 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Reference (In-)Determinacy in Natural Language Inference
Feb 09, 2025



We revisit the reference determinacy (RD) assumption in the task of natural language inference (NLI), i.e., the premise and hypothesis are assumed to refer to the same context when human raters annotate a label. While RD is a practical assumption for constructing a new NLI dataset, we observe that current NLI models, which are typically trained solely on hypothesis-premise pairs created with the RD assumption, fail in downstream applications such as fact verification, where the input premise and hypothesis may refer to different contexts. To highlight the impact of this phenomenon in real-world use cases, we introduce RefNLI, a diagnostic benchmark for identifying reference ambiguity in NLI examples. In RefNLI, the premise is retrieved from a knowledge source (i.e., Wikipedia) and does not necessarily refer to the same context as the hypothesis. With RefNLI, we demonstrate that finetuned NLI models and few-shot prompted LLMs both fail to recognize context mismatch, leading to over 80% false contradiction and over 50% entailment predictions. We discover that the existence of reference ambiguity in NLI examples can in part explain the inherent human disagreements in NLI and provide insight into how the RD assumption impacts the NLI dataset creation process.
Tomato, Tomahto, Tomate: Measuring the Role of Shared Semantics among Subwords in Multilingual Language Models
Nov 07, 2024



Human understanding of language is robust to different word choices as far as they represent similar semantic concepts. To what extent does our human intuition transfer to language models, which represent all subwords as distinct embeddings? In this work, we take an initial step on measuring the role of shared semantics among subwords in the encoder-only multilingual language models (mLMs). To this end, we form "semantic tokens" by merging the semantically similar subwords and their embeddings, and evaluate the updated mLMs on 5 heterogeneous multilingual downstream tasks. Results show that the general shared semantics could get the models a long way in making the predictions on mLMs with different tokenizers and model sizes. Inspections on the grouped subwords show that they exhibit a wide range of semantic similarities, including synonyms and translations across many languages and scripts. Lastly, we found the zero-shot results with semantic tokens are on par or even better than the original models on certain classification tasks, suggesting that the shared subword-level semantics may serve as the anchors for cross-lingual transferring.
Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise LoRA
Oct 28, 2024



Large language models (LLMs) are expensive to deploy. Parameter sharing offers a possible path towards reducing their size and cost, but its effectiveness in modern LLMs remains fairly limited. In this work, we revisit "layer tying" as form of parameter sharing in Transformers, and introduce novel methods for converting existing LLMs into smaller "Recursive Transformers" that share parameters across layers, with minimal loss of performance. Here, our Recursive Transformers are efficiently initialized from standard pretrained Transformers, but only use a single block of unique layers that is then repeated multiple times in a loop. We further improve performance by introducing Relaxed Recursive Transformers that add flexibility to the layer tying constraint via depth-wise low-rank adaptation (LoRA) modules, yet still preserve the compactness of the overall model. We show that our recursive models (e.g., recursive Gemma 1B) outperform both similar-sized vanilla pretrained models (such as TinyLlama 1.1B and Pythia 1B) and knowledge distillation baselines -- and can even recover most of the performance of the original "full-size" model (e.g., Gemma 2B with no shared parameters). Finally, we propose Continuous Depth-wise Batching, a promising new inference paradigm enabled by the Recursive Transformer when paired with early exiting. In a theoretical analysis, we show that this has the potential to lead to significant (2-3x) gains in inference throughput.
