 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall RL Controller, Large Language Model: RL-Guided Adaptive Sampling for Test-Time Scaling
Jun 02, 2026Test-time scaling improves the reasoning performance of large language models but incurs substantial cost in both total computation and latency. Existing adaptive sampling methods partially mitigate this issue by dynamically deciding when to stop sampling, yet they typically rely on heuristic rules or rely on distribution assumptions. In this work, we formulate adaptive sampling as a Markov decision process (MDP). We train a lightweight sampling controller with reinforcement learning (RL) to jointly balance answer correctness, latency, and computation cost. At each round, the controller decides to stop sampling or to acquire additional samples. Our method is lightweight which only relies on statistics of final answers, and can be trained and deployed on CPU. We further show that the resulting framework admits an interpretation as the Lagrangian relaxation of a constrained optimization problem with explicit budget constraints. Experiments against strong baselines such as ASC and ESC show that our method achieves improved trade-offs among answer correctness, sampling rounds, and total samples required.
AutoResearchClaw: Self-Reinforcing Autonomous Research with Human-AI Collaboration
May 19, 2026Automating scientific discovery requires more than generating papers from ideas. Real research is iterative: hypotheses are challenged from multiple perspectives, experiments fail and inform the next attempt, and lessons accumulate across cycles. Existing autonomous research systems often model this process as a linear pipeline: they rely on single-agent reasoning, stop when execution fails, and do not carry experience across runs. We present AutoResearchClaw, a multi-agent autonomous research pipeline built on five mechanisms: structured multi-agent debate for hypothesis generation and result analysis, a self-healing executor with a \textsc{Pivot}/\textsc{Refine} decision loop that transforms failures into information, verifiable result reporting that prevents fabricated numbers and hallucinated citations, human-in-the-loop collaboration with seven intervention modes spanning full autonomy to step-by-step oversight, and cross-run evolution that converts past mistakes into future safeguards. On ARC-Bench, a 25-topic experiment-stage benchmark, AutoResearchClaw outperforms AI Scientist v2 by 54.7%. A human-in-the-loop ablation across seven intervention modes reveals that precise, targeted collaboration at high-leverage decision points consistently outperforms both full autonomy and exhaustive step-by-step oversight. We position AutoResearchClaw as a research amplifier that augments rather than replaces human scientific judgment. Code is available at https://github.com/aiming-lab/AutoResearchClaw.
Robust Sequential Experimental Design for A/B Testing
May 13, 2026Experimental design has emerged as a powerful approach for improving the sample efficiency of A/B testing, yet existing designs rely critically on correctly specified models. We study robust sequential experimental design under model misspecification and develop a unified framework that covers both contextual bandit and dynamic settings. Theoretically, we prove that our design bounds the worst-case mean squared error of the estimated treatment effect. Empirically, we demonstrate the effectiveness of the proposed approach using synthetic and real-world datasets from a leading technology company.
Evidence-Based Actor-Verifier Reasoning for Echocardiographic Agents
Apr 07, 2026Echocardiography plays an important role in the screening and diagnosis of cardiovascular diseases. However, automated intelligent analysis of echocardiographic data remains challenging due to complex cardiac dynamics and strong view heterogeneity. In recent years, visual language models (VLM) have opened a new avenue for building ultrasound understanding systems for clinical decision support. Nevertheless, most existing methods formulate this task as a direct mapping from video and question to answer, making them vulnerable to template shortcuts and spurious explanations. To address these issues, we propose EchoTrust, an evidence-driven Actor-Verifier framework for trustworthy reasoning in echocardiography VLM-based agents. EchoTrust produces a structured intermediate representation that is subsequently analyzed by distinct roles, enabling more reliable and interpretable decision-making for high-stakes clinical applications.
