 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgetsGT: Stochastic Time Series Modeling With Transformer
Mar 15, 2024Time series methods are of fundamental importance in virtually any field of science that deals with temporally structured data. Recently, there has been a surge of deterministic transformer models with time series-specific architectural biases. In this paper, we go in a different direction by introducing tsGT, a stochastic time series model built on a general-purpose transformer architecture. We focus on using a well-known and theoretically justified rolling window backtesting and evaluation protocol. We show that tsGT outperforms the state-of-the-art models on MAD and RMSE, and surpasses its stochastic peers on QL and CRPS, on four commonly used datasets. We complement these results with a detailed analysis of tsGT's ability to model the data distribution and predict marginal quantile values.
Sparse is Enough in Scaling Transformers
Nov 24, 2021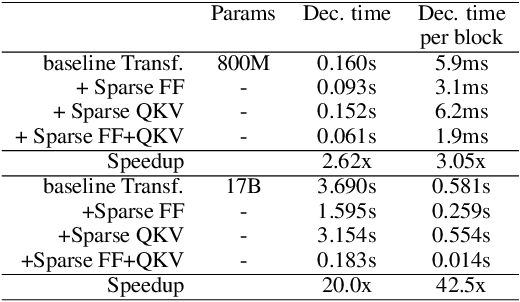
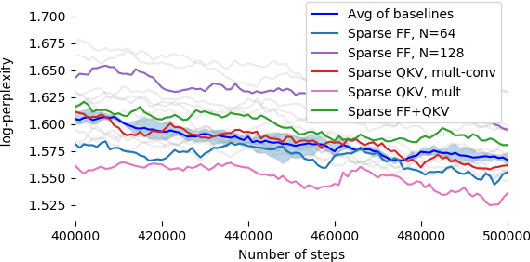
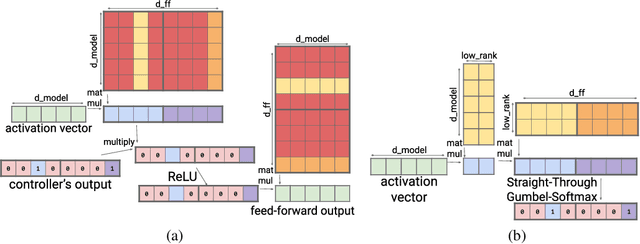
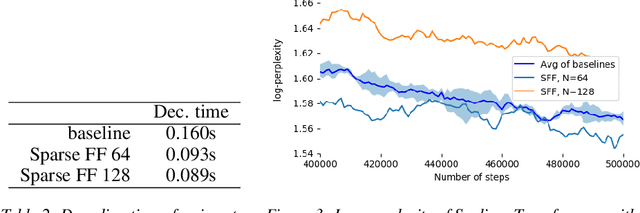
Large Transformer models yield impressive results on many tasks, but are expensive to train, or even fine-tune, and so slow at decoding that their use and study becomes out of reach. We address this problem by leveraging sparsity. We study sparse variants for all layers in the Transformer and propose Scaling Transformers, a family of next generation Transformer models that use sparse layers to scale efficiently and perform unbatched decoding much faster than the standard Transformer as we scale up the model size. Surprisingly, the sparse layers are enough to obtain the same perplexity as the standard Transformer with the same number of parameters. We also integrate with prior sparsity approaches to attention and enable fast inference on long sequences even with limited memory. This results in performance competitive to the state-of-the-art on long text summarization.