TACT: Advancing Complex Aggregative Reasoning with Information Extraction Tools
Jun 05, 2024



Large Language Models (LLMs) often do not perform well on queries that require the aggregation of information across texts. To better evaluate this setting and facilitate modeling efforts, we introduce TACT - Text And Calculations through Tables, a dataset crafted to evaluate LLMs' reasoning and computational abilities using complex instructions. TACT contains challenging instructions that demand stitching information scattered across one or more texts, and performing complex integration on this information to generate the answer. We construct this dataset by leveraging an existing dataset of texts and their associated tables. For each such tables, we formulate new queries, and gather their respective answers. We demonstrate that all contemporary LLMs perform poorly on this dataset, achieving an accuracy below 38\%. To pinpoint the difficulties and thoroughly dissect the problem, we analyze model performance across three components: table-generation, Pandas command-generation, and execution. Unexpectedly, we discover that each component presents substantial challenges for current LLMs. These insights lead us to propose a focused modeling framework, which we refer to as IE as a tool. Specifically, we propose to add "tools" for each of the above steps, and implement each such tool with few-shot prompting. This approach shows an improvement over existing prompting techniques, offering a promising direction for enhancing model capabilities in these tasks.
Block Transformer: Global-to-Local Language Modeling for Fast Inference
Jun 04, 2024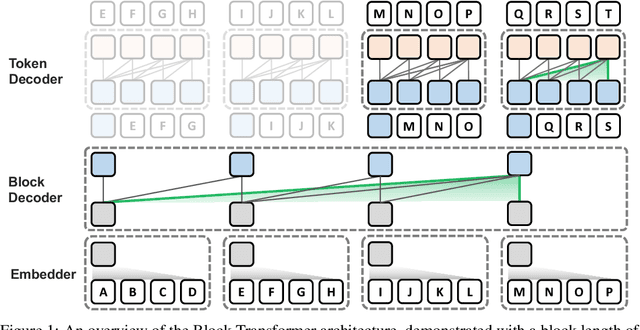
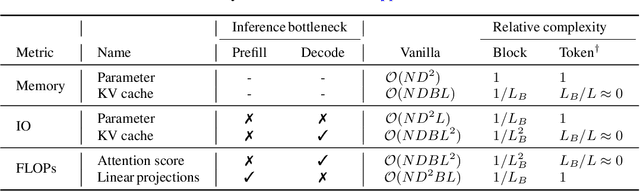
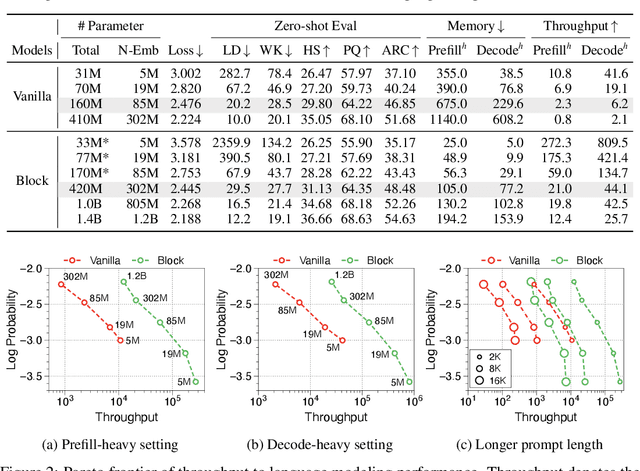
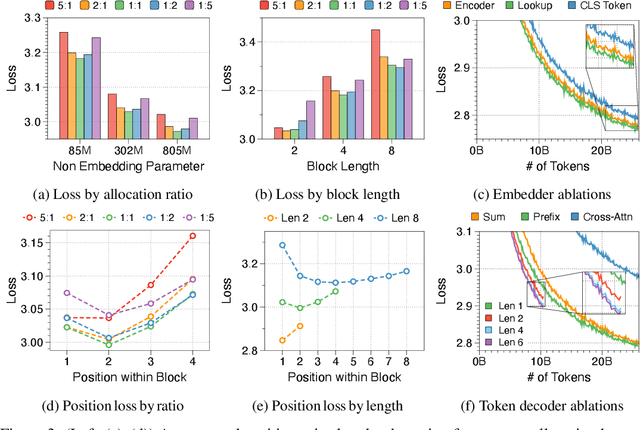
This paper presents the Block Transformer architecture which adopts hierarchical global-to-local modeling to autoregressive transformers to mitigate the inference bottlenecks of self-attention. To apply self-attention, the key-value (KV) cache of all previous sequences must be retrieved from memory at every decoding step. Thereby, this KV cache IO becomes a significant bottleneck in batch inference. We notice that these costs stem from applying self-attention on the global context, therefore we isolate the expensive bottlenecks of global modeling to lower layers and apply fast local modeling in upper layers. To mitigate the remaining costs in the lower layers, we aggregate input tokens into fixed size blocks and then apply self-attention at this coarse level. Context information is aggregated into a single embedding to enable upper layers to decode the next block of tokens, without global attention. Free of global attention bottlenecks, the upper layers can fully utilize the compute hardware to maximize inference throughput. By leveraging global and local modules, the Block Transformer architecture demonstrates 10-20x gains in inference throughput compared to vanilla transformers with equivalent perplexity. Our work introduces a new approach to optimize language model inference through novel application of global-to-local modeling. Code is available at https://github.com/itsnamgyu/block-transformer.
