 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelA-Diffusion: Relativistic Adversarial Diffusion for Multi-Tracer PET Synthesis from Multi-Sequence MRI
Feb 24, 2026Multi-tracer positron emission tomography (PET) provides critical insights into diverse neuropathological processes such as tau accumulation, neuroinflammation, and $β$-amyloid deposition in the brain, making it indispensable for comprehensive neurological assessment. However, routine acquisition of multi-tracer PET is limited by high costs, radiation exposure, and restricted tracer availability. Recent efforts have explored deep learning approaches for synthesizing PET images from structural MRI. While some methods rely solely on T1-weighted MRI, others incorporate additional sequences such as T2-FLAIR to improve pathological sensitivity. However, existing methods often struggle to capture fine-grained anatomical and pathological details, resulting in artifacts and unrealistic outputs. To this end, we propose RelA-Diffusion, a Relativistic Adversarial Diffusion framework for multi-tracer PET synthesis from multi-sequence MRI. By leveraging both T1-weighted and T2-FLAIR scans as complementary inputs, RelA-Diffusion captures richer structural information to guide image generation. To improve synthesis fidelity, we introduce a gradient-penalized relativistic adversarial loss to the intermediate clean predictions of the diffusion model. This loss compares real and generated images in a relative manner, encouraging the synthesis of more realistic local structures. Both the relativistic formulation and the gradient penalty contribute to stabilizing the training, while adversarial feedback at each diffusion timestep enables consistent refinement throughout the generation process. Extensive experiments on two datasets demonstrate that RelA-Diffusion outperforms existing methods in both visual fidelity and quantitative metrics, highlighting its potential for accurate synthesis of multi-tracer PET.
Unified Multi-Site Multi-Sequence Brain MRI Harmonization Enriched by Biomedical Semantic Style
Jan 13, 2026Aggregating multi-site brain MRI data can enhance deep learning model training, but also introduces non-biological heterogeneity caused by site-specific variations (e.g., differences in scanner vendors, acquisition parameters, and imaging protocols) that can undermine generalizability. Recent retrospective MRI harmonization seeks to reduce such site effects by standardizing image style (e.g., intensity, contrast, noise patterns) while preserving anatomical content. However, existing methods often rely on limited paired traveling-subject data or fail to effectively disentangle style from anatomy. Furthermore, most current approaches address only single-sequence harmonization, restricting their use in real-world settings where multi-sequence MRI is routinely acquired. To this end, we introduce MMH, a unified framework for multi-site multi-sequence brain MRI harmonization that leverages biomedical semantic priors for sequence-aware style alignment. MMH operates in two stages: (1) a diffusion-based global harmonizer that maps MR images to a sequence-specific unified domain using style-agnostic gradient conditioning, and (2) a target-specific fine-tuner that adapts globally aligned images to desired target domains. A tri-planar attention BiomedCLIP encoder aggregates multi-view embeddings to characterize volumetric style information, allowing explicit disentanglement of image styles from anatomy without requiring paired data. Evaluations on 4,163 T1- and T2-weighted MRIs demonstrate MMH's superior harmonization over state-of-the-art methods in image feature clustering, voxel-level comparison, tissue segmentation, and downstream age and site classification.
Learning from Heterogeneous Structural MRI via Collaborative Domain Adaptation for Late-Life Depression Assessment
Jul 30, 2025Accurate identification of late-life depression (LLD) using structural brain MRI is essential for monitoring disease progression and facilitating timely intervention. However, existing learning-based approaches for LLD detection are often constrained by limited sample sizes (e.g., tens), which poses significant challenges for reliable model training and generalization. Although incorporating auxiliary datasets can expand the training set, substantial domain heterogeneity, such as differences in imaging protocols, scanner hardware, and population demographics, often undermines cross-domain transferability. To address this issue, we propose a Collaborative Domain Adaptation (CDA) framework for LLD detection using T1-weighted MRIs. The CDA leverages a Vision Transformer (ViT) to capture global anatomical context and a Convolutional Neural Network (CNN) to extract local structural features, with each branch comprising an encoder and a classifier. The CDA framework consists of three stages: (a) supervised training on labeled source data, (b) self-supervised target feature adaptation and (c) collaborative training on unlabeled target data. We first train ViT and CNN on source data, followed by self-supervised target feature adaptation by minimizing the discrepancy between classifier outputs from two branches to make the categorical boundary clearer. The collaborative training stage employs pseudo-labeled and augmented target-domain MRIs, enforcing prediction consistency under strong and weak augmentation to enhance domain robustness and generalization. Extensive experiments conducted on multi-site T1-weighted MRI data demonstrate that the CDA consistently outperforms state-of-the-art unsupervised domain adaptation methods.
Topology-Aware Graph Augmentation for Predicting Clinical Trajectories in Neurocognitive Disorders
Oct 31, 2024



