 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgenticAI-DialogGen: Topic-Guided Conversation Generation for Fine-Tuning and Evaluating Short- and Long-Term Memories of LLMs
Apr 14, 2026Recent advancements in Large Language Models (LLMs) have improved their ability to process extended conversational contexts, yet fine-tuning and evaluating short- and long-term memories remain difficult due to the absence of datasets that encode both short- and long-term conversational history. Existing conversational datasets lack memory grounding, overlook topic continuity, or rely on costly human annotation. To address these gaps, we introduce AgenticAI-DialogGen, a modular agent-based framework that generates persona-grounded and topic-guided conversations without human supervision. The framework uses LLM agents to extract knowledge graphs, identify topics, build speaker personas, and simulate topic-guided conversations from unstructured conversations. A QA module generates memory-grounded Question Answer (QA) pairs drawn from short- and long-term conversational histories. We also generated a new dataset entitled, TopicGuidedChat (TGC), where long-term memory is encoded as speaker-specific knowledge graphs and short-term memory as newly generated topic-guided conversations. Evaluations depict that AgenticAI-DialogGen yields higher conversational quality and LLMs fine-tuned on TGC dataset achieve improved performance on memory-grounded QA tasks.
CoRe-Fed: Bridging Collaborative and Representation Fairness via Federated Embedding Distillation
Jan 31, 2026With the proliferation of distributed data sources, Federated Learning (FL) has emerged as a key approach to enable collaborative intelligence through decentralized model training while preserving data privacy. However, conventional FL algorithms often suffer from performance disparities across clients caused by heterogeneous data distributions and unequal participation, which leads to unfair outcomes. Specifically, we focus on two core fairness challenges, i.e., representation bias, arising from misaligned client representations, and collaborative bias, stemming from inequitable contribution during aggregation, both of which degrade model performance and generalizability. To mitigate these disparities, we propose CoRe-Fed, a unified optimization framework that bridges collaborative and representation fairness via embedding-level regularization and fairness-aware aggregation. Initially, an alignment-driven mechanism promotes semantic consistency between local and global embeddings to reduce representational divergence. Subsequently, a dynamic reward-penalty-based aggregation strategy adjusts each client's weight based on participation history and embedding alignment to ensure contribution-aware aggregation. Extensive experiments across diverse models and datasets demonstrate that CoRe-Fed improves both fairness and model performance over the state-of-the-art baseline algorithms.
Federated Learning at the Forefront of Fairness: A Multifaceted Perspective
Jan 31, 2026Fairness in Federated Learning (FL) is emerging as a critical factor driven by heterogeneous clients' constraints and balanced model performance across various scenarios. In this survey, we delineate a comprehensive classification of the state-of-the-art fairness-aware approaches from a multifaceted perspective, i.e., model performance-oriented and capability-oriented. Moreover, we provide a framework to categorize and address various fairness concerns and associated technical aspects, examining their effectiveness in balancing equity and performance within FL frameworks. We further examine several significant evaluation metrics leveraged to measure fairness quantitatively. Finally, we explore exciting open research directions and propose prospective solutions that could drive future advancements in this important area, laying a solid foundation for researchers working toward fairness in FL.
When Large Language Models Meet Citation: A Survey
Sep 18, 2023



Citations in scholarly work serve the essential purpose of acknowledging and crediting the original sources of knowledge that have been incorporated or referenced. Depending on their surrounding textual context, these citations are used for different motivations and purposes. Large Language Models (LLMs) could be helpful in capturing these fine-grained citation information via the corresponding textual context, thereby enabling a better understanding towards the literature. Furthermore, these citations also establish connections among scientific papers, providing high-quality inter-document relationships and human-constructed knowledge. Such information could be incorporated into LLMs pre-training and improve the text representation in LLMs. Therefore, in this paper, we offer a preliminary review of the mutually beneficial relationship between LLMs and citation analysis. Specifically, we review the application of LLMs for in-text citation analysis tasks, including citation classification, citation-based summarization, and citation recommendation. We then summarize the research pertinent to leveraging citation linkage knowledge to improve text representations of LLMs via citation prediction, network structure information, and inter-document relationship. We finally provide an overview of these contemporary methods and put forth potential promising avenues in combining LLMs and citation analysis for further investigation.
