 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntailed Between the Lines: Incorporating Implication into NLI
Jan 13, 2025Much of human communication depends on implication, conveying meaning beyond literal words to express a wider range of thoughts, intentions, and feelings. For models to better understand and facilitate human communication, they must be responsive to the text's implicit meaning. We focus on Natural Language Inference (NLI), a core tool for many language tasks, and find that state-of-the-art NLI models and datasets struggle to recognize a range of cases where entailment is implied, rather than explicit from the text. We formalize implied entailment as an extension of the NLI task and introduce the Implied NLI dataset (INLI) to help today's LLMs both recognize a broader variety of implied entailments and to distinguish between implicit and explicit entailment. We show how LLMs fine-tuned on INLI understand implied entailment and can generalize this understanding across datasets and domains.
Scalable and Domain-General Abstractive Proposition Segmentation
Jun 28, 2024Segmenting text into fine-grained units of meaning is important to a wide range of NLP applications. The default approach of segmenting text into sentences is often insufficient, especially since sentences are usually complex enough to include multiple units of meaning that merit separate treatment in the downstream task. We focus on the task of abstractive proposition segmentation: transforming text into simple, self-contained, well-formed sentences. Several recent works have demonstrated the utility of proposition segmentation with few-shot prompted LLMs for downstream tasks such as retrieval-augmented grounding and fact verification. However, this approach does not scale to large amounts of text and may not always extract all the facts from the input text. In this paper, we first introduce evaluation metrics for the task to measure several dimensions of quality. We then propose a scalable, yet accurate, proposition segmentation model. We model proposition segmentation as a supervised task by training LLMs on existing annotated datasets and show that training yields significantly improved results. We further show that by using the fine-tuned LLMs as teachers for annotating large amounts of multi-domain synthetic distillation data, we can train smaller student models with results similar to the teacher LLMs. We then demonstrate that our technique leads to effective domain generalization, by annotating data in two domains outside the original training data and evaluating on them. Finally, as a key contribution of the paper, we share an easy-to-use API for NLP practitioners to use.
A synthetic data approach for domain generalization of NLI models
Feb 19, 2024
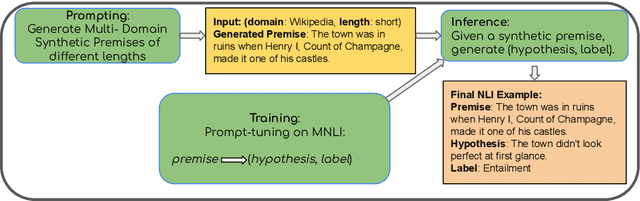


Natural Language Inference (NLI) remains an important benchmark task for LLMs. NLI datasets are a springboard for transfer learning to other semantic tasks, and NLI models are standard tools for identifying the faithfulness of model-generated text. There are several large scale NLI datasets today, and models have improved greatly by hill-climbing on these collections. Yet their realistic performance on out-of-distribution/domain data is less well-understood. We present an in-depth exploration of the problem of domain generalization of NLI models. We demonstrate a new approach for generating synthetic NLI data in diverse domains and lengths, so far not covered by existing training sets. The resulting examples have meaningful premises, the hypotheses are formed in creative ways rather than simple edits to a few premise tokens, and the labels have high accuracy. We show that models trained on this data ($685$K synthetic examples) have the best generalization to completely new downstream test settings. On the TRUE benchmark, a T5-small model trained with our data improves around $7\%$ on average compared to training on the best alternative dataset. The improvements are more pronounced for smaller models, while still meaningful on a T5 XXL model. We also demonstrate gains on test sets when in-domain training data is augmented with our domain-general synthetic data.
