 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Representation Fairness in Long-Document Embeddings: The Peculiar Interaction of Positional and Language Bias
Jan 23, 2026To be discoverable in an embedding-based search process, each part of a document should be reflected in its embedding representation. To quantify any potential reflection biases, we introduce a permutation-based evaluation framework. With this, we observe that state-of-the-art embedding models exhibit systematic positional and language biases when documents are longer and consist of multiple segments. Specifically, early segments and segments in higher-resource languages like English are over-represented, while later segments and segments in lower-resource languages are marginalized. In our further analysis, we find that the positional bias stems from front-loaded attention distributions in pooling-token embeddings, where early tokens receive more attention. To mitigate this issue, we introduce an inference-time attention calibration method that redistributes attention more evenly across document positions, increasing discoverabiltiy of later segments. Our evaluation framework and attention calibration is available at https://github.com/impresso/fair-sentence-transformers
SwissGov-RSD: A Human-annotated, Cross-lingual Benchmark for Token-level Recognition of Semantic Differences Between Related Documents
Dec 08, 2025Recognizing semantic differences across documents, especially in different languages, is crucial for text generation evaluation and multilingual content alignment. However, as a standalone task it has received little attention. We address this by introducing SwissGov-RSD, the first naturalistic, document-level, cross-lingual dataset for semantic difference recognition. It encompasses a total of 224 multi-parallel documents in English-German, English-French, and English-Italian with token-level difference annotations by human annotators. We evaluate a variety of open-source and closed source large language models as well as encoder models across different fine-tuning settings on this new benchmark. Our results show that current automatic approaches perform poorly compared to their performance on monolingual, sentence-level, and synthetic benchmarks, revealing a considerable gap for both LLMs and encoder models. We make our code and datasets publicly available.
Parity-Aware Byte-Pair Encoding: Improving Cross-lingual Fairness in Tokenization
Aug 06, 2025



Tokenization is the first -- and often least scrutinized -- step of most NLP pipelines. Standard algorithms for learning tokenizers rely on frequency-based objectives, which favor languages dominant in the training data and consequently leave lower-resource languages with tokenizations that are disproportionately longer, morphologically implausible, or even riddled with <UNK> placeholders. This phenomenon ultimately amplifies computational and financial inequalities between users from different language backgrounds. To remedy this, we introduce Parity-aware Byte Pair Encoding (BPE), a variant of the widely-used BPE algorithm. At every merge step, Parity-aware BPE maximizes the compression gain of the currently worst-compressed language, trading a small amount of global compression for cross-lingual parity. We find empirically that Parity-aware BPE leads to more equitable token counts across languages, with negligible impact on global compression rate and no substantial effect on language-model performance in downstream tasks.
20min-XD: A Comparable Corpus of Swiss News Articles
Apr 30, 2025We present 20min-XD (20 Minuten cross-lingual document-level), a French-German, document-level comparable corpus of news articles, sourced from the Swiss online news outlet 20 Minuten/20 minutes. Our dataset comprises around 15,000 article pairs spanning 2015 to 2024, automatically aligned based on semantic similarity. We detail the data collection process and alignment methodology. Furthermore, we provide a qualitative and quantitative analysis of the corpus. The resulting dataset exhibits a broad spectrum of cross-lingual similarity, ranging from near-translations to loosely related articles, making it valuable for various NLP applications and broad linguistically motivated studies. We publicly release the dataset in document- and sentence-aligned versions and code for the described experiments.
CHARM: Calibrating Reward Models With Chatbot Arena Scores
Apr 14, 2025Reward models (RMs) play a crucial role in Reinforcement Learning from Human Feedback by serving as proxies for human preferences in aligning large language models. In this paper, we identify a model preference bias in RMs, where they systematically assign disproportionately high scores to responses from certain policy models. This bias distorts ranking evaluations and leads to unfair judgments. To address this issue, we propose a calibration method named CHatbot Arena calibrated Reward Modeling (CHARM) that leverages Elo scores from the Chatbot Arena leaderboard to mitigate RM overvaluation. We also introduce a Mismatch Degree metric to measure this preference bias. Our approach is computationally efficient, requiring only a small preference dataset for continued training of the RM. We conduct extensive experiments on reward model benchmarks and human preference alignment. Results demonstrate that our calibrated RMs (1) achieve improved evaluation accuracy on RM-Bench and the Chat-Hard domain of RewardBench, and (2) exhibit a stronger correlation with human preferences by producing scores more closely aligned with Elo rankings. By mitigating model preference bias, our method provides a generalizable and efficient solution for building fairer and more reliable reward models.
Source-primed Multi-turn Conversation Helps Large Language Models Translate Documents
Mar 13, 2025LLMs have paved the way for truly simple document-level machine translation, but challenges such as omission errors remain. In this paper, we study a simple method for handling document-level machine translation, by leveraging previous contexts in a multi-turn conversational manner. Specifically, by decomposing documents into segments and iteratively translating them while maintaining previous turns, this method ensures coherent translations without additional training, and can fully re-use the KV cache of previous turns thus minimizing computational overhead. We further propose a `source-primed' method that first provides the whole source document before multi-turn translation. We empirically show this multi-turn method outperforms both translating entire documents in a single turn and translating each segment independently according to multiple automatic metrics in representative LLMs, establishing a strong baseline for document-level translation using LLMs.
Examining Multilingual Embedding Models Cross-Lingually Through LLM-Generated Adversarial Examples
Feb 12, 2025
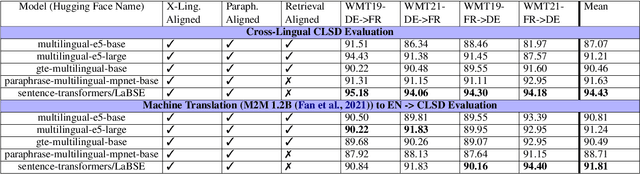
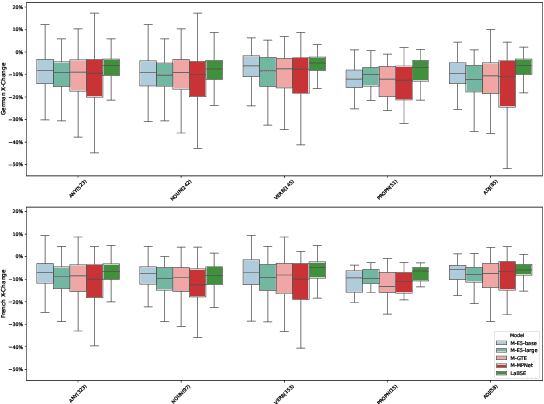

