 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward-Conditioned Reinforcement Learning
Mar 05, 2026RL agents are typically trained under a single, fixed reward function, which makes them brittle to reward misspecification and limits their ability to adapt to changing task preferences. We introduce Reward-Conditioned Reinforcement Learning (RCRL), a framework that trains a single agent to optimize a family of reward specifications while collecting experience under only one nominal objective. RCRL conditions the agent on reward parameterizations and learns multiple reward objectives from a shared replay data entirely off-policy, enabling a single policy to represent reward-specific behaviors. Across single-task, multi-task, and vision-based benchmarks, we show that RCRL not only improves performance under the nominal reward parameterization, but also enables efficient adaptation to new parameterizations. Our results demonstrate that RCRL provides a scalable mechanism for learning robust, steerable policies without sacrificing the simplicity of single-task training.
What Does Flow Matching Bring To TD Learning?
Mar 04, 2026Recent work shows that flow matching can be effective for scalar Q-value function estimation in reinforcement learning (RL), but it remains unclear why or how this approach differs from standard critics. Contrary to conventional belief, we show that their success is not explained by distributional RL, as explicitly modeling return distributions can reduce performance. Instead, we argue that the use of integration for reading out values and dense velocity supervision at each step of this integration process for training improves TD learning via two mechanisms. First, it enables robust value prediction through \emph{test-time recovery}, whereby iterative computation through integration dampens errors in early value estimates as more integration steps are performed. This recovery mechanism is absent in monolithic critics. Second, supervising the velocity field at multiple interpolant values induces more \emph{plastic} feature learning within the network, allowing critics to represent non-stationary TD targets without discarding previously learned features or overfitting to individual TD targets encountered during training. We formalize these effects and validate them empirically, showing that flow-matching critics substantially outperform monolithic critics (2$\times$ in final performance and around 5$\times$ in sample efficiency) in settings where loss of plasticity poses a challenge e.g., in high-UTD online RL problems, while remaining stable during learning.
Compute-Optimal Scaling for Value-Based Deep RL
Aug 20, 2025As models grow larger and training them becomes expensive, it becomes increasingly important to scale training recipes not just to larger models and more data, but to do so in a compute-optimal manner that extracts maximal performance per unit of compute. While such scaling has been well studied for language modeling, reinforcement learning (RL) has received less attention in this regard. In this paper, we investigate compute scaling for online, value-based deep RL. These methods present two primary axes for compute allocation: model capacity and the update-to-data (UTD) ratio. Given a fixed compute budget, we ask: how should resources be partitioned across these axes to maximize sample efficiency? Our analysis reveals a nuanced interplay between model size, batch size, and UTD. In particular, we identify a phenomenon we call TD-overfitting: increasing the batch quickly harms Q-function accuracy for small models, but this effect is absent in large models, enabling effective use of large batch size at scale. We provide a mental model for understanding this phenomenon and build guidelines for choosing batch size and UTD to optimize compute usage. Our findings provide a grounded starting point for compute-optimal scaling in deep RL, mirroring studies in supervised learning but adapted to TD learning.
FastTD3: Simple, Fast, and Capable Reinforcement Learning for Humanoid Control
May 29, 2025Reinforcement learning (RL) has driven significant progress in robotics, but its complexity and long training times remain major bottlenecks. In this report, we introduce FastTD3, a simple, fast, and capable RL algorithm that significantly speeds up training for humanoid robots in popular suites such as HumanoidBench, IsaacLab, and MuJoCo Playground. Our recipe is remarkably simple: we train an off-policy TD3 agent with several modifications -- parallel simulation, large-batch updates, a distributional critic, and carefully tuned hyperparameters. FastTD3 solves a range of HumanoidBench tasks in under 3 hours on a single A100 GPU, while remaining stable during training. We also provide a lightweight and easy-to-use implementation of FastTD3 to accelerate RL research in robotics.
Bigger, Regularized, Categorical: High-Capacity Value Functions are Efficient Multi-Task Learners
May 29, 2025Recent advances in language modeling and vision stem from training large models on diverse, multi-task data. This paradigm has had limited impact in value-based reinforcement learning (RL), where improvements are often driven by small models trained in a single-task context. This is because in multi-task RL sparse rewards and gradient conflicts make optimization of temporal difference brittle. Practical workflows for generalist policies therefore avoid online training, instead cloning expert trajectories or distilling collections of single-task policies into one agent. In this work, we show that the use of high-capacity value models trained via cross-entropy and conditioned on learnable task embeddings addresses the problem of task interference in online RL, allowing for robust and scalable multi-task training. We test our approach on 7 multi-task benchmarks with over 280 unique tasks, spanning high degree-of-freedom humanoid control and discrete vision-based RL. We find that, despite its simplicity, the proposed approach leads to state-of-the-art single and multi-task performance, as well as sample-efficient transfer to new tasks.