Statistical Opportunities in Neuroimaging
Feb 13, 2026Neuroimaging has profoundly enhanced our understanding of the human brain by characterizing its structure, function, and connectivity through modalities like MRI, fMRI, EEG, and PET. These technologies have enabled major breakthroughs across the lifespan, from early brain development to neurodegenerative and neuropsychiatric disorders. Despite these advances, the brain is a complex, multiscale system, and neuroimaging measurements are correspondingly high-dimensional. This creates major statistical challenges, including measurement noise, motion-related artifacts, substantial inter-subject and site/scanner variability, and the sheer scale of modern studies. This paper explores statistical opportunities and challenges in neuroimaging across four key areas: (i) brain development from birth to age 20, (ii) the adult and aging brain, (iii) neurodegeneration and neuropsychiatric disorders, and (iv) brain encoding and decoding. After a quick tutorial on major imaging technologies, we review cutting-edge studies, underscore data and modeling challenges, and highlight research opportunities for statisticians. We conclude by emphasizing that close collaboration among statisticians, neuroscientists, and clinicians is essential for translating neuroimaging advances into improved diagnostics, deeper mechanistic insight, and more personalized treatments.
MedVerse: Efficient and Reliable Medical Reasoning via DAG-Structured Parallel Execution
Feb 07, 2026Large language models (LLMs) have demonstrated strong performance and rapid progress in a wide range of medical reasoning tasks. However, their sequential autoregressive decoding forces inherently parallel clinical reasoning, such as differential diagnosis, into a single linear reasoning path, limiting both efficiency and reliability for complex medical problems. To address this, we propose MedVerse, a reasoning framework for complex medical inference that reformulates medical reasoning as a parallelizable directed acyclic graph (DAG) process based on Petri net theory. The framework adopts a full-stack design across data, model architecture, and system execution. For data creation, we introduce the MedVerse Curator, an automated pipeline that synthesizes knowledge-grounded medical reasoning paths and transforms them into Petri net-structured representations. At the architectural level, we propose a topology-aware attention mechanism with adaptive position indices that supports parallel reasoning while preserving logical consistency. Systematically, we develop a customized inference engine that supports parallel execution without additional overhead. Empirical evaluations show that MedVerse improves strong general-purpose LLMs by up to 8.9%. Compared to specialized medical LLMs, MedVerse achieves comparable performance while delivering a 1.3x reduction in inference latency and a 1.7x increase in generation throughput, enabled by its parallel decoding capability.
Parallel-Probe: Towards Efficient Parallel Thinking via 2D Probing
Feb 03, 2026Parallel thinking has emerged as a promising paradigm for reasoning, yet it imposes significant computational burdens. Existing efficiency methods primarily rely on local, per-trajectory signals and lack principled mechanisms to exploit global dynamics across parallel branches. We introduce 2D probing, an interface that exposes the width-depth dynamics of parallel thinking by periodically eliciting intermediate answers from all branches. Our analysis reveals three key insights: non-monotonic scaling across width-depth allocations, heterogeneous reasoning branch lengths, and early stabilization of global consensus. Guided by these insights, we introduce $\textbf{Parallel-Probe}$, a training-free controller designed to optimize online parallel thinking. Parallel-Probe employs consensus-based early stopping to regulate reasoning depth and deviation-based branch pruning to dynamically adjust width. Extensive experiments across three benchmarks and multiple models demonstrate that Parallel-Probe establishes a superior Pareto frontier for test-time scaling. Compared to standard majority voting, it reduces sequential tokens by up to $\textbf{35.8}$% and total token cost by over $\textbf{25.8}$% while maintaining competitive accuracy.
