 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Seq2seq Coreference Resolution Using Entity Representations
Oct 16, 2025
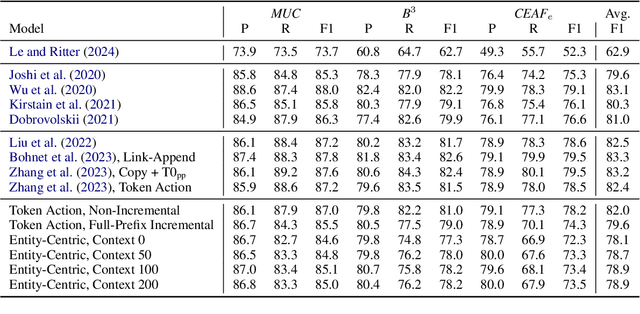
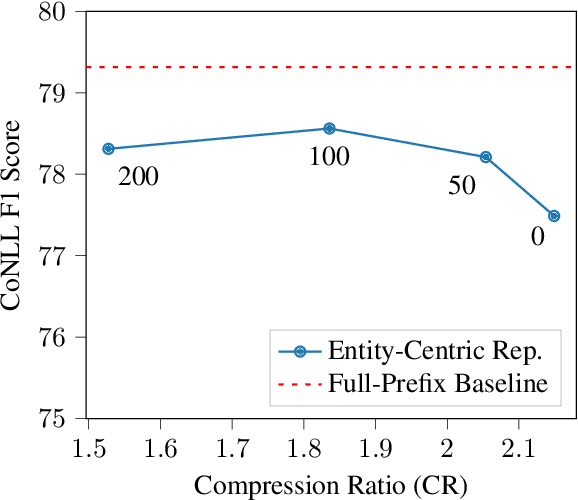
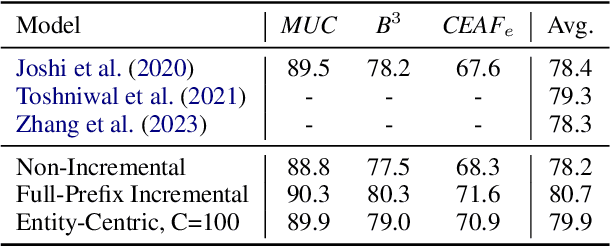
Seq2seq coreference models have introduced a new paradigm for coreference resolution by learning to generate text corresponding to coreference labels, without requiring task-specific parameters. While these models achieve new state-of-the-art performance, they do so at the cost of flexibility and efficiency. In particular, they do not efficiently handle incremental settings such as dialogue, where text must processed sequentially. We propose a compressed representation in order to improve the efficiency of these methods in incremental settings. Our method works by extracting and re-organizing entity-level tokens, and discarding the majority of other input tokens. On OntoNotes, our best model achieves just 0.6 CoNLL F1 points below a full-prefix, incremental baseline while achieving a compression ratio of 1.8. On LitBank, where singleton mentions are annotated, it passes state-of-the-art performance. Our results indicate that discarding a wide portion of tokens in seq2seq resolvers is a feasible strategy for incremental coreference resolution.
LLMs are Frequency Pattern Learners in Natural Language Inference
May 27, 2025



While fine-tuning LLMs on NLI corpora improves their inferential performance, the underlying mechanisms driving this improvement remain largely opaque. In this work, we conduct a series of experiments to investigate what LLMs actually learn during fine-tuning. We begin by analyzing predicate frequencies in premises and hypotheses across NLI datasets and identify a consistent frequency bias, where predicates in hypotheses occur more frequently than those in premises for positive instances. To assess the impact of this bias, we evaluate both standard and NLI fine-tuned LLMs on bias-consistent and bias-adversarial cases. We find that LLMs exploit frequency bias for inference and perform poorly on adversarial instances. Furthermore, fine-tuned LLMs exhibit significantly increased reliance on this bias, suggesting that they are learning these frequency patterns from datasets. Finally, we compute the frequencies of hyponyms and their corresponding hypernyms from WordNet, revealing a correlation between frequency bias and textual entailment. These findings help explain why learning frequency patterns can enhance model performance on inference tasks.
S2LPP: Small-to-Large Prompt Prediction across LLMs
May 26, 2025