Value-Based Deep RL Scales Predictably
Feb 06, 2025Scaling data and compute is critical to the success of machine learning. However, scaling demands predictability: we want methods to not only perform well with more compute or data, but also have their performance be predictable from small-scale runs, without running the large-scale experiment. In this paper, we show that value-based off-policy RL methods are predictable despite community lore regarding their pathological behavior. First, we show that data and compute requirements to attain a given performance level lie on a Pareto frontier, controlled by the updates-to-data (UTD) ratio. By estimating this frontier, we can predict this data requirement when given more compute, and this compute requirement when given more data. Second, we determine the optimal allocation of a total resource budget across data and compute for a given performance and use it to determine hyperparameters that maximize performance for a given budget. Third, this scaling behavior is enabled by first estimating predictable relationships between hyperparameters, which is used to manage effects of overfitting and plasticity loss unique to RL. We validate our approach using three algorithms: SAC, BRO, and PQL on DeepMind Control, OpenAI gym, and IsaacGym, when extrapolating to higher levels of data, compute, budget, or performance.
Bigger, Regularized, Optimistic: scaling for compute and sample-efficient continuous control
May 25, 2024



Sample efficiency in Reinforcement Learning (RL) has traditionally been driven by algorithmic enhancements. In this work, we demonstrate that scaling can also lead to substantial improvements. We conduct a thorough investigation into the interplay of scaling model capacity and domain-specific RL enhancements. These empirical findings inform the design choices underlying our proposed BRO (Bigger, Regularized, Optimistic) algorithm. The key innovation behind BRO is that strong regularization allows for effective scaling of the critic networks, which, paired with optimistic exploration, leads to superior performance. BRO achieves state-of-the-art results, significantly outperforming the leading model-based and model-free algorithms across 40 complex tasks from the DeepMind Control, MetaWorld, and MyoSuite benchmarks. BRO is the first model-free algorithm to achieve near-optimal policies in the notoriously challenging Dog and Humanoid tasks.
Overestimation, Overfitting, and Plasticity in Actor-Critic: the Bitter Lesson of Reinforcement Learning
Mar 01, 2024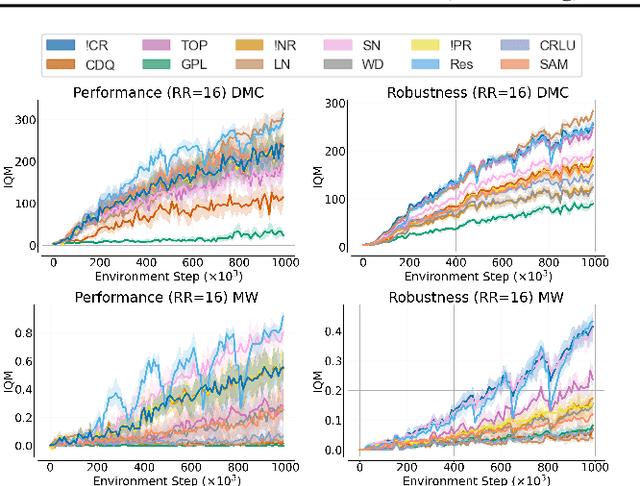

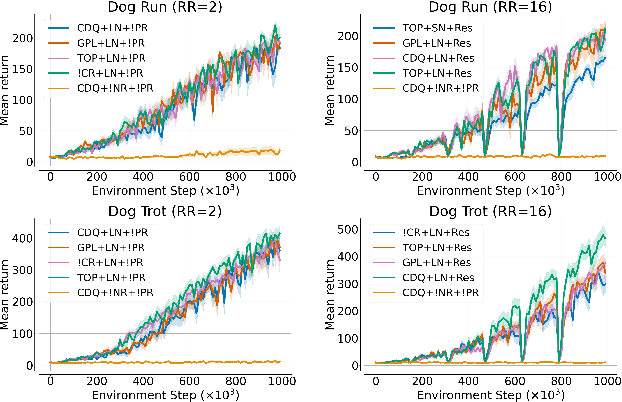
Recent advancements in off-policy Reinforcement Learning (RL) have significantly improved sample efficiency, primarily due to the incorporation of various forms of regularization that enable more gradient update steps than traditional agents. However, many of these techniques have been tested in limited settings, often on tasks from single simulation benchmarks and against well-known algorithms rather than a range of regularization approaches. This limits our understanding of the specific mechanisms driving RL improvements. To address this, we implemented over 60 different off-policy agents, each integrating established regularization techniques from recent state-of-the-art algorithms. We tested these agents across 14 diverse tasks from 2 simulation benchmarks. Our findings reveal that while the effectiveness of a specific regularization setup varies with the task, certain combinations consistently demonstrate robust and superior performance. Notably, a simple Soft Actor-Critic agent, appropriately regularized, reliably solves dog tasks, which were previously solved mainly through model-based approaches.