Attribute First, then Generate: Locally-attributable Grounded Text Generation
Apr 01, 2024Recent efforts to address hallucinations in Large Language Models (LLMs) have focused on attributed text generation, which supplements generated texts with citations of supporting sources for post-generation fact-checking and corrections. Yet, these citations often point to entire documents or paragraphs, burdening users with extensive verification work. In this paper, we introduce a locally-attributable text generation approach, prioritizing concise attributions. Our method, named ``Attribute First, then Generate'', breaks down the conventional end-to-end generation process into three intuitive steps: content selection, sentence planning, and sequential sentence generation. By initially identifying relevant source segments (``select first'') and then conditioning the generation process on them (``then generate''), we ensure these segments also act as the output's fine-grained attributions (``select'' becomes ``attribute''). Tested on Multi-document Summarization and Long-form Question-answering, our method not only yields more concise citations than the baselines but also maintains - and in some cases enhances - both generation quality and attribution accuracy. Furthermore, it significantly reduces the time required for fact verification by human assessors.
SEMQA: Semi-Extractive Multi-Source Question Answering
Nov 08, 2023Recently proposed long-form question answering (QA) systems, supported by large language models (LLMs), have shown promising capabilities. Yet, attributing and verifying their generated abstractive answers can be difficult, and automatically evaluating their accuracy remains an ongoing challenge. In this work, we introduce a new QA task for answering multi-answer questions by summarizing multiple diverse sources in a semi-extractive fashion. Specifically, Semi-extractive Multi-source QA (SEMQA) requires models to output a comprehensive answer, while mixing factual quoted spans -- copied verbatim from given input sources -- and non-factual free-text connectors that glue these spans together into a single cohesive passage. This setting bridges the gap between the outputs of well-grounded but constrained extractive QA systems and more fluent but harder to attribute fully abstractive answers. Particularly, it enables a new mode for language models that leverages their advanced language generation capabilities, while also producing fine in-line attributions by-design that are easy to verify, interpret, and evaluate. To study this task, we create the first dataset of this kind, QuoteSum, with human-written semi-extractive answers to natural and generated questions, and define text-based evaluation metrics. Experimenting with several LLMs in various settings, we find this task to be surprisingly challenging, demonstrating the importance of QuoteSum for developing and studying such consolidation capabilities.
