 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Prototype Potential: An Efficient Tuning Framework for Few-Shot Class-Incremental Learning
Feb 05, 2026Few-shot class-incremental learning (FSCIL) seeks to continuously learn new classes from very limited samples while preserving previously acquired knowledge. Traditional methods often utilize a frozen pre-trained feature extractor to generate static class prototypes, which suffer from the inherent representation bias of the backbone. While recent prompt-based tuning methods attempt to adapt the backbone via minimal parameter updates, given the constraint of extreme data scarcity, the model's capacity to assimilate novel information and substantively enhance its global discriminative power is inherently limited. In this paper, we propose a novel shift in perspective: freezing the feature extractor while fine-tuning the prototypes. We argue that the primary challenge in FSCIL is not feature acquisition, but rather the optimization of decision regions within a static, high-quality feature space. To this end, we introduce an efficient prototype fine-tuning framework that evolves static centroids into dynamic, learnable components. The framework employs a dual-calibration method consisting of class-specific and task-aware offsets. These components function synergistically to improve the discriminative capacity of prototypes for ongoing incremental classes. Extensive results demonstrate that our method attains superior performance across multiple benchmarks while requiring minimal learnable parameters.
Federated Learning at the Forefront of Fairness: A Multifaceted Perspective
Jan 31, 2026Fairness in Federated Learning (FL) is emerging as a critical factor driven by heterogeneous clients' constraints and balanced model performance across various scenarios. In this survey, we delineate a comprehensive classification of the state-of-the-art fairness-aware approaches from a multifaceted perspective, i.e., model performance-oriented and capability-oriented. Moreover, we provide a framework to categorize and address various fairness concerns and associated technical aspects, examining their effectiveness in balancing equity and performance within FL frameworks. We further examine several significant evaluation metrics leveraged to measure fairness quantitatively. Finally, we explore exciting open research directions and propose prospective solutions that could drive future advancements in this important area, laying a solid foundation for researchers working toward fairness in FL.
CoRe-Fed: Bridging Collaborative and Representation Fairness via Federated Embedding Distillation
Jan 31, 2026With the proliferation of distributed data sources, Federated Learning (FL) has emerged as a key approach to enable collaborative intelligence through decentralized model training while preserving data privacy. However, conventional FL algorithms often suffer from performance disparities across clients caused by heterogeneous data distributions and unequal participation, which leads to unfair outcomes. Specifically, we focus on two core fairness challenges, i.e., representation bias, arising from misaligned client representations, and collaborative bias, stemming from inequitable contribution during aggregation, both of which degrade model performance and generalizability. To mitigate these disparities, we propose CoRe-Fed, a unified optimization framework that bridges collaborative and representation fairness via embedding-level regularization and fairness-aware aggregation. Initially, an alignment-driven mechanism promotes semantic consistency between local and global embeddings to reduce representational divergence. Subsequently, a dynamic reward-penalty-based aggregation strategy adjusts each client's weight based on participation history and embedding alignment to ensure contribution-aware aggregation. Extensive experiments across diverse models and datasets demonstrate that CoRe-Fed improves both fairness and model performance over the state-of-the-art baseline algorithms.
Generalizable IoT Traffic Representations for Cross-Network Device Identification
Jan 27, 2026Machine learning models have demonstrated strong performance in classifying network traffic and identifying Internet-of-Things (IoT) devices, enabling operators to discover and manage IoT assets at scale. However, many existing approaches rely on end-to-end supervised pipelines or task-specific fine-tuning, resulting in traffic representations that are tightly coupled to labeled datasets and deployment environments, which can limit generalizability. In this paper, we study the problem of learning generalizable traffic representations for IoT device identification. We design compact encoder architectures that learn per-flow embeddings from unlabeled IoT traffic and evaluate them using a frozen-encoder protocol with a simple supervised classifier. Our specific contributions are threefold. (1) We develop unsupervised encoder--decoder models that learn compact traffic representations from unlabeled IoT network flows and assess their quality through reconstruction-based analysis. (2) We show that these learned representations can be used effectively for IoT device-type classification using simple, lightweight classifiers trained on frozen embeddings. (3) We provide a systematic benchmarking study against the state-of-the-art pretrained traffic encoders, showing that larger models do not necessarily yield more robust representations for IoT traffic. Using more than 18 million real IoT traffic flows collected across multiple years and deployment environments, we learn traffic representations from unlabeled data and evaluate device-type classification on disjoint labeled subsets, achieving macro F1-scores exceeding 0.9 for device-type classification and demonstrating robustness under cross-environment deployment.
