 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Distributional Learning with Non-crossing Quantile Network
Apr 11, 2025In this paper, we introduce a non-crossing quantile (NQ) network for conditional distribution learning. By leveraging non-negative activation functions, the NQ network ensures that the learned distributions remain monotonic, effectively addressing the issue of quantile crossing. Furthermore, the NQ network-based deep distributional learning framework is highly adaptable, applicable to a wide range of applications, from classical non-parametric quantile regression to more advanced tasks such as causal effect estimation and distributional reinforcement learning (RL). We also develop a comprehensive theoretical foundation for the deep NQ estimator and its application to distributional RL, providing an in-depth analysis that demonstrates its effectiveness across these domains. Our experimental results further highlight the robustness and versatility of the NQ network.
Evaluating Automatic Metrics with Incremental Machine Translation Systems
Jul 03, 2024



We introduce a dataset comprising commercial machine translations, gathered weekly over six years across 12 translation directions. Since human A/B testing is commonly used, we assume commercial systems improve over time, which enables us to evaluate machine translation (MT) metrics based on their preference for more recent translations. Our study confirms several previous findings in MT metrics research and demonstrates the dataset's value as a testbed for metric evaluation. We release our code at https://github.com/gjwubyron/Evo
ICU: Conquering Language Barriers in Vision-and-Language Modeling by Dividing the Tasks into Image Captioning and Language Understanding
Oct 20, 2023



Most multilingual vision-and-language (V&L) research aims to accomplish multilingual and multimodal capabilities within one model. However, the scarcity of multilingual captions for images has hindered the development. To overcome this obstacle, we propose ICU, Image Caption Understanding, which divides a V&L task into two stages: a V&L model performs image captioning in English, and a multilingual language model (mLM), in turn, takes the caption as the alt text and performs crosslingual language understanding. The burden of multilingual processing is lifted off V&L model and placed on mLM. Since the multilingual text data is relatively of higher abundance and quality, ICU can facilitate the conquering of language barriers for V&L models. In experiments on two tasks across 9 languages in the IGLUE benchmark, we show that ICU can achieve new state-of-the-art results for five languages, and comparable results for the rest.
Representations of Domains via CF-approximation Spaces
Nov 19, 2022Representations of domains mean in a general way representing a domain as a suitable family endowed with set-inclusion order of some mathematical structures. In this paper, representations of domains via CF-approximation spaces are considered. Concepts of CF-approximation spaces and CF-closed sets are introduced. It is proved that the family of CF-closed sets in a CF-approximation space endowed with set-inclusion order is a continuous domain and that every continuous domain is isomorphic to the family of CF-closed sets of some CF-approximation space endowed with set-inclusion order. The concept of CF-approximable relations is introduced using a categorical approach, which later facilitates the proof that the category of CF-approximation spaces and CF-approximable relations is equivalent to that of continuous domains and Scott continuous maps.
Rating Facts under Coarse-to-fine Regimes
Jul 14, 2021
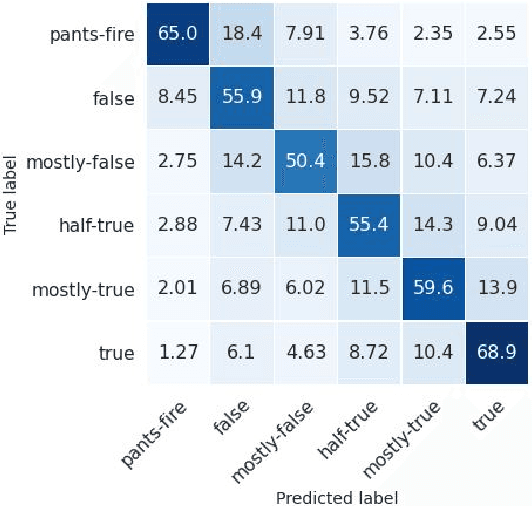
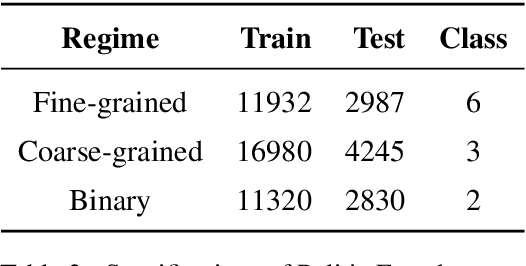

The rise of manipulating fake news as a political weapon has become a global concern and highlighted the incapability of manually fact checking against rapidly produced fake news. Thus, statistical approaches are required if we are to address this problem efficiently. The shortage of publicly available datasets is one major bottleneck of automated fact checking. To remedy this, we collected 24K manually rated statements from PolitiFact. The class values exhibit a natural order with respect to truthfulness as shown in Table 1. Thus, our task represents a twist from standard classification, due to the various degrees of similarity between classes. To investigate this, we defined coarse-to-fine classification regimes, which presents new challenge for classification. To address this, we propose BERT-based models. After training, class similarity is sensible over the multi-class datasets, especially in the fine-grained one. Under all the regimes, BERT achieves state of the art, while the additional layers provide insignificant improvement.
Reward Advancement: Transforming Policy under Maximum Causal Entropy Principle
Jul 11, 2019
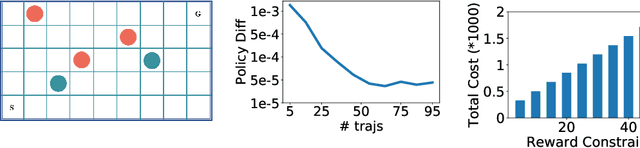
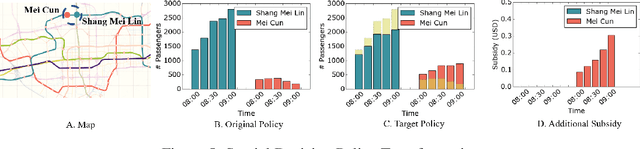
Many real-world human behaviors can be characterized as a sequential decision making processes, such as urban travelers choices of transport modes and routes (Wu et al. 2017). Differing from choices controlled by machines, which in general follows perfect rationality to adopt the policy with the highest reward, studies have revealed that human agents make sub-optimal decisions under bounded rationality (Tao, Rohde, and Corcoran 2014). Such behaviors can be modeled using maximum causal entropy (MCE) principle (Ziebart 2010). In this paper, we define and investigate a general reward trans-formation problem (namely, reward advancement): Recovering the range of additional reward functions that transform the agent's policy from original policy to a predefined target policy under MCE principle. We show that given an MDP and a target policy, there are infinite many additional reward functions that can achieve the desired policy transformation. Moreover, we propose an algorithm to further extract the additional rewards with minimum "cost" to implement the policy transformation.