 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTomayto, Tomahto. Beyond Token-level Answer Equivalence for Question Answering Evaluation
Feb 15, 2022The predictions of question answering (QA) systems are typically evaluated against manually annotated finite sets of one or more answers. This leads to a coverage limitation that results in underestimating the true performance of systems, and is typically addressed by extending over exact match (EM) with predefined rules or with the token-level F1 measure. In this paper, we present the first systematic conceptual and data-driven analysis to examine the shortcomings of token-level equivalence measures. To this end, we define the asymmetric notion of answer equivalence (AE), accepting answers that are equivalent to or improve over the reference, and collect over 26K human judgements for candidates produced by multiple QA systems on SQuAD. Through a careful analysis of this data, we reveal and quantify several concrete limitations of the F1 measure, such as false impression of graduality, missing dependence on question, and more. Since collecting AE annotations for each evaluated model is expensive, we learn a BERT matching BEM measure to approximate this task. Being a simpler task than QA, we find BEM to provide significantly better AE approximations than F1, and more accurately reflect the performance of systems. Finally, we also demonstrate the practical utility of AE and BEM on the concrete application of minimal accurate prediction sets, reducing the number of required answers by up to 2.6 times.
Sparse is Enough in Scaling Transformers
Nov 24, 2021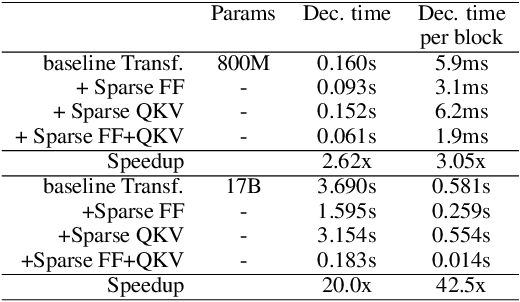
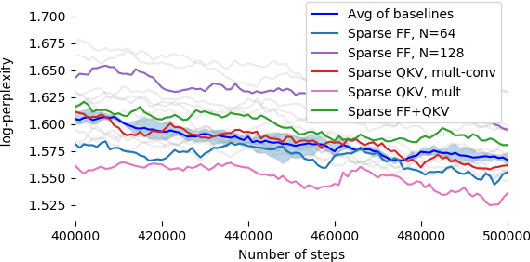
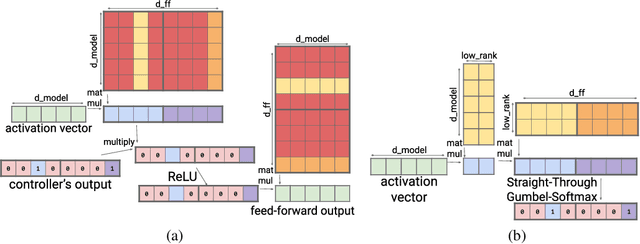
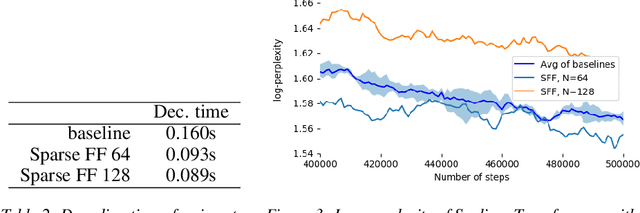
Large Transformer models yield impressive results on many tasks, but are expensive to train, or even fine-tune, and so slow at decoding that their use and study becomes out of reach. We address this problem by leveraging sparsity. We study sparse variants for all layers in the Transformer and propose Scaling Transformers, a family of next generation Transformer models that use sparse layers to scale efficiently and perform unbatched decoding much faster than the standard Transformer as we scale up the model size. Surprisingly, the sparse layers are enough to obtain the same perplexity as the standard Transformer with the same number of parameters. We also integrate with prior sparsity approaches to attention and enable fast inference on long sequences even with limited memory. This results in performance competitive to the state-of-the-art on long text summarization.
