 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViRC: Enhancing Visual Interleaved Mathematical CoT with Reason Chunking
Dec 17, 2025CoT has significantly enhanced the reasoning ability of LLMs while it faces challenges when extended to multimodal domains, particularly in mathematical tasks. Existing MLLMs typically perform textual reasoning solely from a single static mathematical image, overlooking dynamic visual acquisition during reasoning. In contrast, humans repeatedly examine visual image and employ step-by-step reasoning to prove intermediate propositions. This strategy of decomposing the problem-solving process into key logical nodes adheres to Miller's Law in cognitive science. Inspired by this insight, we propose a ViRC framework for multimodal mathematical tasks, introducing a Reason Chunking mechanism that structures multimodal mathematical CoT into consecutive Critical Reasoning Units (CRUs) to simulate human expert problem-solving patterns. CRUs ensure intra-unit textual coherence for intermediate proposition verification while integrating visual information across units to generate subsequent propositions and support structured reasoning. To this end, we present CRUX dataset by using three visual tools and four reasoning patterns to provide explicitly annotated CRUs across multiple reasoning paths for each mathematical problem. Leveraging the CRUX dataset, we propose a progressive training strategy inspired by human cognitive learning, which includes Instructional SFT, Practice SFT, and Strategic RL, aimed at further strengthening the Reason Chunking ability of the model. The resulting ViRC-7B model achieves a 18.8% average improvement over baselines across multiple mathematical benchmarks. Code is available at https://github.com/Leon-LihongWang/ViRC.
Diff3DS: Generating View-Consistent 3D Sketch via Differentiable Curve Rendering
May 24, 20243D sketches are widely used for visually representing the 3D shape and structure of objects or scenes. However, the creation of 3D sketch often requires users to possess professional artistic skills. Existing research efforts primarily focus on enhancing the ability of interactive sketch generation in 3D virtual systems. In this work, we propose Diff3DS, a novel differentiable rendering framework for generating view-consistent 3D sketch by optimizing 3D parametric curves under various supervisions. Specifically, we perform perspective projection to render the 3D rational B\'ezier curves into 2D curves, which are subsequently converted to a 2D raster image via our customized differentiable rasterizer. Our framework bridges the domains of 3D sketch and raster image, achieving end-toend optimization of 3D sketch through gradients computed in the 2D image domain. Our Diff3DS can enable a series of novel 3D sketch generation tasks, including textto-3D sketch and image-to-3D sketch, supported by the popular distillation-based supervision, such as Score Distillation Sampling (SDS). Extensive experiments have yielded promising results and demonstrated the potential of our framework.
Iterative Learning for Joint Image Denoising and Motion Artifact Correction of 3D Brain MRI
Mar 13, 2024



Image noise and motion artifacts greatly affect the quality of brain MRI and negatively influence downstream medical image analysis. Previous studies often focus on 2D methods that process each volumetric MR image slice-by-slice, thus losing important 3D anatomical information. Additionally, these studies generally treat image denoising and artifact correction as two standalone tasks, without considering their potential relationship, especially on low-quality images where severe noise and motion artifacts occur simultaneously. To address these issues, we propose a Joint image Denoising and motion Artifact Correction (JDAC) framework via iterative learning to handle noisy MRIs with motion artifacts, consisting of an adaptive denoising model and an anti-artifact model. In the adaptive denoising model, we first design a novel noise level estimation strategy, and then adaptively reduce the noise through a U-Net backbone with feature normalization conditioning on the estimated noise variance. The anti-artifact model employs another U-Net for eliminating motion artifacts, incorporating a novel gradient-based loss function designed to maintain the integrity of brain anatomy during the motion correction process. These two models are iteratively employed for joint image denoising and artifact correction through an iterative learning framework. An early stopping strategy depending on noise level estimation is applied to accelerate the iteration process. The denoising model is trained with 9,544 T1-weighted MRIs with manually added Gaussian noise as supervision. The anti-artifact model is trained on 552 T1-weighted MRIs with motion artifacts and paired motion-free images. Experimental results on a public dataset and a clinical study suggest the effectiveness of JDAC in both tasks of denoising and motion artifact correction, compared with several state-of-the-art methods.
