in the real world show that our method matches the performance of specialist policies tailored for each embodiment, while also significantly outperforming the prior state of the art in cross-embodiment learning.
HRP: Human Affordances for Robotic Pre-Training
Jul 26, 2024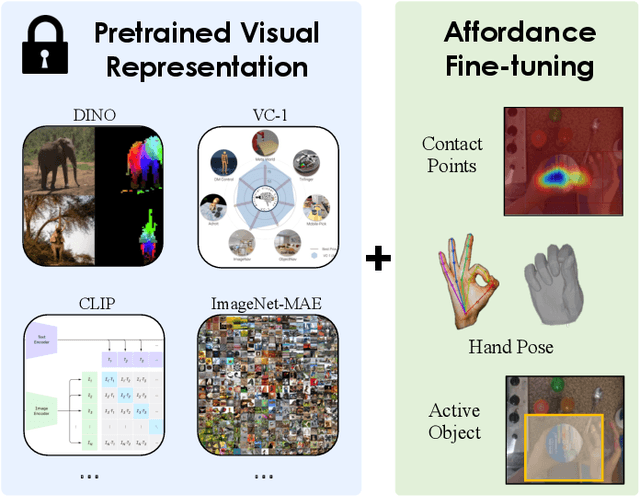
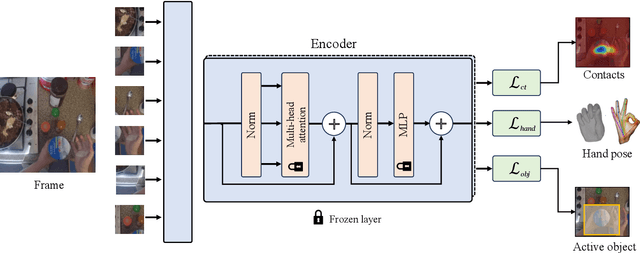
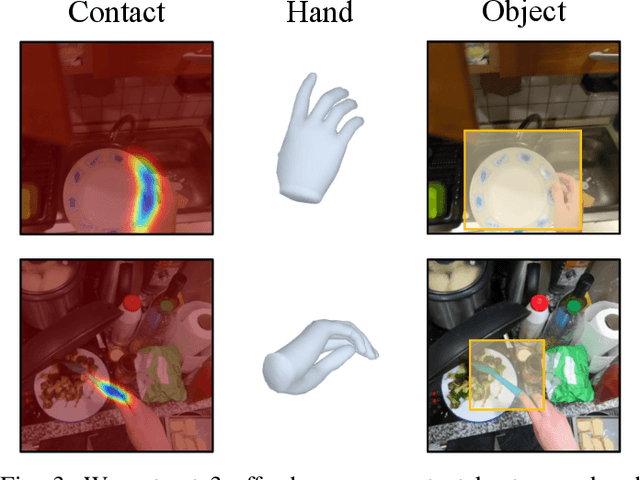
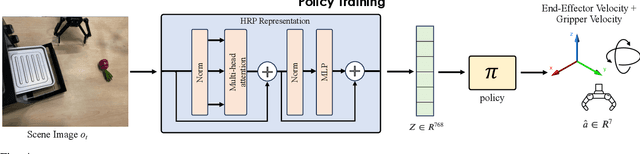
In order to *generalize* to various tasks in the wild, robotic agents will need a suitable representation (i.e., vision network) that enables the robot to predict optimal actions given high dimensional vision inputs. However, learning such a representation requires an extreme amount of diverse training data, which is prohibitively expensive to collect on a real robot. How can we overcome this problem? Instead of collecting more robot data, this paper proposes using internet-scale, human videos to extract "affordances," both at the environment and agent level, and distill them into a pre-trained representation. We present a simple framework for pre-training representations on hand, object, and contact "affordance labels" that highlight relevant objects in images and how to interact with them. These affordances are automatically extracted from human video data (with the help of off-the-shelf computer vision modules) and used to fine-tune existing representations. Our approach can efficiently fine-tune *any* existing representation, and results in models with stronger downstream robotic performance across the board. We experimentally demonstrate (using 3000+ robot trials) that this affordance pre-training scheme boosts performance by a minimum of 15% on 5 real-world tasks, which consider three diverse robot morphologies (including a dexterous hand). Unlike prior works in the space, these representations improve performance across 3 different camera views. Quantitatively, we find that our approach leads to higher levels of generalization in out-of-distribution settings. For code, weights, and data check: https://hrp-robot.github.io
Octo: An Open-Source Generalist Robot Policy
May 20, 2024



Large policies pretrained on diverse robot datasets have the potential to transform robotic learning: instead of training new policies from scratch, such generalist robot policies may be finetuned with only a little in-domain data, yet generalize broadly. However, to be widely applicable across a range of robotic learning scenarios, environments, and tasks, such policies need to handle diverse sensors and action spaces, accommodate a variety of commonly used robotic platforms, and finetune readily and efficiently to new domains. In this work, we aim to lay the groundwork for developing open-source, widely applicable, generalist policies for robotic manipulation. As a first step, we introduce Octo, a large transformer-based policy trained on 800k trajectories from the Open X-Embodiment dataset, the largest robot manipulation dataset to date. It can be instructed via language commands or goal images and can be effectively finetuned to robot setups with new sensory inputs and action spaces within a few hours on standard consumer GPUs. In experiments across 9 robotic platforms, we demonstrate that Octo serves as a versatile policy initialization that can be effectively finetuned to new observation and action spaces. We also perform detailed ablations of design decisions for the Octo model, from architecture to training data, to guide future research on building generalist robot models.