The performance of pre-trained Large Language Models (LLMs) is often sensitive to nuances in prompt templates, requiring careful prompt engineering, adding costs in terms of computing and human effort. In this study, we present experiments encompassing multiple LLMs variants of varying sizes aimed at probing their preference with different prompts. Through experiments on Question Answering, we show prompt preference consistency across LLMs of different sizes. We also show that this consistency extends to other tasks, such as Natural Language Inference. Utilizing this consistency, we propose a method to use a smaller model to select effective prompt templates for a larger model. We show that our method substantially reduces the cost of prompt engineering while consistently matching performance with optimal prompts among candidates. More importantly, our experiment shows the efficacy of our strategy across fourteen LLMs and its applicability to a broad range of NLP tasks, highlighting its robustness
MMLongBench: Benchmarking Long-Context Vision-Language Models Effectively and Thoroughly
May 15, 2025The rapid extension of context windows in large vision-language models has given rise to long-context vision-language models (LCVLMs), which are capable of handling hundreds of images with interleaved text tokens in a single forward pass. In this work, we introduce MMLongBench, the first benchmark covering a diverse set of long-context vision-language tasks, to evaluate LCVLMs effectively and thoroughly. MMLongBench is composed of 13,331 examples spanning five different categories of downstream tasks, such as Visual RAG and Many-Shot ICL. It also provides broad coverage of image types, including various natural and synthetic images. To assess the robustness of the models to different input lengths, all examples are delivered at five standardized input lengths (8K-128K tokens) via a cross-modal tokenization scheme that combines vision patches and text tokens. Through a thorough benchmarking of 46 closed-source and open-source LCVLMs, we provide a comprehensive analysis of the current models' vision-language long-context ability. Our results show that: i) performance on a single task is a weak proxy for overall long-context capability; ii) both closed-source and open-source models face challenges in long-context vision-language tasks, indicating substantial room for future improvement; iii) models with stronger reasoning ability tend to exhibit better long-context performance. By offering wide task coverage, various image types, and rigorous length control, MMLongBench provides the missing foundation for diagnosing and advancing the next generation of LCVLMs.
Modelling Child Learning and Parsing of Long-range Syntactic Dependencies
Mar 17, 2025


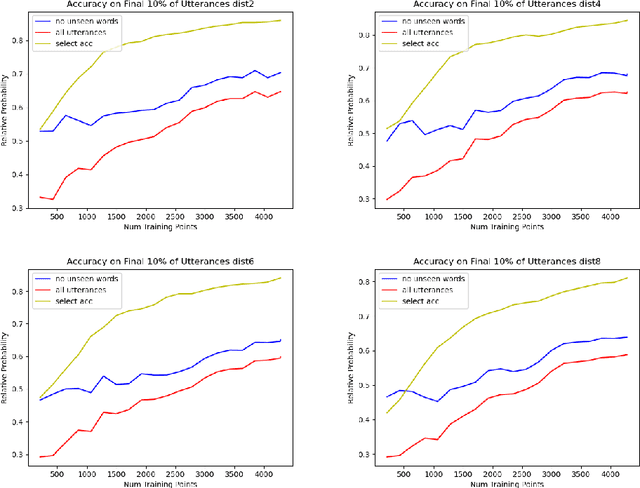
This work develops a probabilistic child language acquisition model to learn a range of linguistic phenonmena, most notably long-range syntactic dependencies of the sort found in object wh-questions, among other constructions. The model is trained on a corpus of real child-directed speech, where each utterance is paired with a logical form as a meaning representation. It then learns both word meanings and language-specific syntax simultaneously. After training, the model can deduce the correct parse tree and word meanings for a given utterance-meaning pair, and can infer the meaning if given only the utterance. The successful modelling of long-range dependencies is theoretically important because it exploits aspects of the model that are, in general, trans-context-free.
Neutralizing Bias in LLM Reasoning using Entailment Graphs
Mar 14, 2025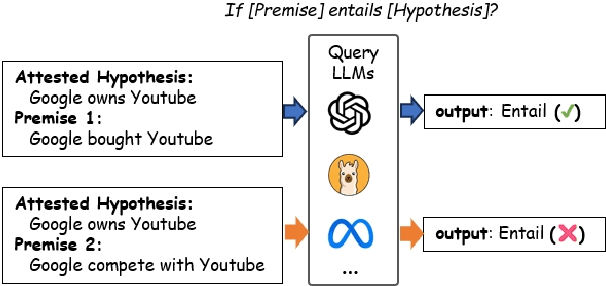


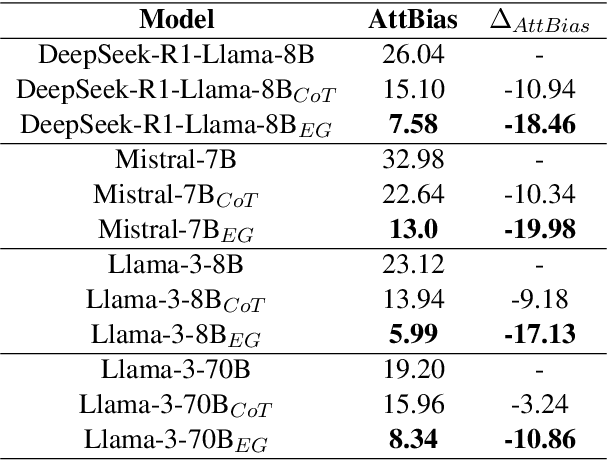
LLMs are often claimed to be capable of Natural Language Inference (NLI), which is widely regarded as a cornerstone of more complex forms of reasoning. However, recent works show that LLMs still suffer from hallucinations in NLI due to attestation bias, where LLMs overly rely on propositional memory to build shortcuts. To solve the issue, we design an unsupervised framework to construct counterfactual reasoning data and fine-tune LLMs to reduce attestation bias. To measure bias reduction, we build bias-adversarial variants of NLI datasets with randomly replaced predicates in premises while keeping hypotheses unchanged. Extensive evaluations show that our framework can significantly reduce hallucinations from attestation bias. Then, we further evaluate LLMs fine-tuned with our framework on original NLI datasets and their bias-neutralized versions, where original entities are replaced with randomly sampled ones. Extensive results show that our framework consistently improves inferential performance on both original and bias-neutralized NLI datasets.
Concept-Reversed Winograd Schema Challenge: Evaluating and Improving Robust Reasoning in Large Language Models via Abstraction
Oct 15, 2024