Multi-Modal Knowledge Graph Transformer Framework for Multi-Modal Entity Alignment
Oct 10, 2023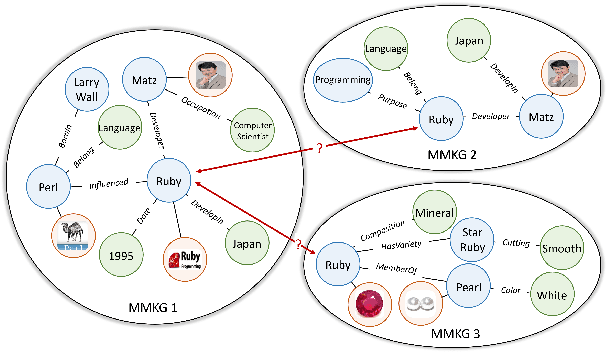
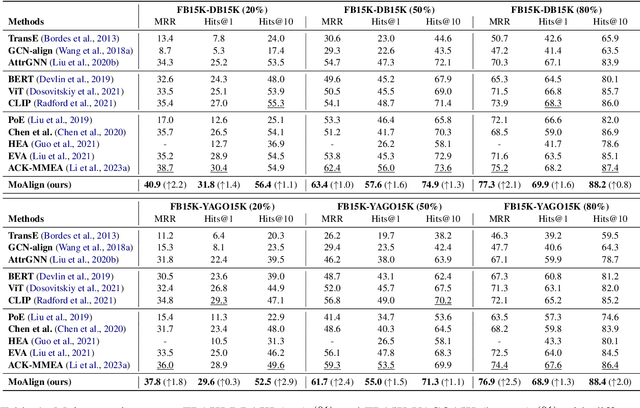
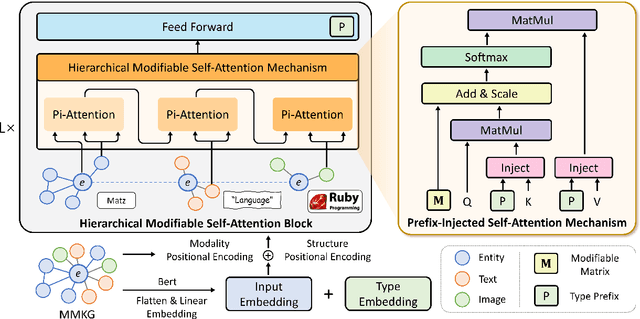
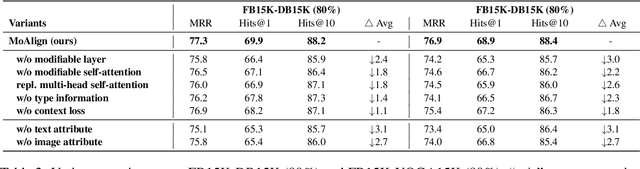
Multi-Modal Entity Alignment (MMEA) is a critical task that aims to identify equivalent entity pairs across multi-modal knowledge graphs (MMKGs). However, this task faces challenges due to the presence of different types of information, including neighboring entities, multi-modal attributes, and entity types. Directly incorporating the above information (e.g., concatenation or attention) can lead to an unaligned information space. To address these challenges, we propose a novel MMEA transformer, called MoAlign, that hierarchically introduces neighbor features, multi-modal attributes, and entity types to enhance the alignment task. Taking advantage of the transformer's ability to better integrate multiple information, we design a hierarchical modifiable self-attention block in a transformer encoder to preserve the unique semantics of different information. Furthermore, we design two entity-type prefix injection methods to integrate entity-type information using type prefixes, which help to restrict the global information of entities not present in the MMKGs. Our extensive experiments on benchmark datasets demonstrate that our approach outperforms strong competitors and achieves excellent entity alignment performance.