LAIT: Efficient Multi-Segment Encoding in Transformers with Layer-Adjustable Interaction
May 31, 2023



Transformer encoders contextualize token representations by attending to all other tokens at each layer, leading to quadratic increase in compute effort with the input length. In practice, however, the input text of many NLP tasks can be seen as a sequence of related segments (e.g., the sequence of sentences within a passage, or the hypothesis and premise in NLI). While attending across these segments is highly beneficial for many tasks, we hypothesize that this interaction can be delayed until later encoding stages. To this end, we introduce Layer-Adjustable Interactions in Transformers (LAIT). Within LAIT, segmented inputs are first encoded independently, and then jointly. This partial two-tower architecture bridges the gap between a Dual Encoder's ability to pre-compute representations for segments and a fully self-attentive Transformer's capacity to model cross-segment attention. The LAIT framework effectively leverages existing pretrained Transformers and converts them into the hybrid of the two aforementioned architectures, allowing for easy and intuitive control over the performance-efficiency tradeoff. Experimenting on a wide range of NLP tasks, we find LAIT able to reduce 30-50% of the attention FLOPs on many tasks, while preserving high accuracy; in some practical settings, LAIT could reduce actual latency by orders of magnitude.
Sources of Hallucination by Large Language Models on Inference Tasks
May 23, 2023
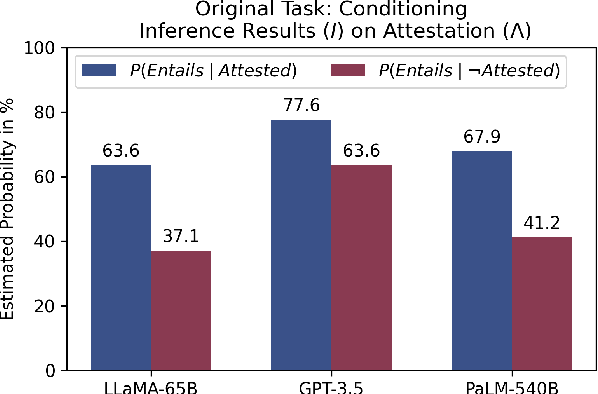

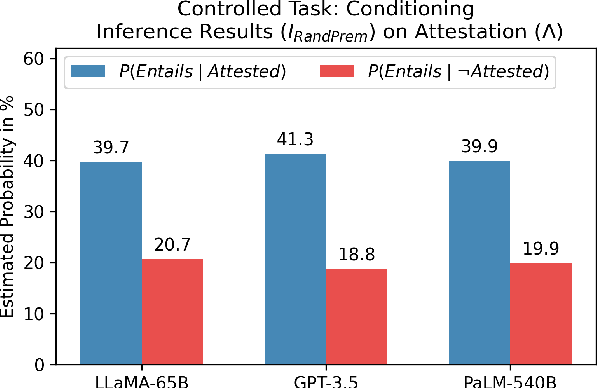
Large Language Models (LLMs) are claimed to be capable of Natural Language Inference (NLI), necessary for applied tasks like question answering and summarization, yet this capability is under-explored. We present a series of behavioral studies on several LLM families (LLaMA, GPT-3.5, and PaLM) which probe their behavior using controlled experiments. We establish two factors which predict much of their performance, and propose that these are major sources of hallucination in generative LLM. First, the most influential factor is memorization of the training data. We show that models falsely label NLI test samples as entailing when the hypothesis is attested in the training text, regardless of the premise. We further show that named entity IDs are used as "indices" to access the memorized data. Second, we show that LLMs exploit a further corpus-based heuristic using the relative frequencies of words. We show that LLMs score significantly worse on NLI test samples which do not conform to these factors than those which do; we also discuss a tension between the two factors, and a performance trade-off.
Resolving Indirect Referring Expressions for Entity Selection
Dec 21, 2022Recent advances in language modeling have enabled new conversational systems. In particular, it is often desirable for people to make choices among specified options when using such systems. We address the problem of reference resolution, when people use natural expressions to choose between real world entities. For example, given the choice `Should we make a Simnel cake or a Pandan cake?' a natural response from a non-expert may be indirect: `let's make the green one'. Reference resolution has been little studied with natural expressions, thus robustly understanding such language has large potential for improving naturalness in dialog, recommendation, and search systems. We create AltEntities (Alternative Entities), a new public dataset of entity pairs and utterances, and develop models for the disambiguation problem. Consisting of 42K indirect referring expressions across three domains, it enables for the first time the study of how large language models can be adapted to this task. We find they achieve 82%-87% accuracy in realistic settings, which while reasonable also invites further advances.