Hierarchical Transformers Are More Efficient Language Models
Oct 26, 2021

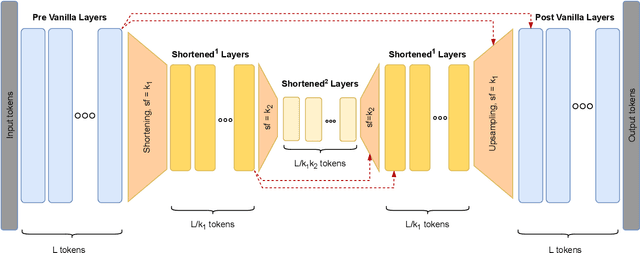

Transformer models yield impressive results on many NLP and sequence modeling tasks. Remarkably, Transformers can handle long sequences which allows them to produce long coherent outputs: full paragraphs produced by GPT-3 or well-structured images produced by DALL-E. These large language models are impressive but also very inefficient and costly, which limits their applications and accessibility. We postulate that having an explicit hierarchical architecture is the key to Transformers that efficiently handle long sequences. To verify this claim, we first study different ways to downsample and upsample activations in Transformers so as to make them hierarchical. We use the best performing upsampling and downsampling layers to create Hourglass - a hierarchical Transformer language model. Hourglass improves upon the Transformer baseline given the same amount of computation and can yield the same results as Transformers more efficiently. In particular, Hourglass sets new state-of-the-art for Transformer models on the ImageNet32 generation task and improves language modeling efficiency on the widely studied enwik8 benchmark.
Q-Value Weighted Regression: Reinforcement Learning with Limited Data
Feb 12, 2021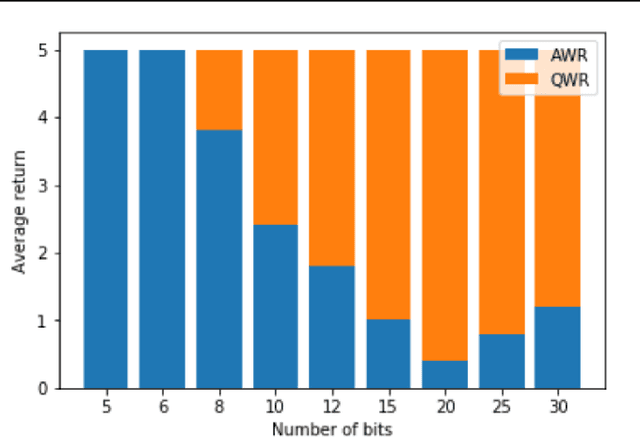
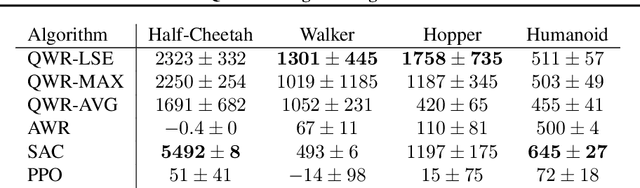
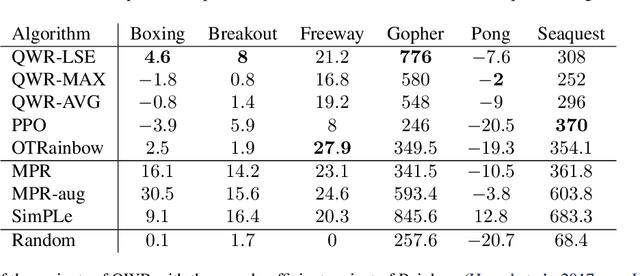
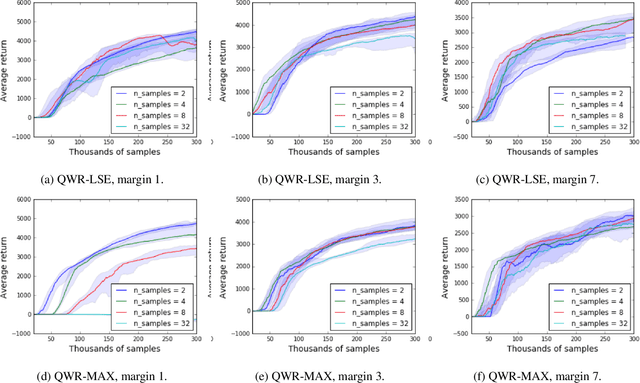
Sample efficiency and performance in the offline setting have emerged as significant challenges of deep reinforcement learning. We introduce Q-Value Weighted Regression (QWR), a simple RL algorithm that excels in these aspects. QWR is an extension of Advantage Weighted Regression (AWR), an off-policy actor-critic algorithm that performs very well on continuous control tasks, also in the offline setting, but has low sample efficiency and struggles with high-dimensional observation spaces. We perform an analysis of AWR that explains its shortcomings and use these insights to motivate QWR. We show experimentally that QWR matches the state-of-the-art algorithms both on tasks with continuous and discrete actions. In particular, QWR yields results on par with SAC on the MuJoCo suite and - with the same set of hyperparameters - yields results on par with a highly tuned Rainbow implementation on a set of Atari games. We also verify that QWR performs well in the offline RL setting.