Brain Anatomy Prior Modeling to Forecast Clinical Progression of Cognitive Impairment with Structural MRI
Jun 26, 2023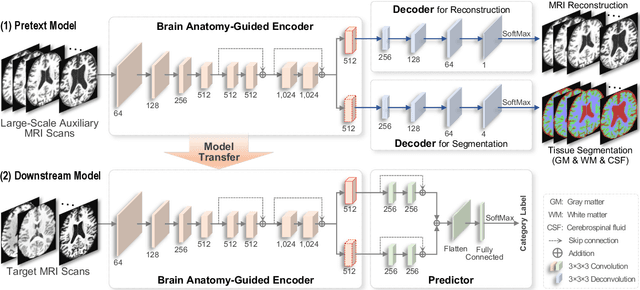

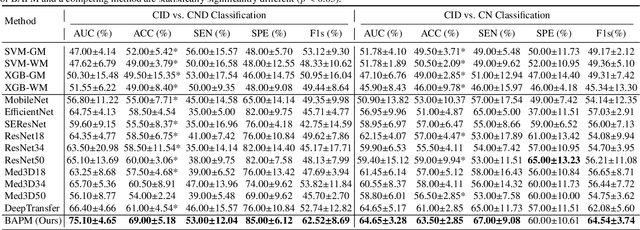
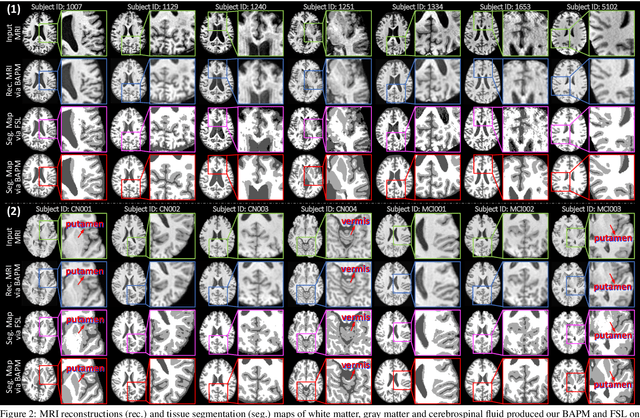
Brain structural MRI has been widely used to assess the future progression of cognitive impairment (CI). Previous learning-based studies usually suffer from the issue of small-sized labeled training data, while there exist a huge amount of structural MRIs in large-scale public databases. Intuitively, brain anatomical structures derived from these public MRIs (even without task-specific label information) can be used to boost CI progression trajectory prediction. However, previous studies seldom take advantage of such brain anatomy prior. To this end, this paper proposes a brain anatomy prior modeling (BAPM) framework to forecast the clinical progression of cognitive impairment with small-sized target MRIs by exploring anatomical brain structures. Specifically, the BAPM consists of a pretext model and a downstream model, with a shared brain anatomy-guided encoder to model brain anatomy prior explicitly. Besides the encoder, the pretext model also contains two decoders for two auxiliary tasks (i.e., MRI reconstruction and brain tissue segmentation), while the downstream model relies on a predictor for classification. The brain anatomy-guided encoder is pre-trained with the pretext model on 9,344 auxiliary MRIs without diagnostic labels for anatomy prior modeling. With this encoder frozen, the downstream model is then fine-tuned on limited target MRIs for prediction. We validate the BAPM on two CI-related studies with T1-weighted MRIs from 448 subjects. Experimental results suggest the effectiveness of BAPM in (1) four CI progression prediction tasks, (2) MR image reconstruction, and (3) brain tissue segmentation, compared with several state-of-the-art methods.