Language Models Are Poor Learners of Directional Inference
Oct 10, 2022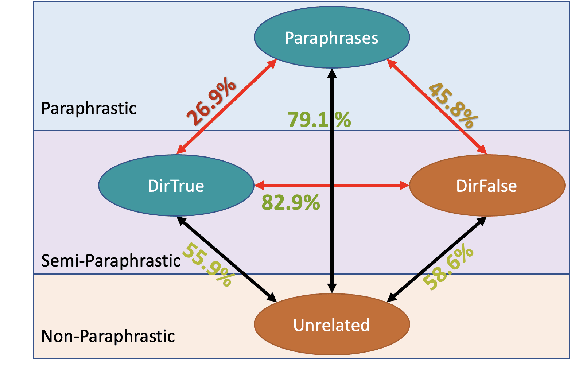
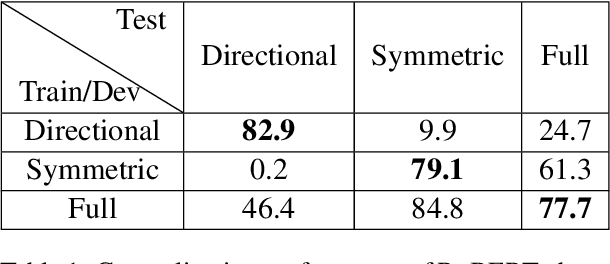
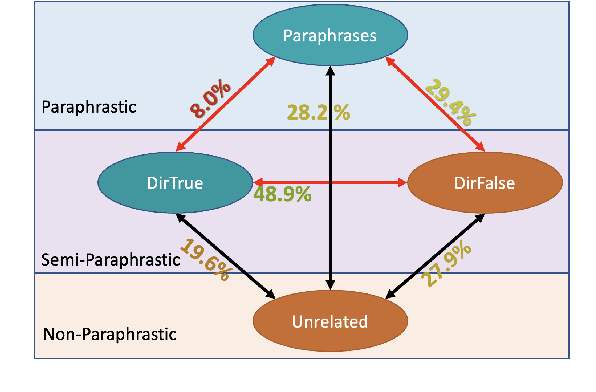
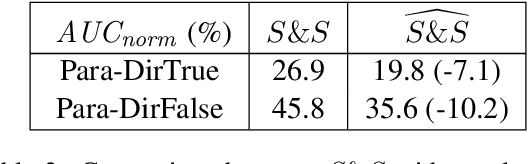
We examine LMs' competence of directional predicate entailments by supervised fine-tuning with prompts. Our analysis shows that contrary to their apparent success on standard NLI, LMs show limited ability to learn such directional inference; moreover, existing datasets fail to test directionality, and/or are infested by artefacts that can be learnt as proxy for entailments, yielding over-optimistic results. In response, we present BoOQA (Boolean Open QA), a robust multi-lingual evaluation benchmark for directional predicate entailments, extrinsic to existing training sets. On BoOQA, we establish baselines and show evidence of existing LM-prompting models being incompetent directional entailment learners, in contrast to entailment graphs, however limited by sparsity.