Reformer: The Efficient Transformer
Feb 18, 2020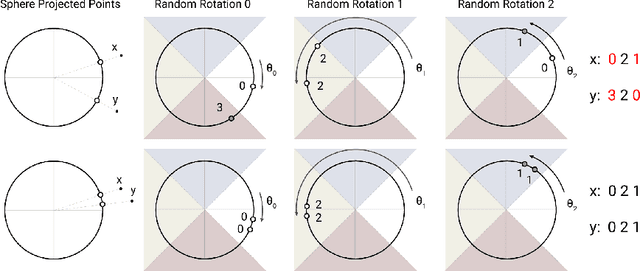
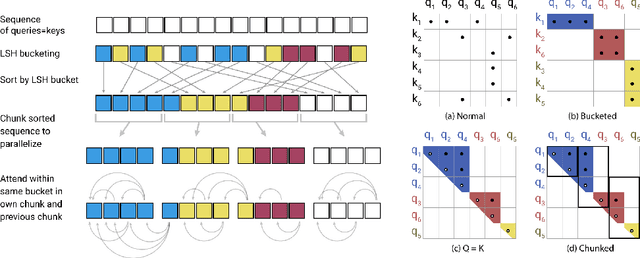
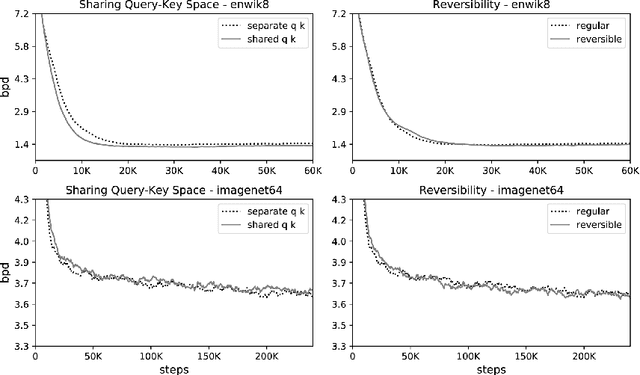
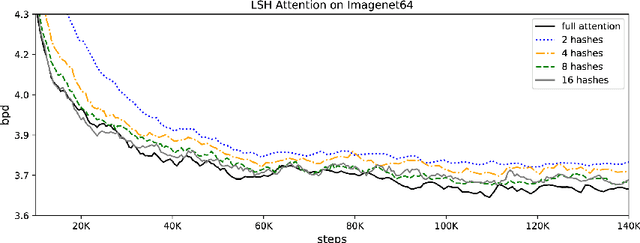
Large Transformer models routinely achieve state-of-the-art results on a number of tasks but training these models can be prohibitively costly, especially on long sequences. We introduce two techniques to improve the efficiency of Transformers. For one, we replace dot-product attention by one that uses locality-sensitive hashing, changing its complexity from O($L^2$) to O($L\log L$), where $L$ is the length of the sequence. Furthermore, we use reversible residual layers instead of the standard residuals, which allows storing activations only once in the training process instead of $N$ times, where $N$ is the number of layers. The resulting model, the Reformer, performs on par with Transformer models while being much more memory-efficient and much faster on long sequences.