Meta Answering for Machine Reading
Nov 11, 2019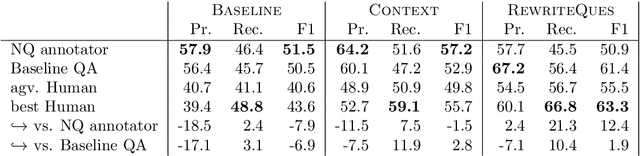
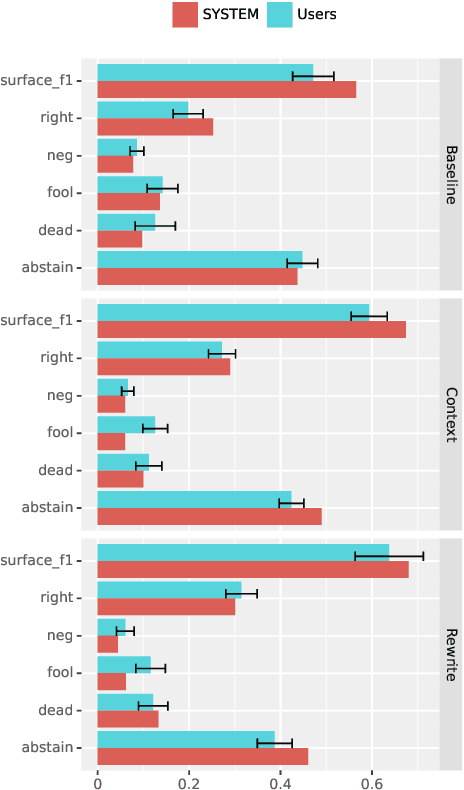

We investigate a framework for machine reading, inspired by real world information-seeking problems, where a meta question answering system interacts with a black box environment. The environment encapsulates a competitive machine reader based on BERT, providing candidate answers to questions, and possibly some context. To validate the realism of our formulation, we ask humans to play the role of a meta-answerer. With just a small snippet of text around an answer, humans can outperform the machine reader, improving recall. Similarly, a simple machine meta-answerer outperforms the environment, improving both precision and recall on the Natural Questions dataset. The system relies on joint training of answer scoring and the selection of conditioning information.
Ask the Right Questions: Active Question Reformulation with Reinforcement Learning
Mar 02, 2018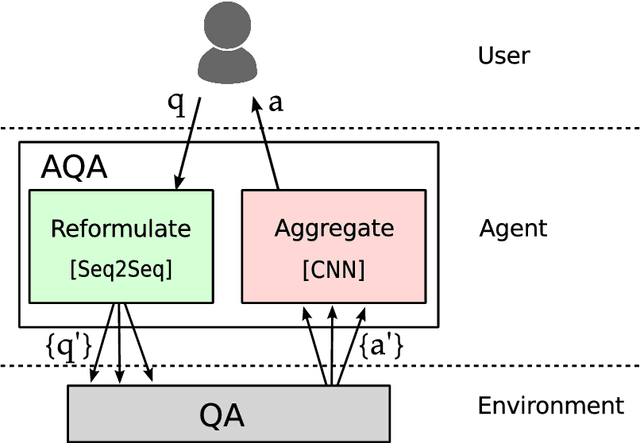
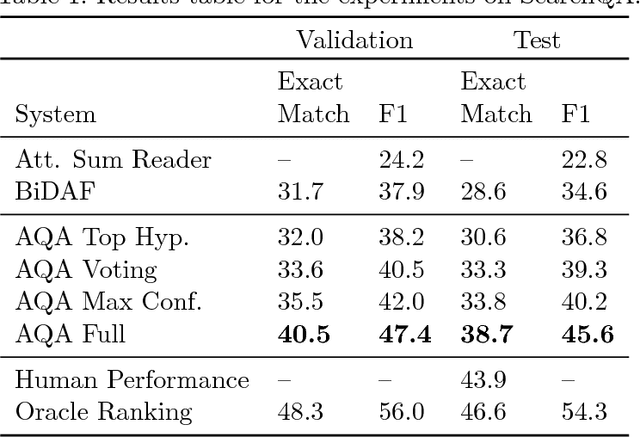
We frame Question Answering (QA) as a Reinforcement Learning task, an approach that we call Active Question Answering. We propose an agent that sits between the user and a black box QA system and learns to reformulate questions to elicit the best possible answers. The agent probes the system with, potentially many, natural language reformulations of an initial question and aggregates the returned evidence to yield the best answer. The reformulation system is trained end-to-end to maximize answer quality using policy gradient. We evaluate on SearchQA, a dataset of complex questions extracted from Jeopardy!. The agent outperforms a state-of-the-art base model, playing the role of the environment, and other benchmarks. We also analyze the language that the agent has learned while interacting with the question answering system. We find that successful question reformulations look quite different from natural language paraphrases. The agent is able to discover non-trivial reformulation strategies that resemble classic information retrieval techniques such as term re-weighting (tf-idf) and stemming.