The evaluation of cross-lingual semantic search capabilities of models is often limited to existing datasets from tasks such as information retrieval and semantic textual similarity. To allow for domain-specific evaluation, we introduce Cross Lingual Semantic Discrimination (CLSD), a novel cross-lingual semantic search task that requires only a set of parallel sentence pairs of the language pair of interest within the target domain. This task focuses on the ability of a model to cross-lingually rank the true parallel sentence higher than hard negatives generated by a large language model. We create four instances of our introduced CLSD task for the language pair German-French within the domain of news. Within this case study, we find that models that are also fine-tuned for retrieval tasks (e.g., multilingual E5) benefit from using English as the pivot language, while bitext mining models such as LaBSE perform best directly cross-lingually. We also show a fine-grained similarity analysis enabled by our distractor generation strategy, indicating that different embedding models are sensitive to different types of perturbations.
Evaluating Automatic Metrics with Incremental Machine Translation Systems
Jul 03, 2024



We introduce a dataset comprising commercial machine translations, gathered weekly over six years across 12 translation directions. Since human A/B testing is commonly used, we assume commercial systems improve over time, which enables us to evaluate machine translation (MT) metrics based on their preference for more recent translations. Our study confirms several previous findings in MT metrics research and demonstrates the dataset's value as a testbed for metric evaluation. We release our code at https://github.com/gjwubyron/Evo
SignCLIP: Connecting Text and Sign Language by Contrastive Learning
Jul 01, 2024

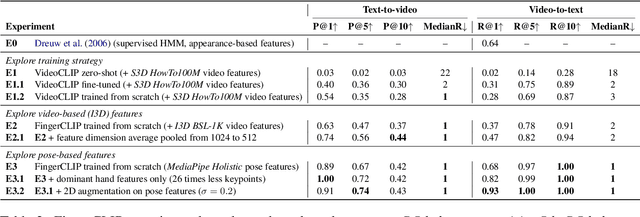

We present SignCLIP, which re-purposes CLIP (Contrastive Language-Image Pretraining) to project spoken language text and sign language videos, two classes of natural languages of distinct modalities, into the same space. SignCLIP is an efficient method of learning useful visual representations for sign language processing from large-scale, multilingual video-text pairs, without directly optimizing for a specific task or sign language which is often of limited size. We pretrain SignCLIP on Spreadthesign, a prominent sign language dictionary consisting of ~500 thousand video clips in up to 44 sign languages, and evaluate it with various downstream datasets. SignCLIP discerns in-domain signing with notable text-to-video/video-to-text retrieval accuracy. It also performs competitively for out-of-domain downstream tasks such as isolated sign language recognition upon essential few-shot prompting or fine-tuning. We analyze the latent space formed by the spoken language text and sign language poses, which provides additional linguistic insights. Our code and models are openly available.
An Analysis of BPE Vocabulary Trimming in Neural Machine Translation
Mar 30, 2024We explore threshold vocabulary trimming in Byte-Pair Encoding subword tokenization, a postprocessing step that replaces rare subwords with their component subwords. The technique is available in popular tokenization libraries but has not been subjected to rigorous scientific scrutiny. While the removal of rare subwords is suggested as best practice in machine translation implementations, both as a means to reduce model size and for improving model performance through robustness, our experiments indicate that, across a large space of hyperparameter settings, vocabulary trimming fails to improve performance, and is even prone to incurring heavy degradation.