Universal Transformers
Jul 10, 2018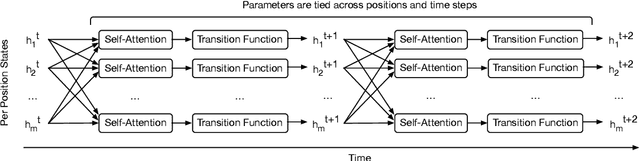
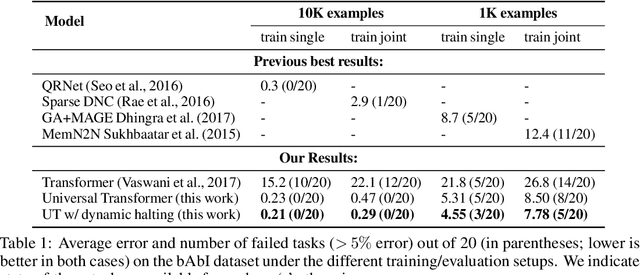
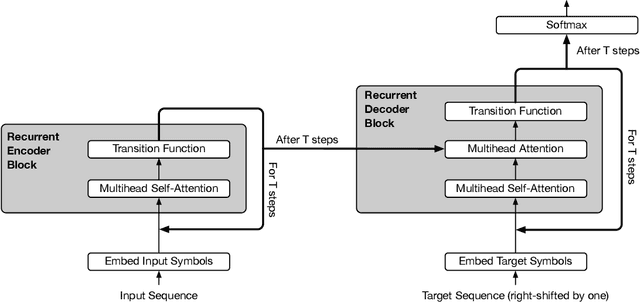
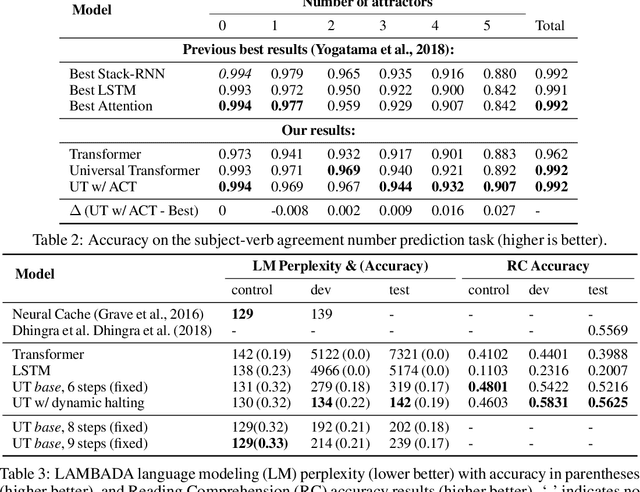
Self-attentive feed-forward sequence models have been shown to achieve impressive results on sequence modeling tasks, thereby presenting a compelling alternative to recurrent neural networks (RNNs) which has remained the de-facto standard architecture for many sequence modeling problems to date. Despite these successes, however, feed-forward sequence models like the Transformer fail to generalize in many tasks that recurrent models handle with ease (e.g. copying when the string lengths exceed those observed at training time). Moreover, and in contrast to RNNs, the Transformer model is not computationally universal, limiting its theoretical expressivity. In this paper we propose the Universal Transformer which addresses these practical and theoretical shortcomings and we show that it leads to improved performance on several tasks. Instead of recurring over the individual symbols of sequences like RNNs, the Universal Transformer repeatedly revises its representations of all symbols in the sequence with each recurrent step. In order to combine information from different parts of a sequence, it employs a self-attention mechanism in every recurrent step. Assuming sufficient memory, its recurrence makes the Universal Transformer computationally universal. We further employ an adaptive computation time (ACT) mechanism to allow the model to dynamically adjust the number of times the representation of each position in a sequence is revised. Beyond saving computation, we show that ACT can improve the accuracy of the model. Our experiments show that on various algorithmic tasks and a diverse set of large-scale language understanding tasks the Universal Transformer generalizes significantly better and outperforms both a vanilla Transformer and an LSTM in machine translation, and achieves a new state of the art on the bAbI linguistic reasoning task and the challenging LAMBADA language modeling task.