Learning to Select the Relevant History Turns in Conversational Question Answering
Aug 04, 2023



The increasing demand for the web-based digital assistants has given a rapid rise in the interest of the Information Retrieval (IR) community towards the field of conversational question answering (ConvQA). However, one of the critical aspects of ConvQA is the effective selection of conversational history turns to answer the question at hand. The dependency between relevant history selection and correct answer prediction is an intriguing but under-explored area. The selected relevant context can better guide the system so as to where exactly in the passage to look for an answer. Irrelevant context, on the other hand, brings noise to the system, thereby resulting in a decline in the model's performance. In this paper, we propose a framework, DHS-ConvQA (Dynamic History Selection in Conversational Question Answering), that first generates the context and question entities for all the history turns, which are then pruned on the basis of similarity they share in common with the question at hand. We also propose an attention-based mechanism to re-rank the pruned terms based on their calculated weights of how useful they are in answering the question. In the end, we further aid the model by highlighting the terms in the re-ranked conversational history using a binary classification task and keeping the useful terms (predicted as 1) and ignoring the irrelevant terms (predicted as 0). We demonstrate the efficacy of our proposed framework with extensive experimental results on CANARD and QuAC -- the two popularly utilized datasets in ConvQA. We demonstrate that selecting relevant turns works better than rewriting the original question. We also investigate how adding the irrelevant history turns negatively impacts the model's performance and discuss the research challenges that demand more attention from the IR community.
Keeping the Questions Conversational: Using Structured Representations to Resolve Dependency in Conversational Question Answering
Apr 14, 2023Having an intelligent dialogue agent that can engage in conversational question answering (ConvQA) is now no longer limited to Sci-Fi movies only and has, in fact, turned into a reality. These intelligent agents are required to understand and correctly interpret the sequential turns provided as the context of the given question. However, these sequential questions are sometimes left implicit and thus require the resolution of some natural language phenomena such as anaphora and ellipsis. The task of question rewriting has the potential to address the challenges of resolving dependencies amongst the contextual turns by transforming them into intent-explicit questions. Nonetheless, the solution of rewriting the implicit questions comes with some potential challenges such as resulting in verbose questions and taking conversational aspect out of the scenario by generating self-contained questions. In this paper, we propose a novel framework, CONVSR (CONVQA using Structured Representations) for capturing and generating intermediate representations as conversational cues to enhance the capability of the QA model to better interpret the incomplete questions. We also deliberate how the strengths of this task could be leveraged in a bid to design more engaging and eloquent conversational agents. We test our model on the QuAC and CANARD datasets and illustrate by experimental results that our proposed framework achieves a better F1 score than the standard question rewriting model.
GCN-based Multi-task Representation Learning for Anomaly Detection in Attributed Networks
Jul 08, 2022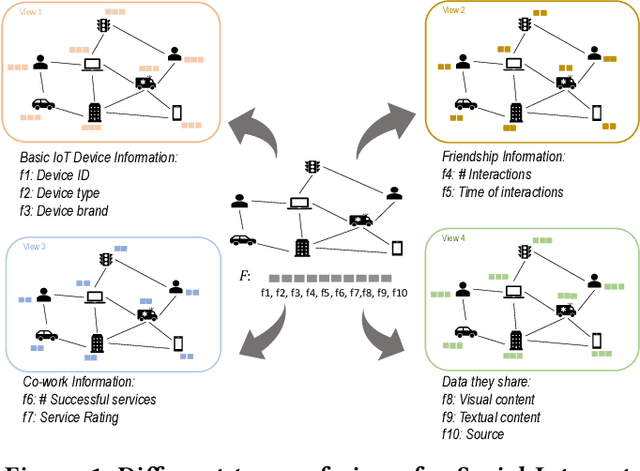
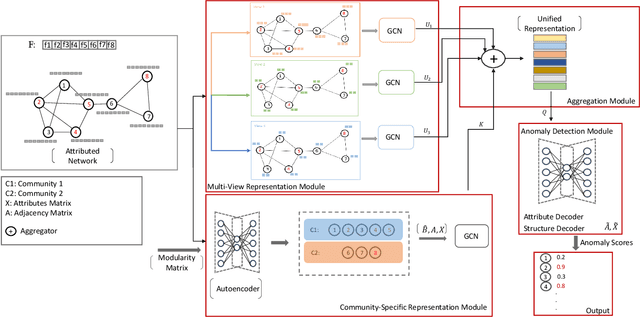
Anomaly detection in attributed networks has received a considerable attention in recent years due to its applications in a wide range of domains such as finance, network security, and medicine. Traditional approaches cannot be adopted on attributed networks' settings to solve the problem of anomaly detection. The main limitation of such approaches is that they inherently ignore the relational information between data features. With a rapid explosion in deep learning- and graph neural networks-based techniques, spotting rare objects on attributed networks has significantly stepped forward owing to the potentials of deep techniques in extracting complex relationships. In this paper, we propose a new architecture on anomaly detection. The main goal of designing such an architecture is to utilize multi-task learning which would enhance the detection performance. Multi-task learning-based anomaly detection is still in its infancy and only a few studies in the existing literature have catered to the same. We incorporate both community detection and multi-view representation learning techniques for extracting distinct and complementary information from attributed networks and subsequently fuse the captured information for achieving a better detection result. The mutual collaboration between two main components employed in this architecture, i.e., community-specific learning and multi-view representation learning, exhibits a promising solution to reach more effective results.