Brain networks/graphs derived from resting-state functional MRI (fMRI) help study underlying pathophysiology of neurocognitive disorders by measuring neuronal activities in the brain. Some studies utilize learning-based methods for brain network analysis, but typically suffer from low model generalizability caused by scarce labeled fMRI data. As a notable self-supervised strategy, graph contrastive learning helps leverage auxiliary unlabeled data. But existing methods generally arbitrarily perturb graph nodes/edges to generate augmented graphs, without considering essential topology information of brain networks. To this end, we propose a topology-aware graph augmentation (TGA) framework, comprising a pretext model to train a generalizable encoder on large-scale unlabeled fMRI cohorts and a task-specific model to perform downstream tasks on a small target dataset. In the pretext model, we design two novel topology-aware graph augmentation strategies: (1) hub-preserving node dropping that prioritizes preserving brain hub regions according to node importance, and (2) weight-dependent edge removing that focuses on keeping important functional connectivities based on edge weights. Experiments on 1, 688 fMRI scans suggest that TGA outperforms several state-of-the-art methods.
R2Gen-Mamba: A Selective State Space Model for Radiology Report Generation
Oct 21, 2024Radiology report generation is crucial in medical imaging,but the manual annotation process by physicians is time-consuming and labor-intensive, necessitating the develop-ment of automatic report generation methods. Existingresearch predominantly utilizes Transformers to generateradiology reports, which can be computationally intensive,limiting their use in real applications. In this work, we presentR2Gen-Mamba, a novel automatic radiology report genera-tion method that leverages the efficient sequence processingof the Mamba with the contextual benefits of Transformerarchitectures. Due to lower computational complexity ofMamba, R2Gen-Mamba not only enhances training and in-ference efficiency but also produces high-quality reports.Experimental results on two benchmark datasets with morethan 210,000 X-ray image-report pairs demonstrate the ef-fectiveness of R2Gen-Mamba regarding report quality andcomputational efficiency compared with several state-of-the-art methods. The source code can be accessed online.
Unpaired Volumetric Harmonization of Brain MRI with Conditional Latent Diffusion
Aug 18, 2024

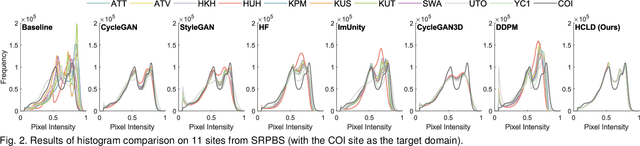

Multi-site structural MRI is increasingly used in neuroimaging studies to diversify subject cohorts. However, combining MR images acquired from various sites/centers may introduce site-related non-biological variations. Retrospective image harmonization helps address this issue, but current methods usually perform harmonization on pre-extracted hand-crafted radiomic features, limiting downstream applicability. Several image-level approaches focus on 2D slices, disregarding inherent volumetric information, leading to suboptimal outcomes. To this end, we propose a novel 3D MRI Harmonization framework through Conditional Latent Diffusion (HCLD) by explicitly considering image style and brain anatomy. It comprises a generalizable 3D autoencoder that encodes and decodes MRIs through a 4D latent space, and a conditional latent diffusion model that learns the latent distribution and generates harmonized MRIs with anatomical information from source MRIs while conditioned on target image style. This enables efficient volume-level MRI harmonization through latent style translation, without requiring paired images from target and source domains during training. The HCLD is trained and evaluated on 4,158 T1-weighted brain MRIs from three datasets in three tasks, assessing its ability to remove site-related variations while retaining essential biological features. Qualitative and quantitative experiments suggest the effectiveness of HCLD over several state-of-the-arts
Augmentation-based Unsupervised Cross-Domain Functional MRI Adaptation for Major Depressive Disorder Identification
May 31, 2024



