 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-learning with Adjoint Matching
Jan 20, 2026We propose Q-learning with Adjoint Matching (QAM), a novel TD-based reinforcement learning (RL) algorithm that tackles a long-standing challenge in continuous-action RL: efficient optimization of an expressive diffusion or flow-matching policy with respect to a parameterized Q-function. Effective optimization requires exploiting the first-order information of the critic, but it is challenging to do so for flow or diffusion policies because direct gradient-based optimization via backpropagation through their multi-step denoising process is numerically unstable. Existing methods work around this either by only using the value and discarding the gradient information, or by relying on approximations that sacrifice policy expressivity or bias the learned policy. QAM sidesteps both of these challenges by leveraging adjoint matching, a recently proposed technique in generative modeling, which transforms the critic's action gradient to form a step-wise objective function that is free from unstable backpropagation, while providing an unbiased, expressive policy at the optimum. Combined with temporal-difference backup for critic learning, QAM consistently outperforms prior approaches on hard, sparse reward tasks in both offline and offline-to-online RL.
RoboReward: General-Purpose Vision-Language Reward Models for Robotics
Jan 08, 2026A well-designed reward is critical for effective reinforcement learning-based policy improvement. In real-world robotics, obtaining such rewards typically requires either labor-intensive human labeling or brittle, handcrafted objectives. Vision-language models (VLMs) have shown promise as automatic reward models, yet their effectiveness on real robot tasks is poorly understood. In this work, we aim to close this gap by introducing (1) RoboReward, a robotics reward dataset and benchmark built on large-scale real-robot corpora from Open X-Embodiment (OXE) and RoboArena, and (2) vision-language reward models trained on this dataset (RoboReward 4B/8B). Because OXE is success-heavy and lacks failure examples, we propose a negative examples data augmentation pipeline that generates calibrated negative and near-misses via counterfactual relabeling of successful episodes and temporal clipping to create partial-progress outcomes from the same videos. Using this framework, we build a large training and evaluation dataset spanning diverse tasks and embodiments to test whether state-of-the-art VLMs can reliably provide rewards for robot learning. Our evaluation of open and proprietary VLMs finds that no model excels across tasks, highlighting substantial room for improvement. We then train general-purpose 4B- and 8B-parameter models that outperform much larger VLMs in assigning rewards for short-horizon robotic tasks. Finally, we deploy the 8B model in real-robot reinforcement learning and find that it improves policy learning over Gemini Robotics-ER 1.5 while narrowing the gap to RL training with human-provided rewards. We release the full dataset, trained reward models, and evaluation suite on our website to advance the development of general-purpose reward models in robotics: https://crfm.stanford.edu/helm/robo-reward-bench (project website).
Emergence of Human to Robot Transfer in Vision-Language-Action Models
Dec 27, 2025Vision-language-action (VLA) models can enable broad open world generalization, but require large and diverse datasets. It is appealing to consider whether some of this data can come from human videos, which cover diverse real-world situations and are easy to obtain. However, it is difficult to train VLAs with human videos alone, and establishing a mapping between humans and robots requires manual engineering and presents a major research challenge. Drawing inspiration from advances in large language models, where the ability to learn from diverse supervision emerges with scale, we ask whether a similar phenomenon holds for VLAs that incorporate human video data. We introduce a simple co-training recipe, and find that human-to-robot transfer emerges once the VLA is pre-trained on sufficient scenes, tasks, and embodiments. Our analysis suggests that this emergent capability arises because diverse pretraining produces embodiment-agnostic representations for human and robot data. We validate these findings through a series of experiments probing human to robot skill transfer and find that with sufficiently diverse robot pre-training our method can nearly double the performance on generalization settings seen only in human data.
PolaRiS: Scalable Real-to-Sim Evaluations for Generalist Robot Policies
Dec 18, 2025A significant challenge for robot learning research is our ability to accurately measure and compare the performance of robot policies. Benchmarking in robotics is historically challenging due to the stochasticity, reproducibility, and time-consuming nature of real-world rollouts. This challenge is exacerbated for recent generalist policies, which has to be evaluated across a wide variety of scenes and tasks. Evaluation in simulation offers a scalable complement to real world evaluations, but the visual and physical domain gap between existing simulation benchmarks and the real world has made them an unreliable signal for policy improvement. Furthermore, building realistic and diverse simulated environments has traditionally required significant human effort and expertise. To bridge the gap, we introduce Policy Evaluation and Environment Reconstruction in Simulation (PolaRiS), a scalable real-to-sim framework for high-fidelity simulated robot evaluation. PolaRiS utilizes neural reconstruction methods to turn short video scans of real-world scenes into interactive simulation environments. Additionally, we develop a simple simulation data co-training recipe that bridges remaining real-to-sim gaps and enables zero-shot evaluation in unseen simulation environments. Through extensive paired evaluations between simulation and the real world, we demonstrate that PolaRiS evaluations provide a much stronger correlation to real world generalist policy performance than existing simulated benchmarks. Its simplicity also enables rapid creation of diverse simulated environments. As such, this work takes a step towards distributed and democratized evaluation for the next generation of robotic foundation models.