Attribute-Consistent Knowledge Graph Representation Learning for Multi-Modal Entity Alignment
Apr 04, 2023The multi-modal entity alignment (MMEA) aims to find all equivalent entity pairs between multi-modal knowledge graphs (MMKGs). Rich attributes and neighboring entities are valuable for the alignment task, but existing works ignore contextual gap problems that the aligned entities have different numbers of attributes on specific modality when learning entity representations. In this paper, we propose a novel attribute-consistent knowledge graph representation learning framework for MMEA (ACK-MMEA) to compensate the contextual gaps through incorporating consistent alignment knowledge. Attribute-consistent KGs (ACKGs) are first constructed via multi-modal attribute uniformization with merge and generate operators so that each entity has one and only one uniform feature in each modality. The ACKGs are then fed into a relation-aware graph neural network with random dropouts, to obtain aggregated relation representations and robust entity representations. In order to evaluate the ACK-MMEA facilitated for entity alignment, we specially design a joint alignment loss for both entity and attribute evaluation. Extensive experiments conducted on two benchmark datasets show that our approach achieves excellent performance compared to its competitors.
Reinforcement Learning Guided Multi-Objective Exam Paper Generation
Mar 02, 2023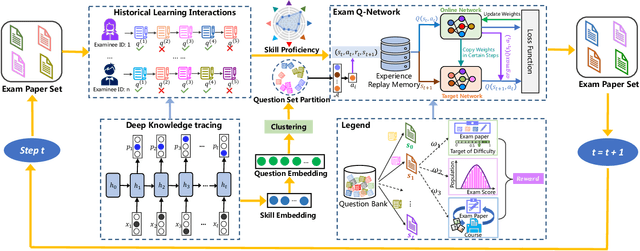

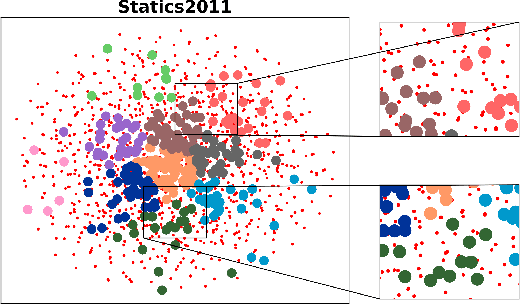
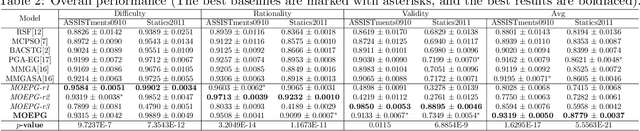
To reduce the repetitive and complex work of instructors, exam paper generation (EPG) technique has become a salient topic in the intelligent education field, which targets at generating high-quality exam paper automatically according to instructor-specified assessment criteria. The current advances utilize the ability of heuristic algorithms to optimize several well-known objective constraints, such as difficulty degree, number of questions, etc., for producing optimal solutions. However, in real scenarios, considering other equally relevant objectives (e.g., distribution of exam scores, skill coverage) is extremely important. Besides, how to develop an automatic multi-objective solution that finds an optimal subset of questions from a huge search space of large-sized question datasets and thus composes a high-quality exam paper is urgent but non-trivial. To this end, we skillfully design a reinforcement learning guided Multi-Objective Exam Paper Generation framework, termed MOEPG, to simultaneously optimize three exam domain-specific objectives including difficulty degree, distribution of exam scores, and skill coverage. Specifically, to accurately measure the skill proficiency of the examinee group, we first employ deep knowledge tracing to model the interaction information between examinees and response logs. We then design the flexible Exam Q-Network, a function approximator, which automatically selects the appropriate question to update the exam paper composition process. Later, MOEPG divides the decision space into multiple subspaces to better guide the updated direction of the exam paper. Through extensive experiments on two real-world datasets, we demonstrate that MOEPG is feasible in addressing the multiple dilemmas of exam paper generation scenario.