Image Transformer
Jun 15, 2018
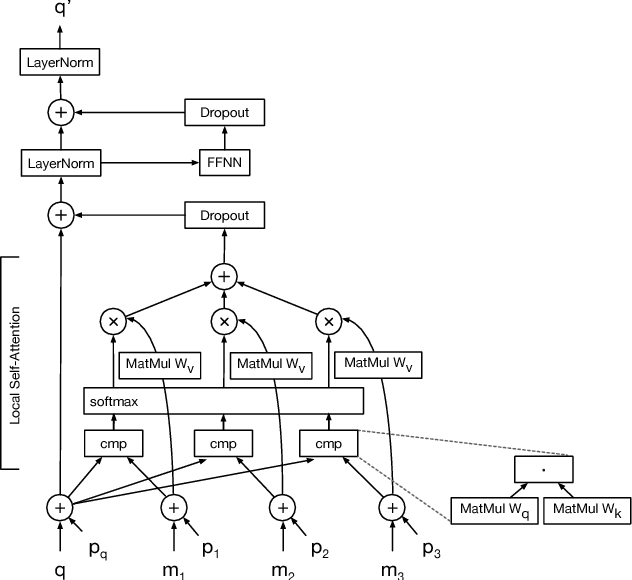

Image generation has been successfully cast as an autoregressive sequence generation or transformation problem. Recent work has shown that self-attention is an effective way of modeling textual sequences. In this work, we generalize a recently proposed model architecture based on self-attention, the Transformer, to a sequence modeling formulation of image generation with a tractable likelihood. By restricting the self-attention mechanism to attend to local neighborhoods we significantly increase the size of images the model can process in practice, despite maintaining significantly larger receptive fields per layer than typical convolutional neural networks. While conceptually simple, our generative models significantly outperform the current state of the art in image generation on ImageNet, improving the best published negative log-likelihood on ImageNet from 3.83 to 3.77. We also present results on image super-resolution with a large magnification ratio, applying an encoder-decoder configuration of our architecture. In a human evaluation study, we find that images generated by our super-resolution model fool human observers three times more often than the previous state of the art.
Fast Decoding in Sequence Models using Discrete Latent Variables
Jun 07, 2018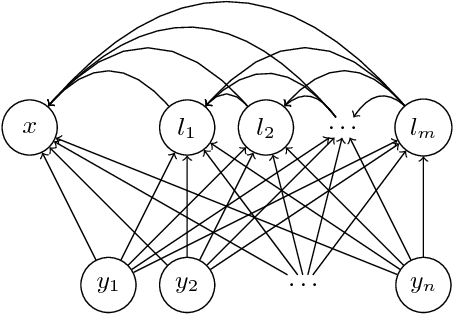

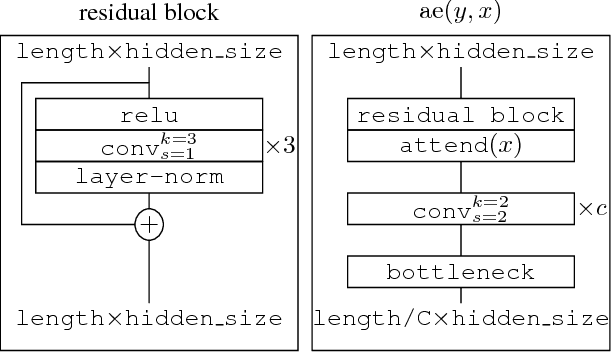
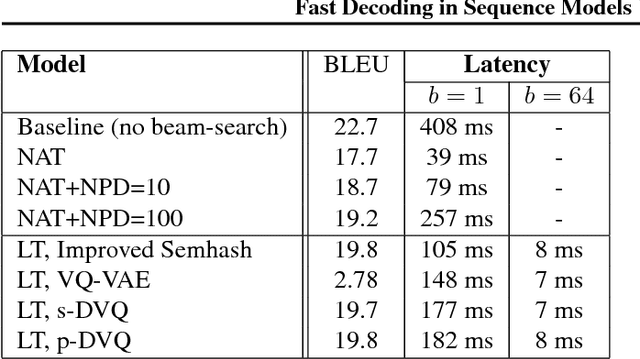
Autoregressive sequence models based on deep neural networks, such as RNNs, Wavenet and the Transformer attain state-of-the-art results on many tasks. However, they are difficult to parallelize and are thus slow at processing long sequences. RNNs lack parallelism both during training and decoding, while architectures like WaveNet and Transformer are much more parallelizable during training, yet still operate sequentially during decoding. Inspired by [arxiv:1711.00937], we present a method to extend sequence models using discrete latent variables that makes decoding much more parallelizable. We first auto-encode the target sequence into a shorter