Posterior Behavioral Cloning: Pretraining BC Policies for Efficient RL Finetuning
Dec 18, 2025Standard practice across domains from robotics to language is to first pretrain a policy on a large-scale demonstration dataset, and then finetune this policy, typically with reinforcement learning (RL), in order to improve performance on deployment domains. This finetuning step has proved critical in achieving human or super-human performance, yet while much attention has been given to developing more effective finetuning algorithms, little attention has been given to ensuring the pretrained policy is an effective initialization for RL finetuning. In this work we seek to understand how the pretrained policy affects finetuning performance, and how to pretrain policies in order to ensure they are effective initializations for finetuning. We first show theoretically that standard behavioral cloning (BC) -- which trains a policy to directly match the actions played by the demonstrator -- can fail to ensure coverage over the demonstrator's actions, a minimal condition necessary for effective RL finetuning. We then show that if, instead of exactly fitting the observed demonstrations, we train a policy to model the posterior distribution of the demonstrator's behavior given the demonstration dataset, we do obtain a policy that ensures coverage over the demonstrator's actions, enabling more effective finetuning. Furthermore, this policy -- which we refer to as the posterior behavioral cloning (PostBC) policy -- achieves this while ensuring pretrained performance is no worse than that of the BC policy. We then show that PostBC is practically implementable with modern generative models in robotic control domains -- relying only on standard supervised learning -- and leads to significantly improved RL finetuning performance on both realistic robotic control benchmarks and real-world robotic manipulation tasks, as compared to standard behavioral cloning.
Robust Finetuning of Vision-Language-Action Robot Policies via Parameter Merging
Dec 18, 2025Generalist robot policies, trained on large and diverse datasets, have demonstrated the ability to generalize across a wide spectrum of behaviors, enabling a single policy to act in varied real-world environments. However, they still fall short on new tasks not covered in the training data. When finetuned on limited demonstrations of a new task, these policies often overfit to the specific demonstrations--not only losing their prior abilities to solve a wide variety of generalist tasks but also failing to generalize within the new task itself. In this work, we aim to develop a method that preserves the generalization capabilities of the generalist policy during finetuning, allowing a single policy to robustly incorporate a new skill into its repertoire. Our goal is a single policy that both learns to generalize to variations of the new task and retains the broad competencies gained from pretraining. We show that this can be achieved through a simple yet effective strategy: interpolating the weights of a finetuned model with that of the pretrained model. We show, across extensive simulated and real-world experiments, that such model merging produces a single model that inherits the generalist abilities of the base model and learns to solve the new task robustly, outperforming both the pretrained and finetuned model on out-of-distribution variations of the new task. Moreover, we show that model merging performance scales with the amount of pretraining data, and enables continual acquisition of new skills in a lifelong learning setting, without sacrificing previously learned generalist abilities.
Decoupled Q-Chunking
Dec 12, 2025



Temporal-difference (TD) methods learn state and action values efficiently by bootstrapping from their own future value predictions, but such a self-bootstrapping mechanism is prone to bootstrapping bias, where the errors in the value targets accumulate across steps and result in biased value estimates. Recent work has proposed to use chunked critics, which estimate the value of short action sequences ("chunks") rather than individual actions, speeding up value backup. However, extracting policies from chunked critics is challenging: policies must output the entire action chunk open-loop, which can be sub-optimal for environments that require policy reactivity and also challenging to model especially when the chunk length grows. Our key insight is to decouple the chunk length of the critic from that of the policy, allowing the policy to operate over shorter action chunks. We propose a novel algorithm that achieves this by optimizing the policy against a distilled critic for partial action chunks, constructed by optimistically backing up from the original chunked critic to approximate the maximum value achievable when a partial action chunk is extended to a complete one. This design retains the benefits of multi-step value propagation while sidestepping both the open-loop sub-optimality and the difficulty of learning action chunking policies for long action chunks. We evaluate our method on challenging, long-horizon offline goal-conditioned tasks and show that it reliably outperforms prior methods. Code: github.com/ColinQiyangLi/dqc.
