 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImbalanced Graph-Level Anomaly Detection via Counterfactual Augmentation and Feature Learning
Jul 13, 2024



Graph-level anomaly detection (GLAD) has already gained significant importance and has become a popular field of study, attracting considerable attention across numerous downstream works. The core focus of this domain is to capture and highlight the anomalous information within given graph datasets. In most existing studies, anomalies are often the instances of few. The stark imbalance misleads current GLAD methods to focus on learning the patterns of normal graphs more, further impacting anomaly detection performance. Moreover, existing methods predominantly utilize the inherent features of nodes to identify anomalous graph patterns which is approved suboptimal according to our experiments. In this work, we propose an imbalanced GLAD method via counterfactual augmentation and feature learning. Specifically, we first construct anomalous samples based on counterfactual learning, aiming to expand and balance the datasets. Additionally, we construct a module based on Graph Neural Networks (GNNs), which allows us to utilize degree attributes to complement the inherent attribute features of nodes. Then, we design an adaptive weight learning module to integrate features tailored to different datasets effectively to avoid indiscriminately treating all features as equivalent. Furthermore, extensive baseline experiments conducted on public datasets substantiate the robustness and effectiveness. Besides, we apply the model to brain disease datasets, which can prove the generalization capability of our work. The source code of our work is available online.
Graph Neural Networks for Brain Graph Learning: A Survey
Jun 01, 2024



Exploring the complex structure of the human brain is crucial for understanding its functionality and diagnosing brain disorders. Thanks to advancements in neuroimaging technology, a novel approach has emerged that involves modeling the human brain as a graph-structured pattern, with different brain regions represented as nodes and the functional relationships among these regions as edges. Moreover, graph neural networks (GNNs) have demonstrated a significant advantage in mining graph-structured data. Developing GNNs to learn brain graph representations for brain disorder analysis has recently gained increasing attention. However, there is a lack of systematic survey work summarizing current research methods in this domain. In this paper, we aim to bridge this gap by reviewing brain graph learning works that utilize GNNs. We first introduce the process of brain graph modeling based on common neuroimaging data. Subsequently, we systematically categorize current works based on the type of brain graph generated and the targeted research problems. To make this research accessible to a broader range of interested researchers, we provide an overview of representative methods and commonly used datasets, along with their implementation sources. Finally, we present our insights on future research directions. The repository of this survey is available at \url{https://github.com/XuexiongLuoMQ/Awesome-Brain-Graph-Learning-with-GNNs}.
Discriminative Graph-level Anomaly Detection via Dual-students-teacher Model
Aug 03, 2023



Different from the current node-level anomaly detection task, the goal of graph-level anomaly detection is to find abnormal graphs that significantly differ from others in a graph set. Due to the scarcity of research on the work of graph-level anomaly detection, the detailed description of graph-level anomaly is insufficient. Furthermore, existing works focus on capturing anomalous graph information to learn better graph representations, but they ignore the importance of an effective anomaly score function for evaluating abnormal graphs. Thus, in this work, we first define anomalous graph information including node and graph property anomalies in a graph set and adopt node-level and graph-level information differences to identify them, respectively. Then, we introduce a discriminative graph-level anomaly detection framework with dual-students-teacher model, where the teacher model with a heuristic loss are trained to make graph representations more divergent. Then, two competing student models trained by normal and abnormal graphs respectively fit graph representations of the teacher model in terms of node-level and graph-level representation perspectives. Finally, we combine representation errors between two student models to discriminatively distinguish anomalous graphs. Extensive experiment analysis demonstrates that our method is effective for the graph-level anomaly detection task on graph datasets in the real world.
Multi-representations Space Separation based Graph-level Anomaly-aware Detection
Jul 22, 2023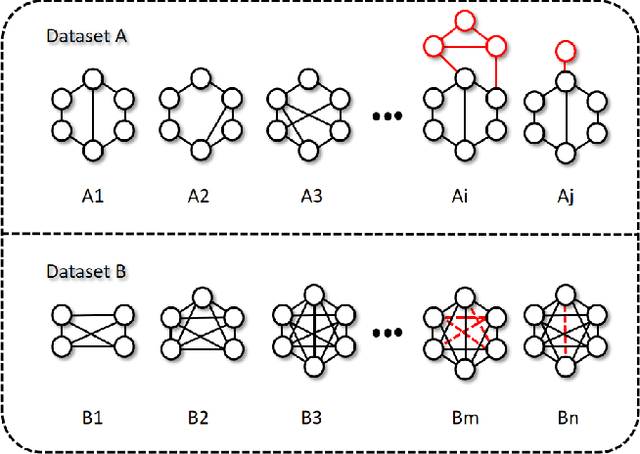