A Case for Validation Buffer in Pessimistic Actor-Critic
Mar 01, 2024



In this paper, we investigate the issue of error accumulation in critic networks updated via pessimistic temporal difference objectives. We show that the critic approximation error can be approximated via a recursive fixed-point model similar to that of the Bellman value. We use such recursive definition to retrieve the conditions under which the pessimistic critic is unbiased. Building on these insights, we propose Validation Pessimism Learning (VPL) algorithm. VPL uses a small validation buffer to adjust the levels of pessimism throughout the agent training, with the pessimism set such that the approximation error of the critic targets is minimized. We investigate the proposed approach on a variety of locomotion and manipulation tasks and report improvements in sample efficiency and performance.
Decoupled Actor-Critic
Oct 30, 2023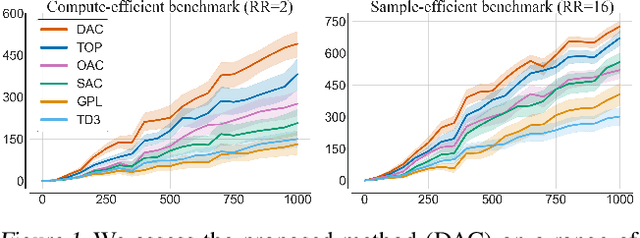
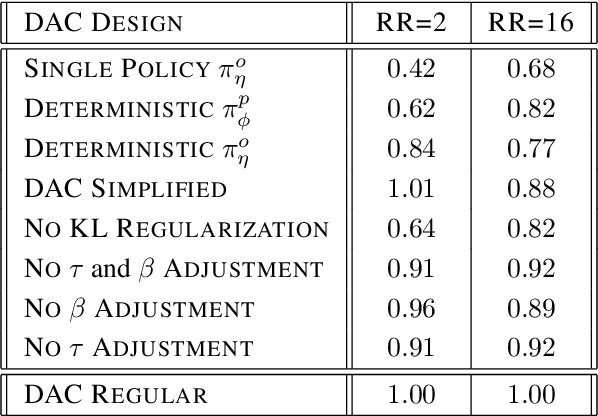
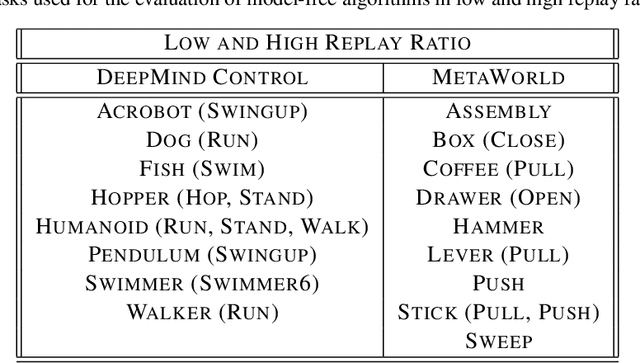
Actor-Critic methods are in a stalemate of two seemingly irreconcilable problems. Firstly, critic proneness towards overestimation requires sampling temporal-difference targets from a conservative policy optimized using lower-bound Q-values. Secondly, well-known results show that policies that are optimistic in the face of uncertainty yield lower regret levels. To remedy this dichotomy, we propose Decoupled Actor-Critic (DAC). DAC is an off-policy algorithm that learns two distinct actors by gradient backpropagation: a conservative actor used for temporal-difference learning and an optimistic actor used for exploration. We test DAC on DeepMind Control tasks in low and high replay ratio regimes and ablate multiple design choices. Despite minimal computational overhead, DAC achieves state-of-the-art performance and sample efficiency on locomotion tasks.