A Survey on Participant Selection for Federated Learning in Mobile Networks
Jul 08, 2022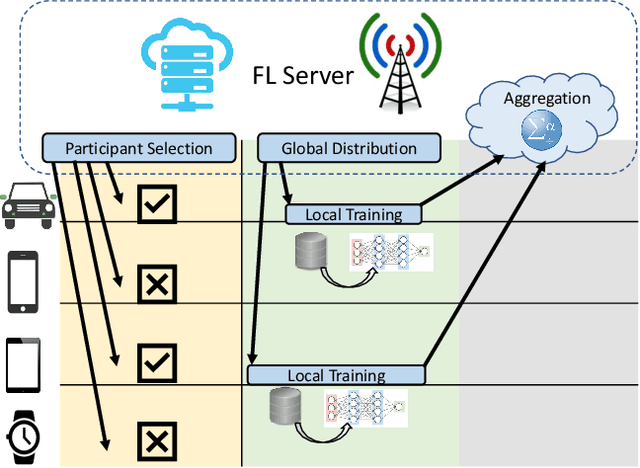
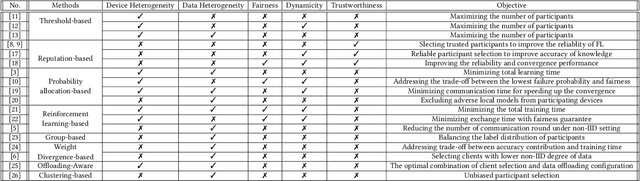
Federated Learning (FL) is an efficient distributed machine learning paradigm that employs private datasets in a privacy-preserving manner. The main challenges of FL is that end devices usually possess various computation and communication capabilities and their training data are not independent and identically distributed (non-IID). Due to limited communication bandwidth and unstable availability of such devices in a mobile network, only a fraction of end devices (also referred to as the participants or clients in a FL process) can be selected in each round. Hence, it is of paramount importance to utilize an efficient participant selection scheme to maximize the performance of FL including final model accuracy and training time. In this paper, we provide a review of participant selection techniques for FL. First, we introduce FL and highlight the main challenges during participant selection. Then, we review the existing studies and categorize them based on their solutions. Finally, we provide some future directions on participant selection for FL based on our analysis of the state-of-the-art in this topic area.
Conversational Question Answering: A Survey
Jun 03, 2021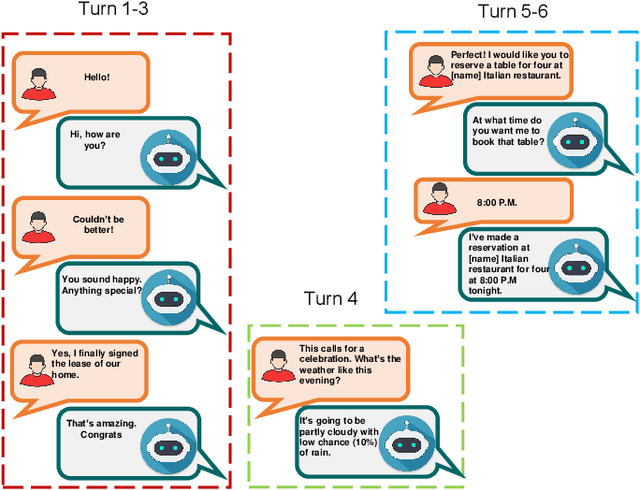

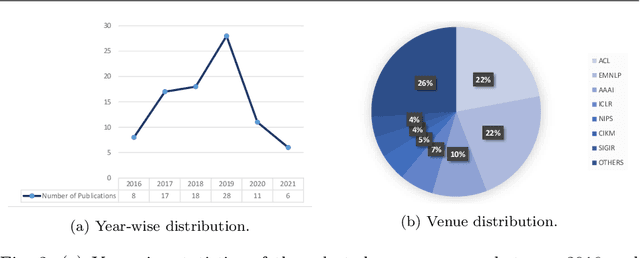
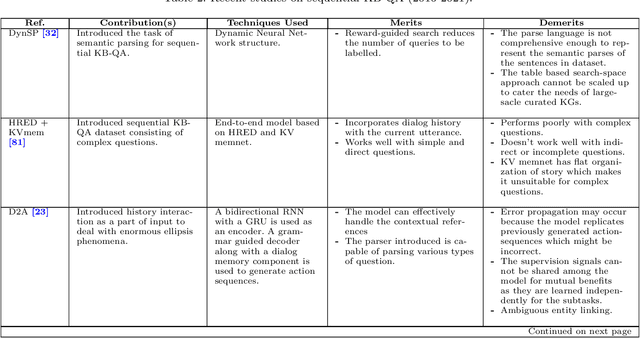
Question answering (QA) systems provide a way of querying the information available in various formats including, but not limited to, unstructured and structured data in natural languages. It constitutes a considerable part of conversational artificial intelligence (AI) which has led to the introduction of a special research topic on Conversational Question Answering (CQA), wherein a system is required to understand the given context and then engages in multi-turn QA to satisfy the user's information needs. Whilst the focus of most of the existing research work is subjected to single-turn QA, the field of multi-turn QA has recently grasped attention and prominence owing to the availability of large-scale, multi-turn QA datasets and the development of pre-trained language models. With a good amount of models and research papers adding to the literature every year recently, there is a dire need of arranging and presenting the related work in a unified manner to streamline future research. This survey, therefore, is an effort to present a comprehensive review of the state-of-the-art research trends of CQA primarily based on reviewed papers from 2016-2021. Our findings show that there has been a trend shift from single-turn to multi-turn QA which empowers the field of Conversational AI from different perspectives. This survey is intended to provide an epitome for the research community with the hope of laying a strong foundation for the field of CQA.