Major depressive disorder (MDD) is a common mental disorder that typically affects a person's mood, cognition, behavior, and physical health. Resting-state functional magnetic resonance imaging (rs-fMRI) data are widely used for computer-aided diagnosis of MDD. While multi-site fMRI data can provide more data for training reliable diagnostic models, significant cross-site data heterogeneity would result in poor model generalizability. Many domain adaptation methods are designed to reduce the distributional differences between sites to some extent, but usually ignore overfitting problem of the model on the source domain. Intuitively, target data augmentation can alleviate the overfitting problem by forcing the model to learn more generalized features and reduce the dependence on source domain data. In this work, we propose a new augmentation-based unsupervised cross-domain fMRI adaptation (AUFA) framework for automatic diagnosis of MDD. The AUFA consists of 1) a graph representation learning module for extracting rs-fMRI features with spatial attention, 2) a domain adaptation module for feature alignment between source and target data, 3) an augmentation-based self-optimization module for alleviating model overfitting on the source domain, and 4) a classification module. Experimental results on 1,089 subjects suggest that AUFA outperforms several state-of-the-art methods in MDD identification. Our approach not only reduces data heterogeneity between different sites, but also localizes disease-related functional connectivity abnormalities and provides interpretability for the model.
ACTION: Augmentation and Computation Toolbox for Brain Network Analysis with Functional MRI
May 10, 2024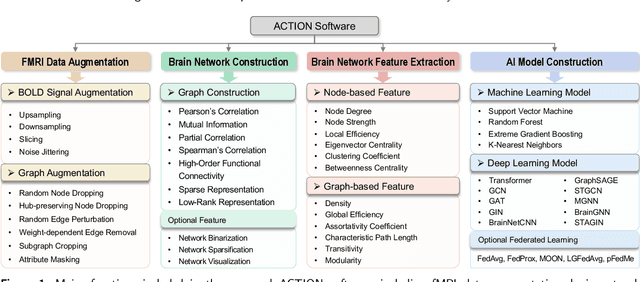
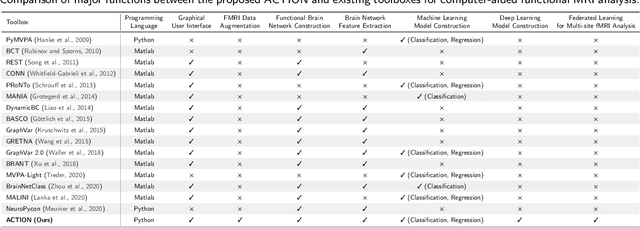
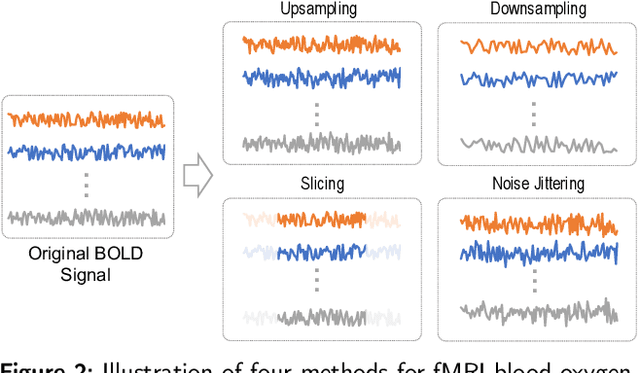