sequence of discrete latent variables, which at inference time is generated autoregressively, and finally decode the output sequence from this shorter latent sequence in parallel. To this end, we introduce a novel method for constructing a sequence of discrete latent variables and compare it with previously introduced methods. Finally, we evaluate our model end-to-end on the task of neural machine translation, where it is an order of magnitude faster at decoding than comparable autoregressive models. While lower in BLEU than purely autoregressive models, our model achieves higher scores than previously proposed non-autoregressive translation models.
Tensor2Tensor for Neural Machine Translation
Mar 16, 2018
Tensor2Tensor is a library for deep learning models that is well-suited for neural machine translation and includes the reference implementation of the state-of-the-art Transformer model.
Discrete Autoencoders for Sequence Models
Jan 29, 2018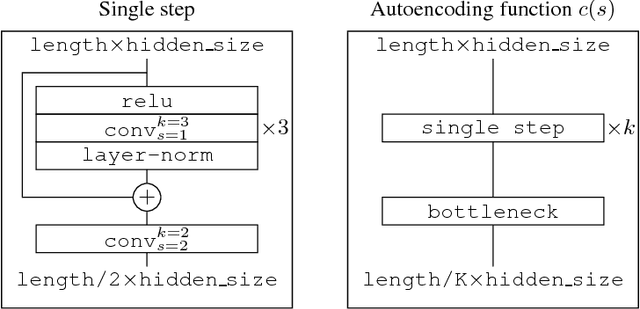
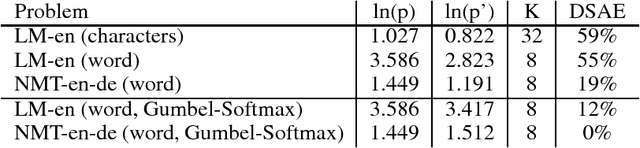
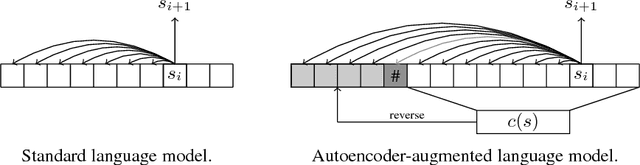
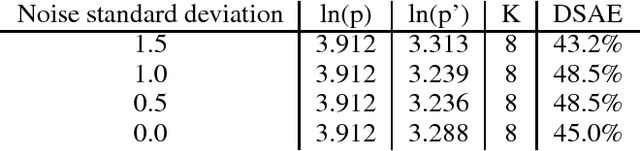
Recurrent models for sequences have been recently successful at many tasks, especially for language modeling and machine translation. Nevertheless, it remains challenging to extract good representations from these models. For instance, even though language has a clear hierarchical structure going from characters through words to sentences, it is not apparent in current language models. We propose to improve the representation in sequence models by augmenting current approaches with an autoencoder that is forced to compress the sequence through an intermediate discrete latent space. In order to propagate gradients though this discrete representation we introduce an improved semantic hashing technique. We show that this technique performs well on a newly proposed quantitative efficiency measure. We also analyze latent codes produced by the model showing how they correspond to words and phrases. Finally, we present an application of the autoencoder-augmented model to generating diverse translations.