Designing Time Series Experiments in A/B Testing with Transformer Reinforcement Learning
Feb 02, 2026A/B testing has become a gold standard for modern technological companies to conduct policy evaluation. Yet, its application to time series experiments, where policies are sequentially assigned over time, remains challenging. Existing designs suffer from two limitations: (i) they do not fully leverage the entire history for treatment allocation; (ii) they rely on strong assumptions to approximate the objective function (e.g., the mean squared error of the estimated treatment effect) for optimizing the design. We first establish an impossibility theorem showing that failure to condition on the full history leads to suboptimal designs, due to the dynamic dependencies in time series experiments. To address both limitations simultaneously, we next propose a transformer reinforcement learning (RL) approach which leverages transformers to condition allocation on the entire history and employs RL to directly optimize the MSE without relying on restrictive assumptions. Empirical evaluations on synthetic data, a publicly available dispatch simulator, and a real-world ridesharing dataset demonstrate that our proposal consistently outperforms existing designs.
"Rebuilding" Statistics in the Age of AI: A Town Hall Discussion on Culture, Infrastructure, and Training
Jan 24, 2026This article presents the full, original record of the 2024 Joint Statistical Meetings (JSM) town hall, "Statistics in the Age of AI," which convened leading statisticians to discuss how the field is evolving in response to advances in artificial intelligence, foundation models, large-scale empirical modeling, and data-intensive infrastructures. The town hall was structured around open panel discussion and extensive audience Q&A, with the aim of eliciting candid, experience-driven perspectives rather than formal presentations or prepared statements. This document preserves the extended exchanges among panelists and audience members, with minimal editorial intervention, and organizes the conversation around five recurring questions concerning disciplinary culture and practices, data curation and "data work," engagement with modern empirical modeling, training for large-scale AI applications, and partnerships with key AI stakeholders. By providing an archival record of this discussion, the preprint aims to support transparency, community reflection, and ongoing dialogue about the evolving role of statistics in the data- and AI-centric future.
CDE: Curiosity-Driven Exploration for Efficient Reinforcement Learning in Large Language Models
Sep 11, 2025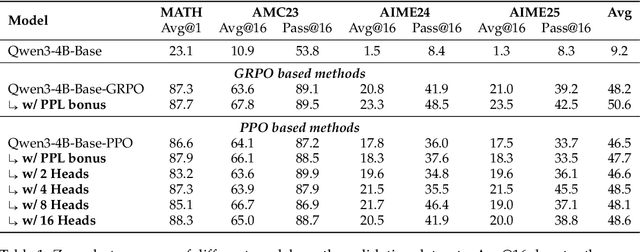
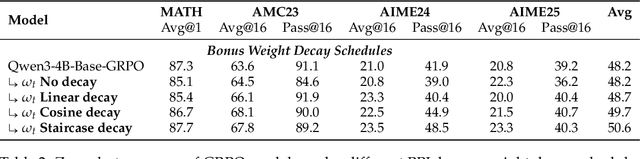
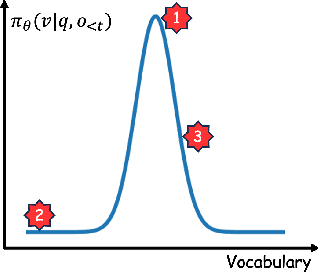

Reinforcement Learning with Verifiable Rewards (RLVR) is a powerful paradigm for enhancing the reasoning ability of Large Language Models (LLMs). Yet current RLVR methods often explore poorly, leading to premature convergence and entropy collapse. To address this challenge, we introduce Curiosity-Driven Exploration (CDE), a framework that leverages the model's own intrinsic sense of curiosity to guide exploration. We formalize curiosity with signals from both the actor and the critic: for the actor, we use perplexity over its generated response, and for the critic, we use the variance of value estimates from a multi-head architecture. Both signals serve as an exploration bonus within the RLVR framework to guide the model. Our theoretical analysis shows that the actor-wise bonus inherently penalizes overconfident errors and promotes diversity among correct responses; moreover, we connect the critic-wise bonus to the well-established count-based exploration bonus in RL. Empirically, our method achieves an approximate +3 point improvement over standard RLVR using GRPO/PPO on AIME benchmarks. Further analysis identifies a calibration collapse mechanism within RLVR, shedding light on common LLM failure modes.