Functional magnetic resonance imaging (fMRI) has been increasingly employed to investigate functional brain activity. Many fMRI-related software/toolboxes have been developed, providing specialized algorithms for fMRI analysis. However, existing toolboxes seldom consider fMRI data augmentation, which is quite useful, especially in studies with limited or imbalanced data. Moreover, current studies usually focus on analyzing fMRI using conventional machine learning models that rely on human-engineered fMRI features, without investigating deep learning models that can automatically learn data-driven fMRI representations. In this work, we develop an open-source toolbox, called Augmentation and Computation Toolbox for braIn netwOrk aNalysis (ACTION), offering comprehensive functions to streamline fMRI analysis. The ACTION is a Python-based and cross-platform toolbox with graphical user-friendly interfaces. It enables automatic fMRI augmentation, covering blood-oxygen-level-dependent (BOLD) signal augmentation and brain network augmentation. Many popular methods for brain network construction and network feature extraction are included. In particular, it supports constructing deep learning models, which leverage large-scale auxiliary unlabeled data (3,800+ resting-state fMRI scans) for model pretraining to enhance model performance for downstream tasks. To facilitate multi-site fMRI studies, it is also equipped with several popular federated learning strategies. Furthermore, it enables users to design and test custom algorithms through scripting, greatly improving its utility and extensibility. We demonstrate the effectiveness and user-friendliness of ACTION on real fMRI data and present the experimental results. The software, along with its source code and manual, can be accessed online.
Functional Imaging Constrained Diffusion for Brain PET Synthesis from Structural MRI
May 03, 2024



Magnetic resonance imaging (MRI) and positron emission tomography (PET) are increasingly used in multimodal analysis of neurodegenerative disorders. While MRI is broadly utilized in clinical settings, PET is less accessible. Many studies have attempted to use deep generative models to synthesize PET from MRI scans. However, they often suffer from unstable training and inadequately preserve brain functional information conveyed by PET. To this end, we propose a functional imaging constrained diffusion (FICD) framework for 3D brain PET image synthesis with paired structural MRI as input condition, through a new constrained diffusion model (CDM). The FICD introduces noise to PET and then progressively removes it with CDM, ensuring high output fidelity throughout a stable training phase. The CDM learns to predict denoised PET with a functional imaging constraint introduced to ensure voxel-wise alignment between each denoised PET and its ground truth. Quantitative and qualitative analyses conducted on 293 subjects with paired T1-weighted MRI and 18F-fluorodeoxyglucose (FDG)-PET scans suggest that FICD achieves superior performance in generating FDG-PET data compared to state-of-the-art methods. We further validate the effectiveness of the proposed FICD on data from a total of 1,262 subjects through three downstream tasks, with experimental results suggesting its utility and generalizability.
Iterative Learning for Joint Image Denoising and Motion Artifact Correction of 3D Brain MRI
Mar 13, 2024



Image noise and motion artifacts greatly affect the quality of brain MRI and negatively influence downstream medical image analysis. Previous studies often focus on 2D methods that process each volumetric MR image slice-by-slice, thus losing important 3D anatomical information. Additionally, these studies generally treat image denoising and artifact correction as two standalone tasks, without considering their potential relationship, especially on low-quality images where severe noise and motion artifacts occur simultaneously. To address these issues, we propose a Joint image Denoising and motion Artifact Correction (JDAC) framework via iterative learning to handle noisy MRIs with motion artifacts, consisting of an adaptive denoising model and an anti-artifact model. In the adaptive denoising model, we first design a novel noise level estimation strategy, and then adaptively reduce the noise through a U-Net backbone with feature normalization conditioning on the estimated noise variance. The anti-artifact model employs another U-Net for eliminating motion artifacts, incorporating a novel gradient-based loss function designed to maintain the integrity of brain anatomy during the motion correction process. These two models are iteratively employed for joint image denoising and artifact correction through an iterative learning framework. An early stopping strategy depending on noise level estimation is applied to accelerate the iteration process. The denoising model is trained with 9,544 T1-weighted MRIs with manually added Gaussian noise as supervision. The anti-artifact model is trained on 552 T1-weighted MRIs with motion artifacts and paired motion-free images. Experimental results on a public dataset and a clinical study suggest the effectiveness of JDAC in both tasks of denoising and motion artifact correction, compared with several state-of-the-art methods.