While Large Language Models (LLMs) have showcased remarkable proficiency in reasoning, there is still a concern about hallucinations and unreliable reasoning issues due to semantic associations and superficial logical chains. To evaluate the extent to which LLMs perform robust reasoning instead of relying on superficial logical chains, we propose a new evaluation dataset, the Concept-Reversed Winograd Schema Challenge (CR-WSC), based on the famous Winograd Schema Challenge (WSC) dataset. By simply reversing the concepts to those that are more associated with the wrong answer, we find that the performance of LLMs drops significantly despite the rationale of reasoning remaining the same. Furthermore, we propose Abstraction-of-Thought (AoT), a novel prompt method for recovering adversarial cases to normal cases using conceptual abstraction to improve LLMs' robustness and consistency in reasoning, as demonstrated by experiments on CR-WSC.
Explicit Inductive Inference using Large Language Models
Aug 26, 2024



Large Language Models (LLMs) are reported to hold undesirable attestation bias on inference tasks: when asked to predict if a premise P entails a hypothesis H, instead of considering H's conditional truthfulness entailed by P, LLMs tend to use the out-of-context truth label of H as a fragile proxy. In this paper, we propose a pipeline that exploits this bias to do explicit inductive inference. Our pipeline uses an LLM to transform a premise into a set of attested alternatives, and then aggregate answers of the derived new entailment inquiries to support the original inference prediction. On a directional predicate entailment benchmark, we demonstrate that by applying this simple pipeline, we can improve the overall performance of LLMs on inference and substantially alleviate the impact of their attestation bias.
A Language-agnostic Model of Child Language Acquisition
Aug 22, 2024



This work reimplements a recent semantic bootstrapping child-language acquisition model, which was originally designed for English, and trains it to learn a new language: Hebrew. The model learns from pairs of utterances and logical forms as meaning representations, and acquires both syntax and word meanings simultaneously. The results show that the model mostly transfers to Hebrew, but that a number of factors, including the richer morphology in Hebrew, makes the learning slower and less robust. This suggests that a clear direction for future work is to enable the model to leverage the similarities between different word forms.
A Usage-centric Take on Intent Understanding in E-Commerce
Feb 22, 2024
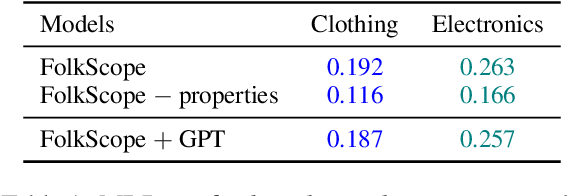
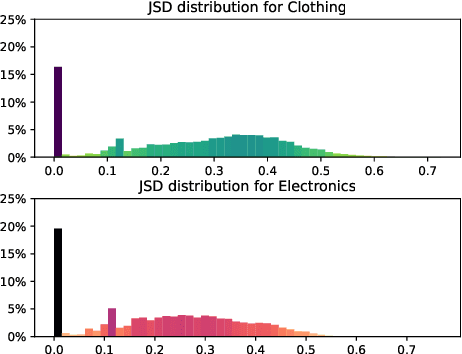
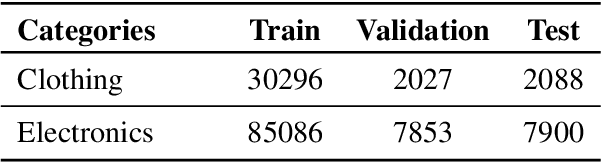
Identifying and understanding user intents is a pivotal task for E-Commerce. Despite its popularity, intent understanding has not been consistently defined or accurately benchmarked. In this paper, we focus on predicative user intents as "how a customer uses a product", and pose intent understanding as a natural language reasoning task, independent of product ontologies. We identify two weaknesses of FolkScope, the SOTA E-Commerce Intent Knowledge Graph, that limit its capacity to reason about user intents and to recommend diverse useful products. Following these observations, we introduce a Product Recovery Benchmark including a novel evaluation framework and an example dataset. We further validate the above FolkScope weaknesses on this benchmark.