SDOH-NLI: a Dataset for Inferring Social Determinants of Health from Clinical Notes
Oct 27, 2023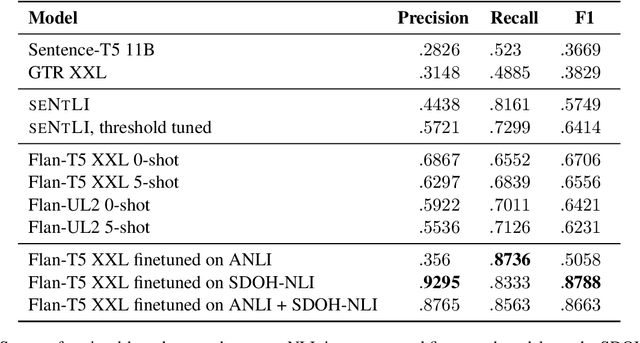
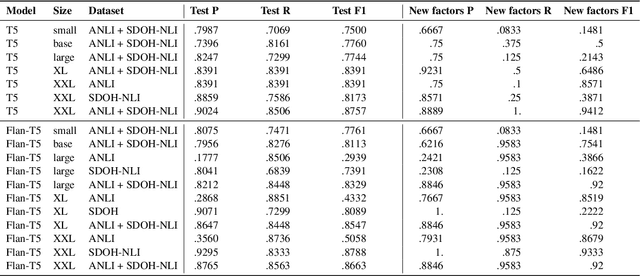
Social and behavioral determinants of health (SDOH) play a significant role in shaping health outcomes, and extracting these determinants from clinical notes is a first step to help healthcare providers systematically identify opportunities to provide appropriate care and address disparities. Progress on using NLP methods for this task has been hindered by the lack of high-quality publicly available labeled data, largely due to the privacy and regulatory constraints on the use of real patients' information. This paper introduces a new dataset, SDOH-NLI, that is based on publicly available notes and which we release publicly. We formulate SDOH extraction as a natural language inference (NLI) task, and provide binary textual entailment labels obtained from human raters for a cross product of a set of social history snippets as premises and SDOH factors as hypotheses. Our dataset differs from standard NLI benchmarks in that our premises and hypotheses are obtained independently. We evaluate both "off-the-shelf" entailment models as well as models fine-tuned on our data, and highlight the ways in which our dataset appears more challenging than commonly used NLI datasets.
Conformal Language Modeling
Jun 16, 2023We propose a novel approach to conformal prediction for generative language models (LMs). Standard conformal prediction produces prediction sets -- in place of single predictions -- that have rigorous, statistical performance guarantees. LM responses are typically sampled from the model's predicted distribution over the large, combinatorial output space of natural language. Translating this process to conformal prediction, we calibrate a stopping rule for sampling different outputs from the LM that get added to a growing set of candidates until we are confident that the output set is sufficient. Since some samples may be low-quality, we also simultaneously calibrate and apply a rejection rule for removing candidates from the output set to reduce noise. Similar to conformal prediction, we prove that the sampled set returned by our procedure contains at least one acceptable answer with high probability, while still being empirically precise (i.e., small) on average. Furthermore, within this set of candidate responses, we show that we can also accurately identify subsets of individual components -- such as phrases or sentences -- that are each independently correct (e.g., that are not "hallucinations"), again with statistical guarantees. We demonstrate the promise of our approach on multiple tasks in open-domain question answering, text summarization, and radiology report generation using different LM variants.
LAIT: Efficient Multi-Segment Encoding in Transformers with Layer-Adjustable Interaction
May 31, 2023



Transformer encoders contextualize token representations by attending to all other tokens at each layer, leading to quadratic increase in compute effort with the input length. In practice, however, the input text of many NLP tasks can be seen as a sequence of related segments (e.g., the sequence of sentences within a passage, or the hypothesis and premise in NLI). While attending across these segments is highly beneficial for many tasks, we hypothesize that this interaction can be delayed until later encoding stages. To this end, we introduce Layer-Adjustable Interactions in Transformers (LAIT). Within LAIT, segmented inputs are first encoded independently, and then jointly. This partial two-tower architecture bridges the gap between a Dual Encoder's ability to pre-compute representations for segments and a fully self-attentive Transformer's capacity to model cross-segment attention. The LAIT framework effectively leverages existing pretrained Transformers and converts them into the hybrid of the two aforementioned architectures, allowing for easy and intuitive control over the performance-efficiency tradeoff. Experimenting on a wide range of NLP tasks, we find LAIT able to reduce 30-50% of the attention FLOPs on many tasks, while preserving high accuracy; in some practical settings, LAIT could reduce actual latency by orders of magnitude.