Hybrid Representation Learning for Cognitive Diagnosis in Late-Life Depression Over 5 Years with Structural MRI
Dec 24, 2022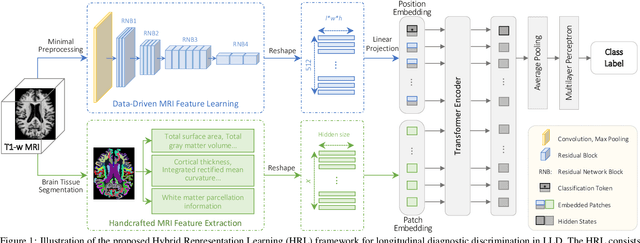
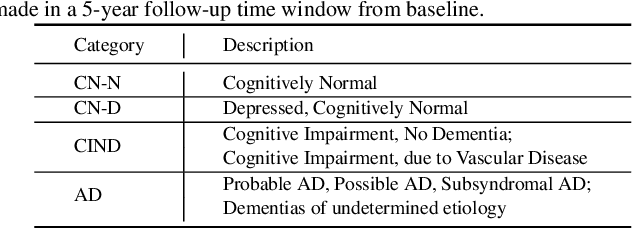
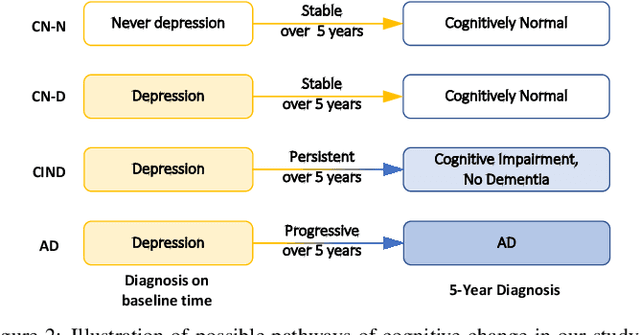
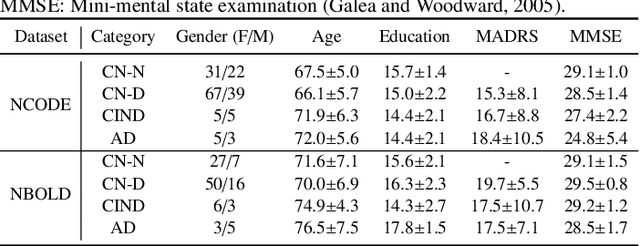
Late-life depression (LLD) is a highly prevalent mood disorder occurring in older adults and is frequently accompanied by cognitive impairment (CI). Studies have shown that LLD may increase the risk of Alzheimer's disease (AD). However, the heterogeneity of presentation of geriatric depression suggests that multiple biological mechanisms may underlie it. Current biological research on LLD progression incorporates machine learning that combines neuroimaging data with clinical observations. There are few studies on incident cognitive diagnostic outcomes in LLD based on structural MRI (sMRI). In this paper, we describe the development of a hybrid representation learning (HRL) framework for predicting cognitive diagnosis over 5 years based on T1-weighted sMRI data. Specifically, we first extract prediction-oriented MRI features via a deep neural network, and then integrate them with handcrafted MRI features via a Transformer encoder for cognitive diagnosis prediction. Two tasks are investigated in this work, including (1) identifying cognitively normal subjects with LLD and never-depressed older healthy subjects, and (2) identifying LLD subjects who developed CI (or even AD) and those who stayed cognitively normal over five years. To the best of our knowledge, this is among the first attempts to study the complex heterogeneous progression of LLD based on task-oriented and handcrafted MRI features. We validate the proposed HRL on 294 subjects with T1-weighted MRIs from two clinically harmonized studies. Experimental results suggest that the HRL outperforms several classical machine learning and state-of-the-art deep learning methods in LLD identification and prediction tasks.
