 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Multi-Site Multi-Sequence Brain MRI Harmonization Enriched by Biomedical Semantic Style
Jan 13, 2026Aggregating multi-site brain MRI data can enhance deep learning model training, but also introduces non-biological heterogeneity caused by site-specific variations (e.g., differences in scanner vendors, acquisition parameters, and imaging protocols) that can undermine generalizability. Recent retrospective MRI harmonization seeks to reduce such site effects by standardizing image style (e.g., intensity, contrast, noise patterns) while preserving anatomical content. However, existing methods often rely on limited paired traveling-subject data or fail to effectively disentangle style from anatomy. Furthermore, most current approaches address only single-sequence harmonization, restricting their use in real-world settings where multi-sequence MRI is routinely acquired. To this end, we introduce MMH, a unified framework for multi-site multi-sequence brain MRI harmonization that leverages biomedical semantic priors for sequence-aware style alignment. MMH operates in two stages: (1) a diffusion-based global harmonizer that maps MR images to a sequence-specific unified domain using style-agnostic gradient conditioning, and (2) a target-specific fine-tuner that adapts globally aligned images to desired target domains. A tri-planar attention BiomedCLIP encoder aggregates multi-view embeddings to characterize volumetric style information, allowing explicit disentanglement of image styles from anatomy without requiring paired data. Evaluations on 4,163 T1- and T2-weighted MRIs demonstrate MMH's superior harmonization over state-of-the-art methods in image feature clustering, voxel-level comparison, tissue segmentation, and downstream age and site classification.
Unpaired Volumetric Harmonization of Brain MRI with Conditional Latent Diffusion
Aug 18, 2024

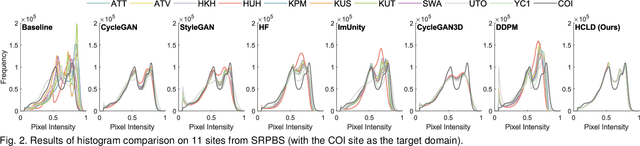

Multi-site structural MRI is increasingly used in neuroimaging studies to diversify subject cohorts. However, combining MR images acquired from various sites/centers may introduce site-related non-biological variations. Retrospective image harmonization helps address this issue, but current methods usually perform harmonization on pre-extracted hand-crafted radiomic features, limiting downstream applicability. Several image-level approaches focus on 2D slices, disregarding inherent volumetric information, leading to suboptimal outcomes. To this end, we propose a novel 3D MRI Harmonization framework through Conditional Latent Diffusion (HCLD) by explicitly considering image style and brain anatomy. It comprises a generalizable 3D autoencoder that encodes and decodes MRIs through a 4D latent space, and a conditional latent diffusion model that learns the latent distribution and generates harmonized MRIs with anatomical information from source MRIs while conditioned on target image style. This enables efficient volume-level MRI harmonization through latent style translation, without requiring paired images from target and source domains during training. The HCLD is trained and evaluated on 4,158 T1-weighted brain MRIs from three datasets in three tasks, assessing its ability to remove site-related variations while retaining essential biological features. Qualitative and quantitative experiments suggest the effectiveness of HCLD over several state-of-the-arts
Functional Imaging Constrained Diffusion for Brain PET Synthesis from Structural MRI
May 03, 2024



Magnetic resonance imaging (MRI) and positron emission tomography (PET) are increasingly used in multimodal analysis of neurodegenerative disorders. While MRI is broadly utilized in clinical settings, PET is less accessible. Many studies have attempted to use deep generative models to synthesize PET from MRI scans. However, they often suffer from unstable training and inadequately preserve brain functional information conveyed by PET. To this end, we propose a functional imaging constrained diffusion (FICD) framework for 3D brain PET image synthesis with paired structural MRI as input condition, through a new constrained diffusion model (CDM). The FICD introduces noise to PET and then progressively removes it with CDM, ensuring high output fidelity throughout a stable training phase. The CDM learns to predict denoised PET with a functional imaging constraint introduced to ensure voxel-wise alignment between each denoised PET and its ground truth. Quantitative and qualitative analyses conducted on 293 subjects with paired T1-weighted MRI and 18F-fluorodeoxyglucose (FDG)-PET scans suggest that FICD achieves superior performance in generating FDG-PET data compared to state-of-the-art methods. We further validate the effectiveness of the proposed FICD on data from a total of 1,262 subjects through three downstream tasks, with experimental results suggesting its utility and generalizability.
Iterative Learning for Joint Image Denoising and Motion Artifact Correction of 3D Brain MRI
Mar 13, 2024