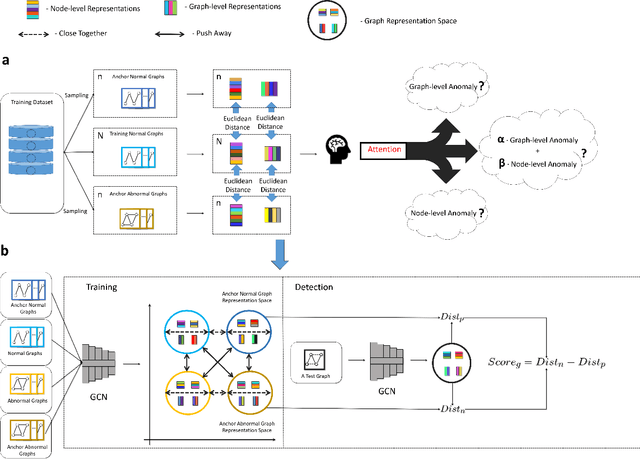
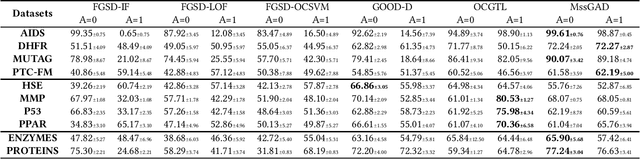
Graph structure patterns are widely used to model different area data recently. How to detect anomalous graph information on these graph data has become a popular research problem. The objective of this research is centered on the particular issue that how to detect abnormal graphs within a graph set. The previous works have observed that abnormal graphs mainly show node-level and graph-level anomalies, but these methods equally treat two anomaly forms above in the evaluation of abnormal graphs, which is contrary to the fact that different types of abnormal graph data have different degrees in terms of node-level and graph-level anomalies. Furthermore, abnormal graphs that have subtle differences from normal graphs are easily escaped detection by the existing methods. Thus, we propose a multi-representations space separation based graph-level anomaly-aware detection framework in this paper. To consider the different importance of node-level and graph-level anomalies, we design an anomaly-aware module to learn the specific weight between them in the abnormal graph evaluation process. In addition, we learn strictly separate normal and abnormal graph representation spaces by four types of weighted graph representations against each other including anchor normal graphs, anchor abnormal graphs, training normal graphs, and training abnormal graphs. Based on the distance error between the graph representations of the test graph and both normal and abnormal graph representation spaces, we can accurately determine whether the test graph is anomalous. Our approach has been extensively evaluated against baseline methods using ten public graph datasets, and the results demonstrate its effectiveness.
* 11 pages, 12 figures
Reinforcement Learning Guided Multi-Objective Exam Paper Generation
Mar 02, 2023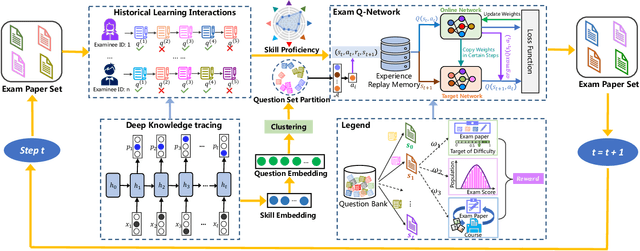

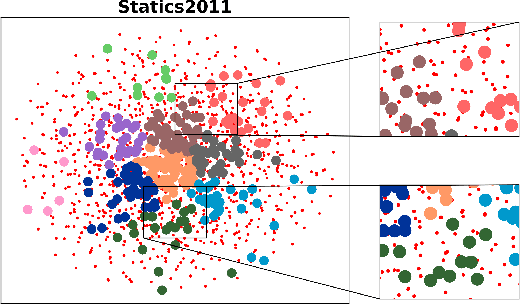
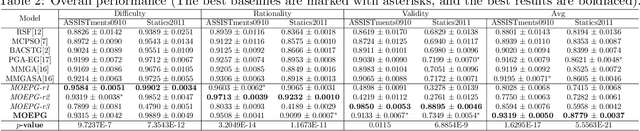
To reduce the repetitive and complex work of instructors, exam paper generation (EPG) technique has become a salient topic in the intelligent education field, which targets at generating high-quality exam paper automatically according to instructor-specified assessment criteria. The current advances utilize the ability of heuristic algorithms to optimize several well-known objective constraints, such as difficulty degree, number of questions, etc., for producing optimal solutions. However, in real scenarios, considering other equally relevant objectives (e.g., distribution of exam scores, skill coverage) is extremely important. Besides, how to develop an automatic multi-objective solution that finds an optimal subset of questions from a huge search space of large-sized question datasets and thus composes a high-quality exam paper is urgent but non-trivial. To this end, we skillfully design a reinforcement learning guided Multi-Objective Exam Paper Generation framework, termed MOEPG, to simultaneously optimize three exam domain-specific objectives including difficulty degree, distribution of exam scores, and skill coverage. Specifically, to accurately measure the skill proficiency of the examinee group, we first employ deep knowledge tracing to model the interaction information between examinees and response logs. We then design the flexible Exam Q-Network, a function approximator, which automatically selects the appropriate question to update the exam paper composition process. Later, MOEPG divides the decision space into multiple subspaces to better guide the updated direction of the exam paper. Through extensive experiments on two real-world datasets, we demonstrate that MOEPG is feasible in addressing the multiple dilemmas of exam paper generation scenario.