Generative Chain of Behavior for User Trajectory Prediction
Jan 26, 2026Modeling long-term user behavior trajectories is essential for understanding evolving preferences and enabling proactive recommendations. However, most sequential recommenders focus on next-item prediction, overlooking dependencies across multiple future actions. We propose Generative Chain of Behavior (GCB), a generative framework that models user interactions as an autoregressive chain of semantic behaviors over multiple future steps. GCB first encodes items into semantic IDs via RQ-VAE with k-means refinement, forming a discrete latent space that preserves semantic proximity. On top of this space, a transformer-based autoregressive generator predicts multi-step future behaviors conditioned on user history, capturing long-horizon intent transitions and generating coherent trajectories. Experiments on benchmark datasets show that GCB consistently outperforms state-of-the-art sequential recommenders in multi-step accuracy and trajectory consistency. Beyond these gains, GCB offers a unified generative formulation for capturing user preference evolution.
Parameter-Efficient Domain Adaption for CSI Crowd-Counting via Self-Supervised Learning with Adapter Modules
Jan 05, 2026Device-free crowd-counting using WiFi Channel State Information (CSI) is a key enabling technology for a new generation of privacy-preserving Internet of Things (IoT) applications. However, practical deployment is severely hampered by the domain shift problem, where models trained in one environment fail to generalise to another. To overcome this, we propose a novel two-stage framework centred on a CSI-ResNet-A architecture. This model is pre-trained via self-supervised contrastive learning to learn domain-invariant representations and leverages lightweight Adapter modules for highly efficient fine-tuning. The resulting event sequence is then processed by a stateful counting machine to produce a final, stable occupancy estimate. We validate our framework extensively. On our WiFlow dataset, our unsupervised approach excels in a 10-shot learning scenario, achieving a final Mean Absolute Error (MAE) of just 0.44--a task where supervised baselines fail. To formally quantify robustness, we introduce the Generalisation Index (GI), on which our model scores near-perfectly, confirming its ability to generalise. Furthermore, our framework sets a new state-of-the-art public WiAR benchmark with 98.8\% accuracy. Our ablation studies reveal the core strength of our design: adapter-based fine-tuning achieves performance within 1\% of a full fine-tune (98.84\% vs. 99.67\%) while training 97.2\% fewer parameters. Our work provides a practical and scalable solution for developing robust sensing systems ready for real-world IoT deployments.
Plug-and-Play Parameter-Efficient Tuning of Embeddings for Federated Recommendation
Dec 14, 2025With the rise of cloud-edge collaboration, recommendation services are increasingly trained in distributed environments. Federated Recommendation (FR) enables such multi-end collaborative training while preserving privacy by sharing model parameters instead of raw data. However, the large number of parameters, primarily due to the massive item embeddings, significantly hampers communication efficiency. While existing studies mainly focus on improving the efficiency of FR models, they largely overlook the issue of embedding parameter overhead. To address this gap, we propose a FR training framework with Parameter-Efficient Fine-Tuning (PEFT) based embedding designed to reduce the volume of embedding parameters that need to be transmitted. Our approach offers a lightweight, plugin-style solution that can be seamlessly integrated into existing FR methods. In addition to incorporating common PEFT techniques such as LoRA and Hash-based encoding, we explore the use of Residual Quantized Variational Autoencoders (RQ-VAE) as a novel PEFT strategy within our framework. Extensive experiments across various FR model backbones and datasets demonstrate that our framework significantly reduces communication overhead while improving accuracy. The source code is available at https://github.com/young1010/FedPEFT.
Teaching Prompts to Coordinate: Hierarchical Layer-Grouped Prompt Tuning for Continual Learning
Nov 15, 2025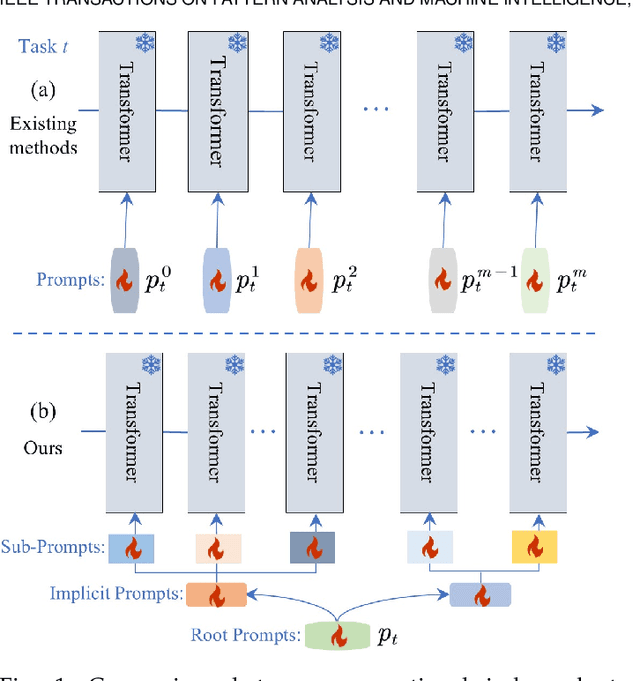
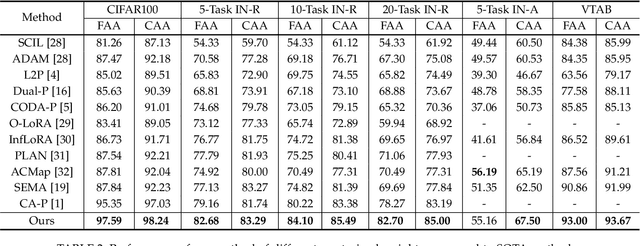
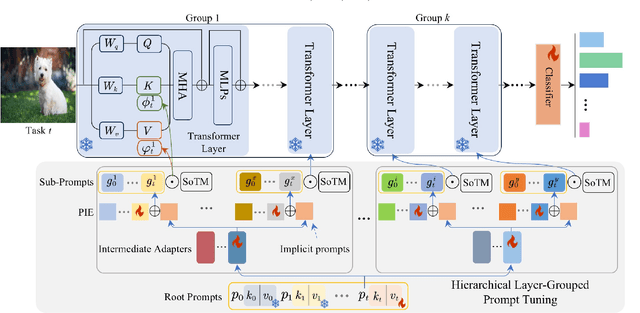
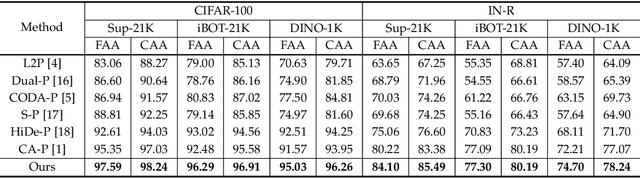