Image noise and motion artifacts greatly affect the quality of brain MRI and negatively influence downstream medical image analysis. Previous studies often focus on 2D methods that process each volumetric MR image slice-by-slice, thus losing important 3D anatomical information. Additionally, these studies generally treat image denoising and artifact correction as two standalone tasks, without considering their potential relationship, especially on low-quality images where severe noise and motion artifacts occur simultaneously. To address these issues, we propose a Joint image Denoising and motion Artifact Correction (JDAC) framework via iterative learning to handle noisy MRIs with motion artifacts, consisting of an adaptive denoising model and an anti-artifact model. In the adaptive denoising model, we first design a novel noise level estimation strategy, and then adaptively reduce the noise through a U-Net backbone with feature normalization conditioning on the estimated noise variance. The anti-artifact model employs another U-Net for eliminating motion artifacts, incorporating a novel gradient-based loss function designed to maintain the integrity of brain anatomy during the motion correction process. These two models are iteratively employed for joint image denoising and artifact correction through an iterative learning framework. An early stopping strategy depending on noise level estimation is applied to accelerate the iteration process. The denoising model is trained with 9,544 T1-weighted MRIs with manually added Gaussian noise as supervision. The anti-artifact model is trained on 552 T1-weighted MRIs with motion artifacts and paired motion-free images. Experimental results on a public dataset and a clinical study suggest the effectiveness of JDAC in both tasks of denoising and motion artifact correction, compared with several state-of-the-art methods.
Disentangled Latent Energy-Based Style Translation: An Image-Level Structural MRI Harmonization Framework
Feb 10, 2024



Brain magnetic resonance imaging (MRI) has been extensively employed across clinical and research fields, but often exhibits sensitivity to site effects arising from nonbiological variations such as differences in field strength and scanner vendors. Numerous retrospective MRI harmonization techniques have demonstrated encouraging outcomes in reducing the site effects at image level. However, existing methods generally suffer from high computational requirements and limited generalizability, restricting their applicability to unseen MRIs. In this paper, we design a novel disentangled latent energy-based style translation (DLEST) framework for unpaired image-level MRI harmonization, consisting of (1) site-invariant image generation (SIG), (2) site-specific style translation (SST), and (3) site-specific MRI synthesis (SMS). Specifically, the SIG employs a latent autoencoder to encode MRIs into a low-dimensional latent space and reconstruct MRIs from latent codes. The SST utilizes an energy-based model to comprehend the global latent distribution of a target domain and translate source latent codes toward the target domain, while SMS enables MRI synthesis with a target-specific style. By disentangling image generation and style translation in latent space, the DLEST can achieve efficient style translation. Our model was trained on T1-weighted MRIs from a public dataset (with 3,984 subjects across 58 acquisition sites/settings) and validated on an independent dataset (with 9 traveling subjects scanned in 11 sites/settings) in 4 tasks: (1) histogram and clustering comparison, (2) site classification, (3) brain tissue segmentation, and (4) site-specific MRI synthesis. Qualitative and quantitative results demonstrate the superiority of our method over several state-of-the-arts.
Human Pose-based Estimation, Tracking and Action Recognition with Deep Learning: A Survey
Oct 19, 2023



Human pose analysis has garnered significant attention within both the research community and practical applications, owing to its expanding array of uses, including gaming, video surveillance, sports performance analysis, and human-computer interactions, among others. The advent of deep learning has significantly improved the accuracy of pose capture, making pose-based applications increasingly practical. This paper presents a comprehensive survey of pose-based applications utilizing deep learning, encompassing pose estimation, pose tracking, and action recognition.Pose estimation involves the determination of human joint positions from images or image sequences. Pose tracking is an emerging research direction aimed at generating consistent human pose trajectories over time. Action recognition, on the other hand, targets the identification of action types using pose estimation or tracking data. These three tasks are intricately interconnected, with the latter often reliant on the former. In this survey, we comprehensively review related works, spanning from single-person pose estimation to multi-person pose estimation, from 2D pose estimation to 3D pose estimation, from single image to video, from mining temporal context gradually to pose tracking, and lastly from tracking to pose-based action recognition. As a survey centered on the application of deep learning to pose analysis, we explicitly discuss both the strengths and limitations of existing techniques. Notably, we emphasize methodologies for integrating these three tasks into a unified framework within video sequences. Additionally, we explore the challenges involved and outline potential directions for future research.