Cross-lingual Inference with A Chinese Entailment Graph
Mar 11, 2022
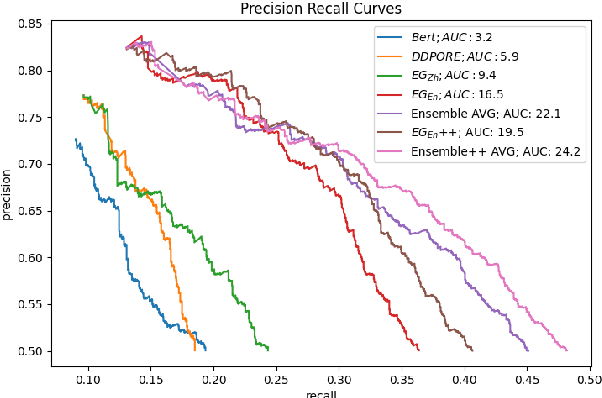
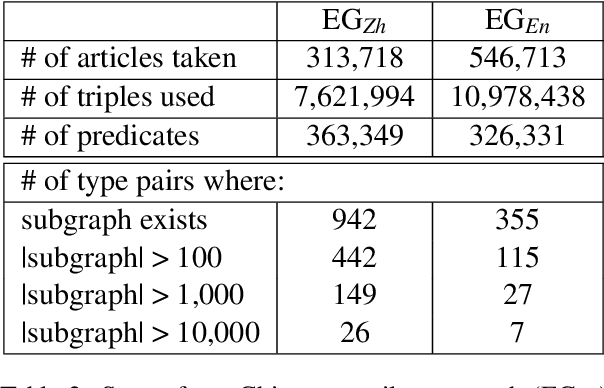
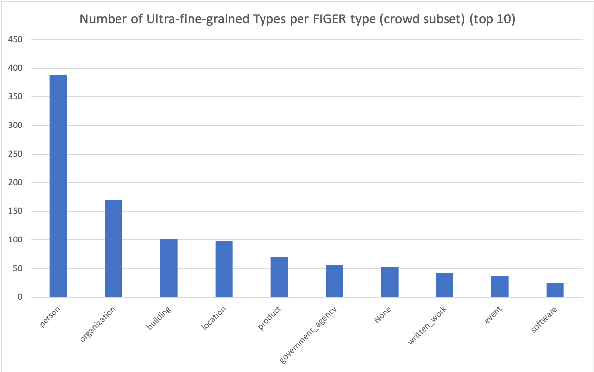
Predicate entailment detection is a crucial task for question-answering from text, where previous work has explored unsupervised learning of entailment graphs from typed open relation triples. In this paper, we present the first pipeline for building Chinese entailment graphs, which involves a novel high-recall open relation extraction (ORE) method and the first Chinese fine-grained entity typing dataset under the FIGER type ontology. Through experiments on the Levy-Holt dataset, we verify the strength of our Chinese entailment graph, and reveal the cross-lingual complementarity: on the parallel Levy-Holt dataset, an ensemble of Chinese and English entailment graphs outperforms both monolingual graphs, and raises unsupervised SOTA by 4.7 AUC points.
Incorporating Temporal Information in Entailment Graph Mining
Sep 20, 2021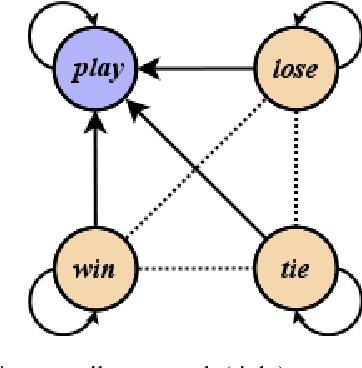
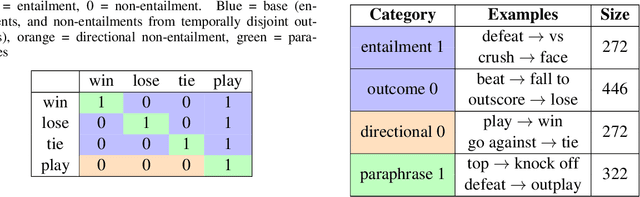
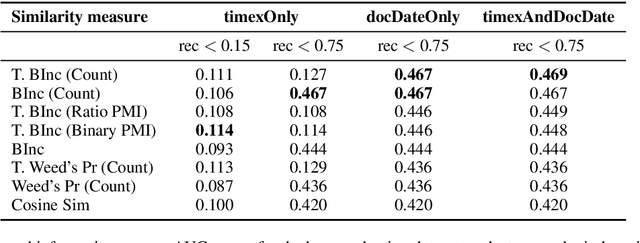
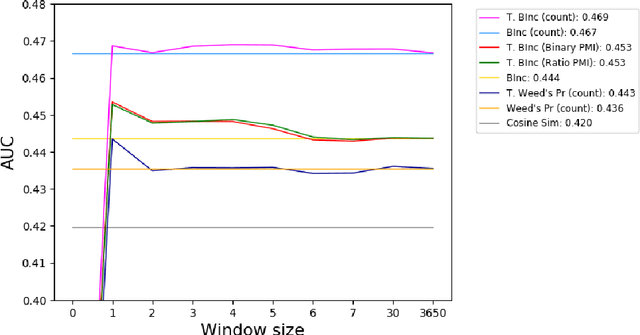
We present a novel method for injecting temporality into entailment graphs to address the problem of spurious entailments, which may arise from similar but temporally distinct events involving the same pair of entities. We focus on the sports domain in which the same pairs of teams play on different occasions, with different outcomes. We present an unsupervised model that aims to learn entailments such as win/lose $\rightarrow$ play, while avoiding the pitfall of learning non-entailments such as win $\not\rightarrow$ lose. We evaluate our model on a manually constructed dataset, showing that incorporating time intervals and applying a temporal window around them, are effective strategies.