Prompt-based continual learning methods fine-tune only a small set of additional learnable parameters while keeping the pre-trained model's parameters frozen. It enables efficient adaptation to new tasks while mitigating the risk of catastrophic forgetting. These methods typically attach one independent task-specific prompt to each layer of pre-trained models to locally modulate its features, ensuring that the layer's representation aligns with the requirements of the new task. However, although introducing learnable prompts independently at each layer provides high flexibility for adapting to new tasks, this overly flexible tuning could make certain layers susceptible to unnecessary updates. As all prompts till the current task are added together as a final prompt for all seen tasks, the model may easily overwrite feature representations essential to previous tasks, which increases the risk of catastrophic forgetting. To address this issue, we propose a novel hierarchical layer-grouped prompt tuning method for continual learning. It improves model stability in two ways: (i) Layers in the same group share roughly the same prompts, which are adjusted by position encoding. This helps preserve the intrinsic feature relationships and propagation pathways of the pre-trained model within each group. (ii) It utilizes a single task-specific root prompt to learn to generate sub-prompts for each layer group. In this way, all sub-prompts are conditioned on the same root prompt, enhancing their synergy and reducing independence. Extensive experiments across four benchmarks demonstrate that our method achieves favorable performance compared with several state-of-the-art methods.
Self-Supervised Cross-Modal Learning for Image-to-Point Cloud Registration
Sep 19, 2025Bridging 2D and 3D sensor modalities is critical for robust perception in autonomous systems. However, image-to-point cloud (I2P) registration remains challenging due to the semantic-geometric gap between texture-rich but depth-ambiguous images and sparse yet metrically precise point clouds, as well as the tendency of existing methods to converge to local optima. To overcome these limitations, we introduce CrossI2P, a self-supervised framework that unifies cross-modal learning and two-stage registration in a single end-to-end pipeline. First, we learn a geometric-semantic fused embedding space via dual-path contrastive learning, enabling annotation-free, bidirectional alignment of 2D textures and 3D structures. Second, we adopt a coarse-to-fine registration paradigm: a global stage establishes superpoint-superpixel correspondences through joint intra-modal context and cross-modal interaction modeling, followed by a geometry-constrained point-level refinement for precise registration. Third, we employ a dynamic training mechanism with gradient normalization to balance losses for feature alignment, correspondence refinement, and pose estimation. Extensive experiments demonstrate that CrossI2P outperforms state-of-the-art methods by 23.7% on the KITTI Odometry benchmark and by 37.9% on nuScenes, significantly improving both accuracy and robustness.
Adversarial Attacks Against Automated Fact-Checking: A Survey
Sep 10, 2025In an era where misinformation spreads freely, fact-checking (FC) plays a crucial role in verifying claims and promoting reliable information. While automated fact-checking (AFC) has advanced significantly, existing systems remain vulnerable to adversarial attacks that manipulate or generate claims, evidence, or claim-evidence pairs. These attacks can distort the truth, mislead decision-makers, and ultimately undermine the reliability of FC models. Despite growing research interest in adversarial attacks against AFC systems, a comprehensive, holistic overview of key challenges remains lacking. These challenges include understanding attack strategies, assessing the resilience of current models, and identifying ways to enhance robustness. This survey provides the first in-depth review of adversarial attacks targeting FC, categorizing existing attack methodologies and evaluating their impact on AFC systems. Additionally, we examine recent advancements in adversary-aware defenses and highlight open research questions that require further exploration. Our findings underscore the urgent need for resilient FC frameworks capable of withstanding adversarial manipulations in pursuit of preserving high verification accuracy.