 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Safety Alignment via SAE-Constructed Low-Rank Subspace Adaptation
Dec 29, 2025Parameter-efficient fine-tuning has become the dominant paradigm for adapting large language models to downstream tasks. Low-rank adaptation methods such as LoRA operate under the assumption that task-relevant weight updates reside in a low-rank subspace, yet this subspace is learned implicitly from data in a black-box manner, offering no interpretability or direct control. We hypothesize that this difficulty stems from polysemanticity--individual dimensions encoding multiple entangled concepts. To address this, we leverage pre-trained Sparse Autoencoders (SAEs) to identify task-relevant features in a disentangled feature space, then construct an explicit, interpretable low-rank subspace to guide adapter initialization. We provide theoretical analysis proving that under monosemanticity assumptions, SAE-based subspace identification achieves arbitrarily small recovery error, while direct identification in polysemantic space suffers an irreducible error floor. On safety alignment, our method achieves up to 99.6% safety rate--exceeding full fine-tuning by 7.4 percentage points and approaching RLHF-based methods--while updating only 0.19-0.24% of parameters. Crucially, our method provides interpretable insights into the learned alignment subspace through the semantic grounding of SAE features. Our work demonstrates that incorporating mechanistic interpretability into the fine-tuning process can simultaneously improve both performance and transparency.
Reinforcement Learning Guided Multi-Objective Exam Paper Generation
Mar 02, 2023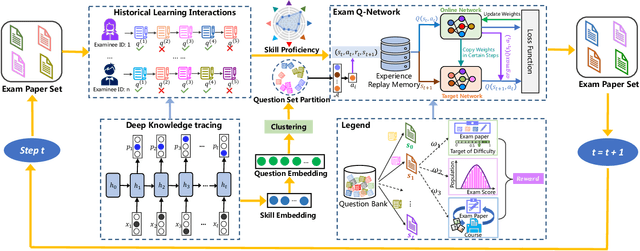

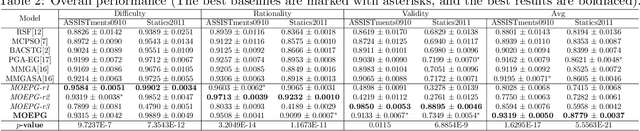
To reduce the repetitive and complex work of instructors, exam paper generation (EPG) technique has become a salient topic in the intelligent education field, which targets at generating high-quality exam paper automatically according to instructor-specified assessment criteria. The current advances utilize the ability of heuristic algorithms to optimize several well-known objective constraints, such as difficulty degree, number of questions, etc., for producing optimal solutions. However, in real scenarios, considering other equally relevant objectives (e.g., distribution of exam scores, skill coverage) is extremely important. Besides, how to develop an automatic multi-objective solution that finds an optimal subset of questions from a huge search space of large-sized question datasets and thus composes a high-quality exam paper is urgent but non-trivial. To this end, we skillfully design a reinforcement learning guided Multi-Objective Exam Paper Generation framework, termed MOEPG, to simultaneously optimize three exam domain-specific objectives including difficulty degree, distribution of exam scores, and skill coverage. Specifically, to accurately measure the skill proficiency of the examinee group, we first employ deep knowledge tracing to model the interaction information between examinees and response logs. We then design the flexible Exam Q-Network, a function approximator, which automatically selects the appropriate question to update the exam paper composition process. Later, MOEPG divides the decision space into multiple subspaces to better guide the updated direction of the exam paper. Through extensive experiments on two real-world datasets, we demonstrate that MOEPG is feasible in addressing the multiple dilemmas of exam paper generation scenario.