Scalable Offline Model-Based RL with Action Chunks
Dec 08, 2025In this paper, we study whether model-based reinforcement learning (RL), in particular model-based value expansion, can provide a scalable recipe for tackling complex, long-horizon tasks in offline RL. Model-based value expansion fits an on-policy value function using length-n imaginary rollouts generated by the current policy and a learned dynamics model. While larger n reduces bias in value bootstrapping, it amplifies accumulated model errors over long horizons, degrading future predictions. We address this trade-off with an \emph{action-chunk} model that predicts a future state from a sequence of actions (an "action chunk") instead of a single action, which reduces compounding errors. In addition, instead of directly training a policy to maximize rewards, we employ rejection sampling from an expressive behavioral action-chunk policy, which prevents model exploitation from out-of-distribution actions. We call this recipe \textbf{Model-Based RL with Action Chunks (MAC)}. Through experiments on highly challenging tasks with large-scale datasets of up to 100M transitions, we show that MAC achieves the best performance among offline model-based RL algorithms, especially on challenging long-horizon tasks.
$π^{*}_{0.6}$: a VLA That Learns From Experience
Nov 19, 2025We study how vision-language-action (VLA) models can improve through real-world deployments via reinforcement learning (RL). We present a general-purpose method, RL with Experience and Corrections via Advantage-conditioned Policies (RECAP), that provides for RL training of VLAs via advantage conditioning. Our method incorporates heterogeneous data into the self-improvement process, including demonstrations, data from on-policy collection, and expert teleoperated interventions provided during autonomous execution. RECAP starts by pre-training a generalist VLA with offline RL, which we call $π^{*}_{0.6}$, that can then be specialized to attain high performance on downstream tasks through on-robot data collection. We show that the $π^{*}_{0.6}$ model trained with the full RECAP method can fold laundry in real homes, reliably assemble boxes, and make espresso drinks using a professional espresso machine. On some of the hardest tasks, RECAP more than doubles task throughput and roughly halves the task failure rate.
Multistep Quasimetric Learning for Scalable Goal-conditioned Reinforcement Learning
Nov 14, 2025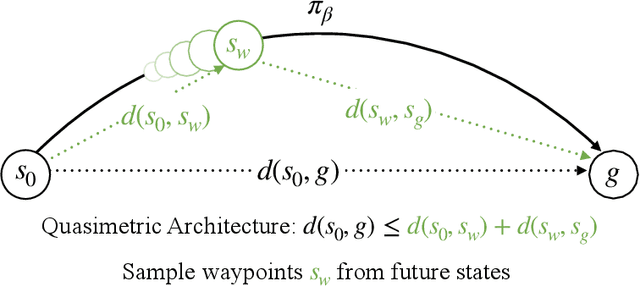


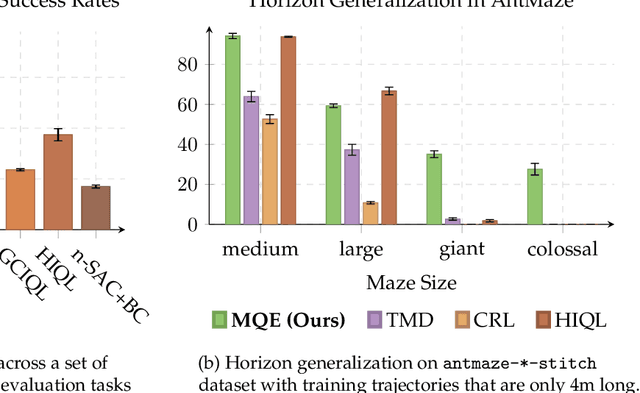
Learning how to reach goals in an environment is a longstanding challenge in AI, yet reasoning over long horizons remains a challenge for modern methods. The key question is how to estimate the temporal distance between pairs of observations. While temporal difference methods leverage local updates to provide optimality guarantees, they often perform worse than Monte Carlo methods that perform global updates (e.g., with multi-step returns), which lack such guarantees. We show how these approaches can be integrated into a practical GCRL method that fits a quasimetric distance using a multistep Monte-Carlo return. We show our method outperforms existing GCRL methods on long-horizon simulated tasks with up to 4000 steps, even with visual observations. We also demonstrate that our method can enable stitching in the real-world robotic manipulation domain (Bridge setup). Our approach is the first end-to-end GCRL method that enables multistep stitching in this real-world manipulation domain from an unlabeled offline dataset of visual observations.