Type Information Utilized Event Detection via Multi-Channel GNNs in Electrical Power Systems
Nov 15, 2022Event detection in power systems aims to identify triggers and event types, which helps relevant personnel respond to emergencies promptly and facilitates the optimization of power supply strategies. However, the limited length of short electrical record texts causes severe information sparsity, and numerous domain-specific terminologies of power systems makes it difficult to transfer knowledge from language models pre-trained on general-domain texts. Traditional event detection approaches primarily focus on the general domain and ignore these two problems in the power system domain. To address the above issues, we propose a Multi-Channel graph neural network utilizing Type information for Event Detection in power systems, named MC-TED, leveraging a semantic channel and a topological channel to enrich information interaction from short texts. Concretely, the semantic channel refines textual representations with semantic similarity, building the semantic information interaction among potential event-related words. The topological channel generates a relation-type-aware graph modeling word dependencies, and a word-type-aware graph integrating part-of-speech tags. To further reduce errors worsened by professional terminologies in type analysis, a type learning mechanism is designed for updating the representations of both the word type and relation type in the topological channel. In this way, the information sparsity and professional term occurrence problems can be alleviated by enabling interaction between topological and semantic information. Furthermore, to address the lack of labeled data in power systems, we built a Chinese event detection dataset based on electrical Power Event texts, named PoE. In experiments, our model achieves compelling results not only on the PoE dataset, but on general-domain event detection datasets including ACE 2005 and MAVEN.
Event Extraction by Associating Event Types and Argument Roles
Aug 23, 2021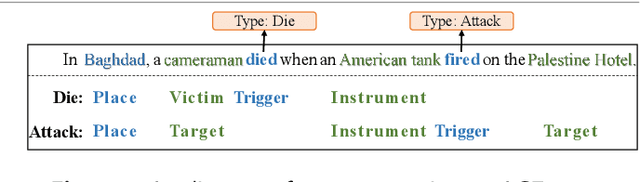
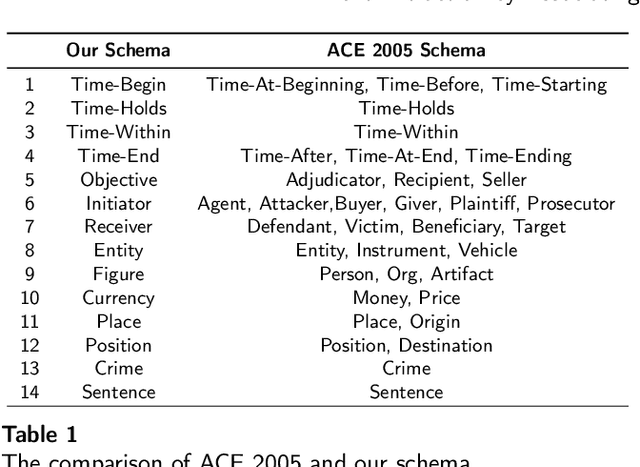

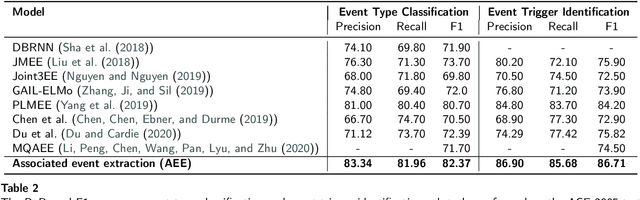
Event extraction (EE), which acquires structural event knowledge from texts, can be divided into two sub-tasks: event type classification and element extraction (namely identifying triggers and arguments under different role patterns). As different event types always own distinct extraction schemas (i.e., role patterns), previous work on EE usually follows an isolated learning paradigm, performing element extraction independently for different event types. It ignores meaningful associations among event types and argument roles, leading to relatively poor performance for less frequent types/roles. This paper proposes a novel neural association framework for the EE task. Given a document, it first performs type classification via constructing a document-level graph to associate sentence nodes of different types, and adopting a graph attention network to learn sentence embeddings. Then, element extraction is achieved by building a universal schema of argument roles, with a parameter inheritance mechanism to enhance role preference for extracted elements. As such, our model takes into account type and role associations during EE, enabling implicit information sharing among them. Experimental results show that our approach consistently outperforms most state-of-the-art EE methods in both sub-tasks. Particularly, for types/roles with less training data, the performance is superior to the existing methods.