BERT-CoQAC: BERT-based Conversational Question Answering in Context
Apr 23, 2021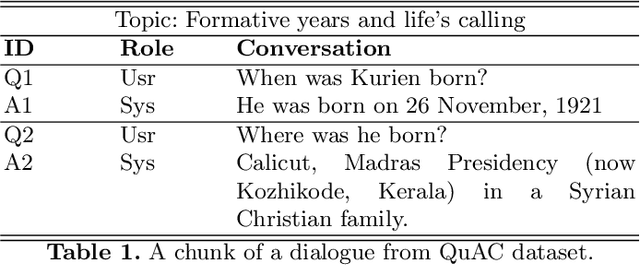
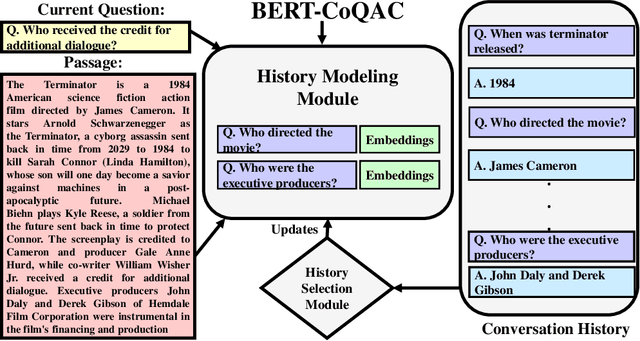
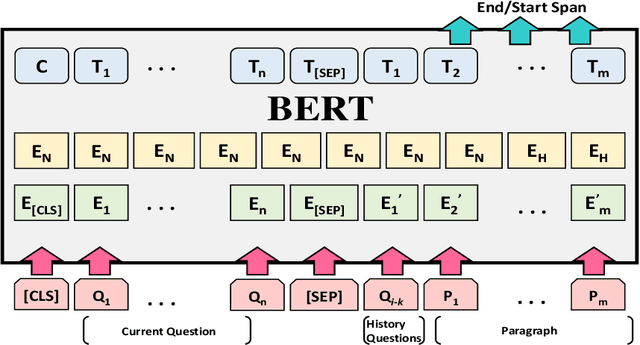
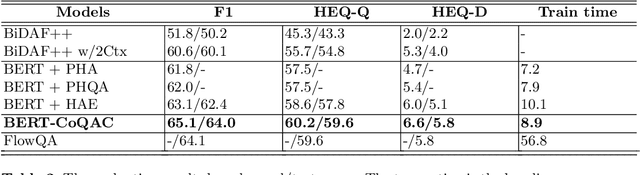
As one promising way to inquire about any particular information through a dialog with the bot, question answering dialog systems have gained increasing research interests recently. Designing interactive QA systems has always been a challenging task in natural language processing and used as a benchmark to evaluate a machine's ability of natural language understanding. However, such systems often struggle when the question answering is carried out in multiple turns by the users to seek more information based on what they have already learned, thus, giving rise to another complicated form called Conversational Question Answering (CQA). CQA systems are often criticized for not understanding or utilizing the previous context of the conversation when answering the questions. To address the research gap, in this paper, we explore how to integrate conversational history into the neural machine comprehension system. On one hand, we introduce a framework based on a publically available pre-trained language model called BERT for incorporating history turns into the system. On the other hand, we propose a history selection mechanism that selects the turns that are relevant and contributes the most to answer the current question. Experimentation results revealed that our framework is comparable in performance with the state-of-the-art models on the QuAC leader board. We also conduct a number of experiments to show the side effects of using entire context information which brings unnecessary information and noise signals resulting in a decline in the model's performance.