 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Does Non-Uniform Replay Matter in Reinforcement Learning?
May 11, 2026Modern off-policy reinforcement learning algorithms often rely on simple uniform replay sampling and it remains unclear when and why non-uniform replay improves over this strong baseline. Across diverse RL settings, we show that the effectiveness of non-uniform replay is governed by three factors: replay volume, the number of replayed transitions per environment step; expected recency, how recent sampled transitions are; and the entropy of the replay sampling distribution. Our main contribution is clarifying when non-uniform replay is beneficial and providing practical guidance for replay design in modern off-policy RL. Namely, we find that non-uniform replay is most beneficial when replay volume is low, and that high-entropy sampling is important even at comparable expected recency. Motivated by these findings, we adopt a simple Truncated Geometric replay that biases sampling toward recent experience while preserving high entropy and incurring negligible computational overhead. Across large-scale parallel simulation, single-task, and multi-task settings, including three modern algorithms evaluated on five RL benchmark suites, this replay sampling strategy improves sample efficiency in low-volume regimes while remaining competitive when replay volume is high.
Voxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
Beyond Recognition: Evaluating Visual Perspective Taking in Vision Language Models
May 03, 2025We investigate the ability of Vision Language Models (VLMs) to perform visual perspective taking using a novel set of visual tasks inspired by established human tests. Our approach leverages carefully controlled scenes, in which a single humanoid minifigure is paired with a single object. By systematically varying spatial configurations - such as object position relative to the humanoid minifigure and the humanoid minifigure's orientation - and using both bird's-eye and surface-level views, we created 144 unique visual tasks. Each visual task is paired with a series of 7 diagnostic questions designed to assess three levels of visual cognition: scene understanding, spatial reasoning, and visual perspective taking. Our evaluation of several state-of-the-art models, including GPT-4-Turbo, GPT-4o, Llama-3.2-11B-Vision-Instruct, and variants of Claude Sonnet, reveals that while they excel in scene understanding, the performance declines significantly on spatial reasoning and further deteriorates on perspective-taking. Our analysis suggests a gap between surface-level object recognition and the deeper spatial and perspective reasoning required for complex visual tasks, pointing to the need for integrating explicit geometric representations and tailored training protocols in future VLM development.
Lightweight Latent Verifiers for Efficient Meta-Generation Strategies
Apr 23, 2025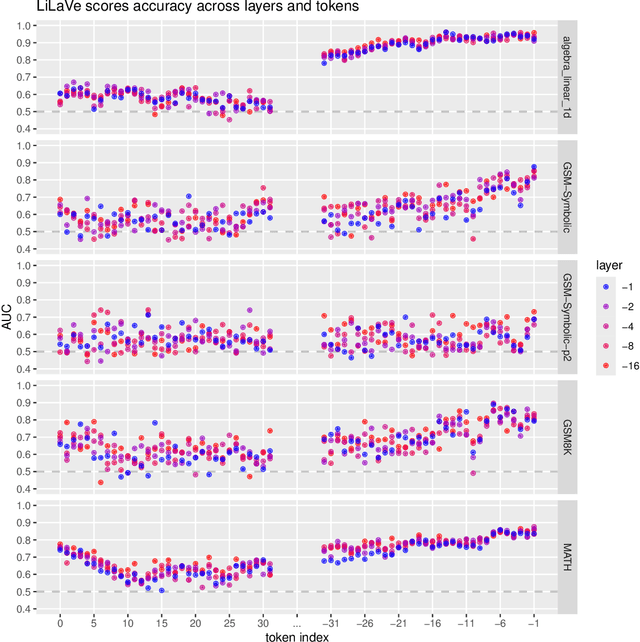



Verifiers are auxiliary models that assess the correctness of outputs generated by base large language models (LLMs). They play a crucial role in many strategies for solving reasoning-intensive problems with LLMs. Typically, verifiers are LLMs themselves, often as large (or larger) than the base model they support, making them computationally expensive. In this work, we introduce a novel lightweight verification approach, LiLaVe, which reliably extracts correctness signals from the hidden states of the base LLM. A key advantage of LiLaVe is its ability to operate with only a small fraction of the computational budget required by traditional LLM-based verifiers. To demonstrate its practicality, we couple LiLaVe with popular meta-generation strategies, like best-of-n or self-consistency. Moreover, we design novel LiLaVe-based approaches, like conditional self-correction or conditional majority voting, that significantly improve both accuracy and efficiency in generation tasks with smaller LLMs. Our work demonstrates the fruitfulness of extracting latent information from the hidden states of LLMs, and opens the door to scalable and resource-efficient solutions for reasoning-intensive applications.
Since Faithfulness Fails: The Performance Limits of Neural Causal Discovery
Feb 22, 2025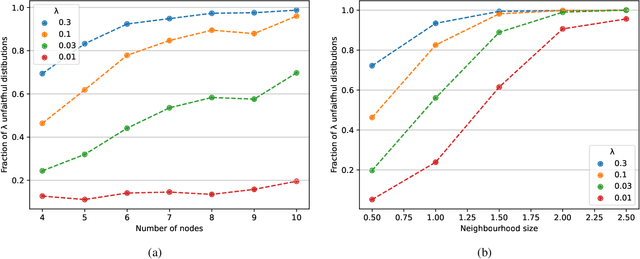