Analyzing Language Learned by an Active Question Answering Agent
Jan 23, 2018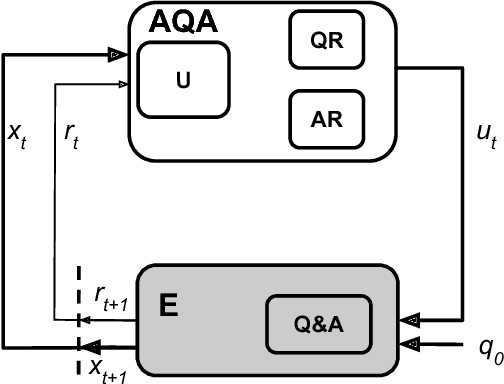
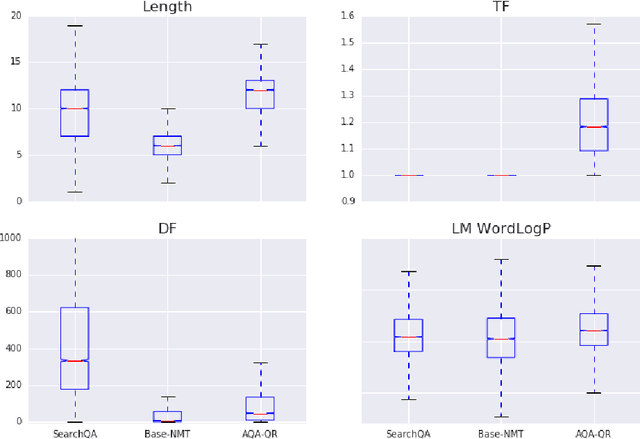
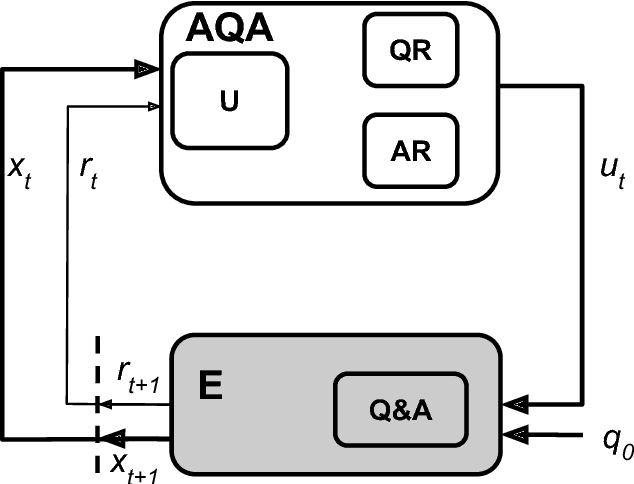
We analyze the language learned by an agent trained with reinforcement learning as a component of the ActiveQA system [Buck et al., 2017]. In ActiveQA, question answering is framed as a reinforcement learning task in which an agent sits between the user and a black box question-answering system. The agent learns to reformulate the user's questions to elicit the optimal answers. It probes the system with many versions of a question that are generated via a sequence-to-sequence question reformulation model, then aggregates the returned evidence to find the best answer. This process is an instance of \emph{machine-machine} communication. The question reformulation model must adapt its language to increase the quality of the answers returned, matching the language of the question answering system. We find that the agent does not learn transformations that align with semantic intuitions but discovers through learning classical information retrieval techniques such as tf-idf re-weighting and stemming.