* L. Guillou, S. Bijl de Vroe, M.J. Hosseini, M. Johnson, and M. Steedman. 2020. Incorporating temporal information in entailment graph mining. In Proceedings of the Graph-based Methods for Natural Language Processing (TextGraphs), pages 60-71, Barcelona, Spain (Online). Association for Computational Linguistics
Multivalent Entailment Graphs for Question Answering
Apr 16, 2021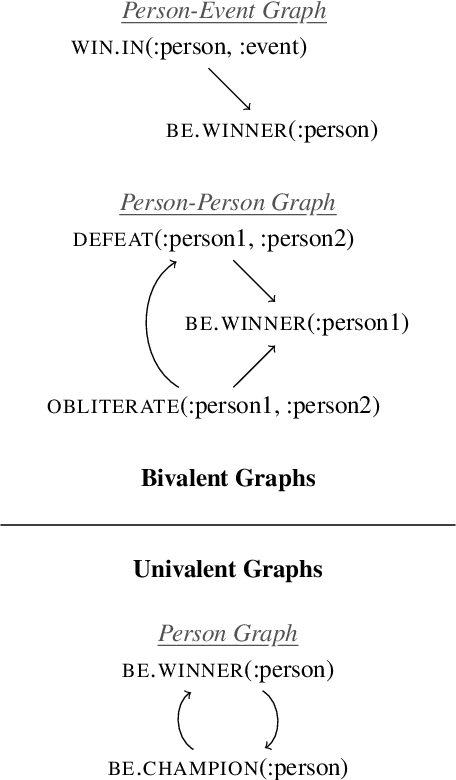
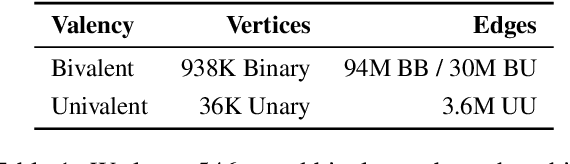

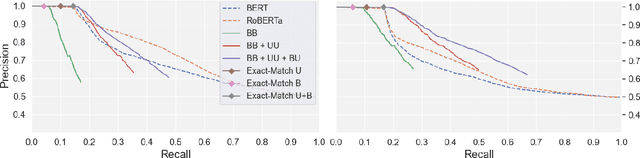
Drawing inferences between open-domain natural language predicates is a necessity for true language understanding. There has been much progress in unsupervised learning of entailment graphs for this purpose. We make three contributions: (1) we reinterpret the Distributional Inclusion Hypothesis to model entailment between predicates of different valencies, like DEFEAT(Biden, Trump) entails WIN(Biden); (2) we actualize this theory by learning unsupervised Multivalent Entailment Graphs of open-domain predicates; and (3) we demonstrate the capabilities of these graphs on a novel question answering task. We show that directional entailment is more helpful for inference than bidirectional similarity on questions of fine-grained semantics. We also show that drawing on evidence across valencies answers more questions than by using only the same valency evidence.