Neural causal discovery methods have recently improved in terms of scalability and computational efficiency. However, our systematic evaluation highlights significant room for improvement in their accuracy when uncovering causal structures. We identify a fundamental limitation: neural networks cannot reliably distinguish between existing and non-existing causal relationships in the finite sample regime. Our experiments reveal that neural networks, as used in contemporary causal discovery approaches, lack the precision needed to recover ground-truth graphs, even for small graphs and relatively large sample sizes. Furthermore, we identify the faithfulness property as a critical bottleneck: (i) it is likely to be violated across any reasonable dataset size range, and (ii) its violation directly undermines the performance of neural discovery methods. These findings lead us to conclude that progress within the current paradigm is fundamentally constrained, necessitating a paradigm shift in this domain.
Joint MoE Scaling Laws: Mixture of Experts Can Be Memory Efficient
Feb 07, 2025



Mixture of Experts (MoE) architectures have significantly increased computational efficiency in both research and real-world applications of large-scale machine learning models. However, their scalability and efficiency under memory constraints remain relatively underexplored. In this work, we present joint scaling laws for dense and MoE models, incorporating key factors such as the number of active parameters, dataset size, and the number of experts. Our findings provide a principled framework for selecting the optimal MoE configuration under fixed memory and compute budgets. Surprisingly, we show that MoE models can be more memory-efficient than dense models, contradicting conventional wisdom. To derive and validate the theoretical predictions of our scaling laws, we conduct over 280 experiments with up to 2.7B active parameters and up to 5B total parameters. These results offer actionable insights for designing and deploying MoE models in practical large-scale training scenarios.
Repurposing Language Models into Embedding Models: Finding the Compute-Optimal Recipe
Jun 06, 2024



Text embeddings are essential for many tasks, such as document retrieval, clustering, and semantic similarity assessment. In this paper, we study how to contrastively train text embedding models in a compute-optimal fashion, given a suite of pre-trained decoder-only language models. Our innovation is an algorithm that produces optimal configurations of model sizes, data quantities, and fine-tuning methods for text-embedding models at different computational budget levels. The resulting recipe, which we obtain through extensive experiments, can be used by practitioners to make informed design choices for their embedding models. Specifically, our findings suggest that full fine-tuning and low-rank adaptation fine-tuning produce optimal models at lower and higher computational budgets respectively.
What Matters in Hierarchical Search for Combinatorial Reasoning Problems?
Jun 05, 2024Efficiently tackling combinatorial reasoning problems, particularly the notorious NP-hard tasks, remains a significant challenge for AI research. Recent efforts have sought to enhance planning by incorporating hierarchical high-level search strategies, known as subgoal methods. While promising, their performance against traditional low-level planners is inconsistent, raising questions about their application contexts. In this study, we conduct an in-depth exploration of subgoal-planning methods for combinatorial reasoning. We identify the attributes pivotal for leveraging the advantages of high-level search: hard-to-learn value functions, complex action spaces, presence of dead ends in the environment, or using data collected from diverse experts. We propose a consistent evaluation methodology to achieve meaningful comparisons between methods and reevaluate the state-of-the-art algorithms.
Bigger, Regularized, Optimistic: scaling for compute and sample-efficient continuous control
May 25, 2024



Sample efficiency in Reinforcement Learning (RL) has traditionally been driven by algorithmic enhancements. In this work, we demonstrate that scaling can also lead to substantial improvements. We conduct a thorough investigation into the interplay of scaling model capacity and domain-specific RL enhancements. These empirical findings inform the design choices underlying our proposed BRO (Bigger, Regularized, Optimistic) algorithm. The key innovation behind BRO is that strong regularization allows for effective scaling of the critic networks, which, paired with optimistic exploration, leads to superior performance. BRO achieves state-of-the-art results, significantly outperforming the leading model-based and model-free algorithms across 40 complex tasks from the DeepMind Control, MetaWorld, and MyoSuite benchmarks. BRO is the first model-free algorithm to achieve near-optimal policies in the notoriously challenging Dog and Humanoid tasks.