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
An Unbiased Look at Datasets for Visuo-Motor Pre-Training
Oct 13, 2023Visual representation learning hold great promise for robotics, but is severely hampered by the scarcity and homogeneity of robotics datasets. Recent works address this problem by pre-training visual representations on large-scale but out-of-domain data (e.g., videos of egocentric interactions) and then transferring them to target robotics tasks. While the field is heavily focused on developing better pre-training algorithms, we find that dataset choice is just as important to this paradigm's success. After all, the representation can only learn the structures or priors present in the pre-training dataset. To this end, we flip the focus on algorithms, and instead conduct a dataset centric analysis of robotic pre-training. Our findings call into question some common wisdom in the field. We observe that traditional vision datasets (like ImageNet, Kinetics and 100 Days of Hands) are surprisingly competitive options for visuo-motor representation learning, and that the pre-training dataset's image distribution matters more than its size. Finally, we show that common simulation benchmarks are not a reliable proxy for real world performance and that simple regularization strategies can dramatically improve real world policy learning. https://data4robotics.github.io
MyoDex: A Generalizable Prior for Dexterous Manipulation
Sep 06, 2023



Human dexterity is a hallmark of motor control. Our hands can rapidly synthesize new behaviors despite the complexity (multi-articular and multi-joints, with 23 joints controlled by more than 40 muscles) of musculoskeletal sensory-motor circuits. In this work, we take inspiration from how human dexterity builds on a diversity of prior experiences, instead of being acquired through a single task. Motivated by this observation, we set out to develop agents that can build upon their previous experience to quickly acquire new (previously unattainable) behaviors. Specifically, our approach leverages multi-task learning to implicitly capture task-agnostic behavioral priors (MyoDex) for human-like dexterity, using a physiologically realistic human hand model - MyoHand. We demonstrate MyoDex's effectiveness in few-shot generalization as well as positive transfer to a large repertoire of unseen dexterous manipulation tasks. Agents leveraging MyoDex can solve approximately 3x more tasks, and 4x faster in comparison to a distillation baseline. While prior work has synthesized single musculoskeletal control behaviors, MyoDex is the first generalizable manipulation prior that catalyzes the learning of dexterous physiological control across a large variety of contact-rich behaviors. We also demonstrate the effectiveness of our paradigms beyond musculoskeletal control towards the acquisition of dexterity in 24 DoF Adroit Hand. Website: https://sites.google.com/view/myodex