 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistractor Generation for Multiple-Choice Questions: A Survey of Methods, Datasets, and Evaluation
Feb 02, 2024Distractors are important in learning evaluation. This paper surveys distractor generation tasks using English multiple-choice question datasets for textual and multimodal contexts. In particular, this paper presents a thorough literature review of the recent studies on distractor generation tasks, discusses multiple choice components and their characteristics, analyzes the related datasets, and summarizes the evaluation metrics of distractor generation. Our investigation reveals that more than half of datasets are human-generated from educational sources in specific domains such as Science and English, which are largely text-based, with a lack of open domain and multimodal datasets.
Learning to Select the Relevant History Turns in Conversational Question Answering
Aug 04, 2023



The increasing demand for the web-based digital assistants has given a rapid rise in the interest of the Information Retrieval (IR) community towards the field of conversational question answering (ConvQA). However, one of the critical aspects of ConvQA is the effective selection of conversational history turns to answer the question at hand. The dependency between relevant history selection and correct answer prediction is an intriguing but under-explored area. The selected relevant context can better guide the system so as to where exactly in the passage to look for an answer. Irrelevant context, on the other hand, brings noise to the system, thereby resulting in a decline in the model's performance. In this paper, we propose a framework, DHS-ConvQA (Dynamic History Selection in Conversational Question Answering), that first generates the context and question entities for all the history turns, which are then pruned on the basis of similarity they share in common with the question at hand. We also propose an attention-based mechanism to re-rank the pruned terms based on their calculated weights of how useful they are in answering the question. In the end, we further aid the model by highlighting the terms in the re-ranked conversational history using a binary classification task and keeping the useful terms (predicted as 1) and ignoring the irrelevant terms (predicted as 0). We demonstrate the efficacy of our proposed framework with extensive experimental results on CANARD and QuAC -- the two popularly utilized datasets in ConvQA. We demonstrate that selecting relevant turns works better than rewriting the original question. We also investigate how adding the irrelevant history turns negatively impacts the model's performance and discuss the research challenges that demand more attention from the IR community.
Keeping the Questions Conversational: Using Structured Representations to Resolve Dependency in Conversational Question Answering
Apr 14, 2023Having an intelligent dialogue agent that can engage in conversational question answering (ConvQA) is now no longer limited to Sci-Fi movies only and has, in fact, turned into a reality. These intelligent agents are required to understand and correctly interpret the sequential turns provided as the context of the given question. However, these sequential questions are sometimes left implicit and thus require the resolution of some natural language phenomena such as anaphora and ellipsis. The task of question rewriting has the potential to address the challenges of resolving dependencies amongst the contextual turns by transforming them into intent-explicit questions. Nonetheless, the solution of rewriting the implicit questions comes with some potential challenges such as resulting in verbose questions and taking conversational aspect out of the scenario by generating self-contained questions. In this paper, we propose a novel framework, CONVSR (CONVQA using Structured Representations) for capturing and generating intermediate representations as conversational cues to enhance the capability of the QA model to better interpret the incomplete questions. We also deliberate how the strengths of this task could be leveraged in a bid to design more engaging and eloquent conversational agents. We test our model on the QuAC and CANARD datasets and illustrate by experimental results that our proposed framework achieves a better F1 score than the standard question rewriting model.
Conversational Question Answering: A Survey
Jun 03, 2021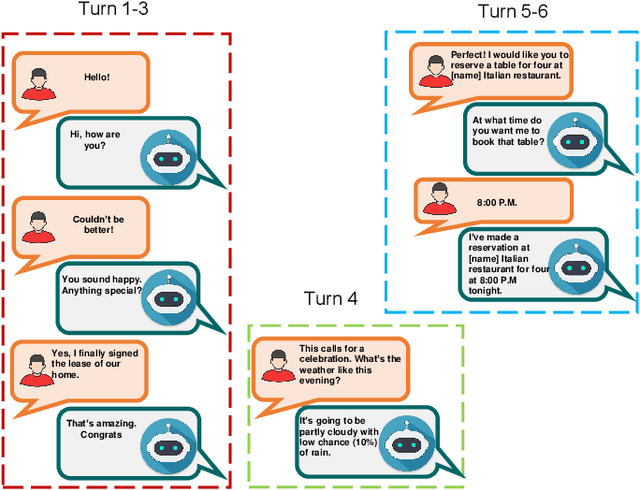

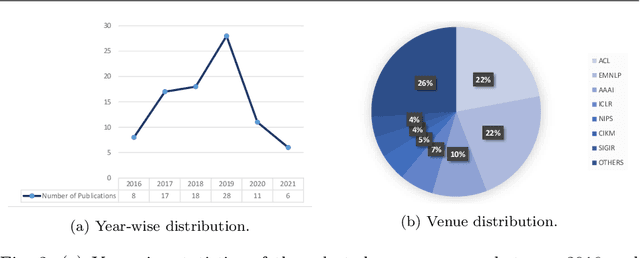
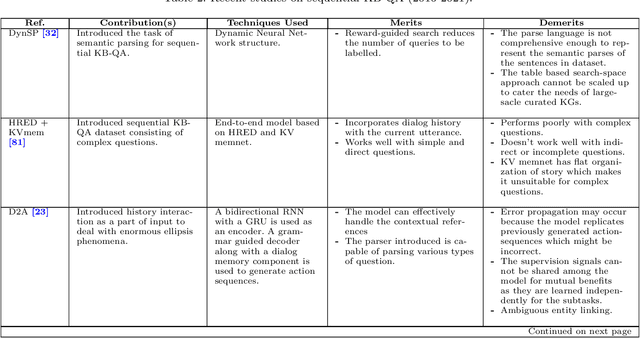
Question answering (QA) systems provide a way of querying the information available in various formats including, but not limited to, unstructured and structured data in natural languages. It constitutes a considerable part of conversational artificial intelligence (AI) which has led to the introduction of a special research topic on Conversational Question Answering (CQA), wherein a system is required to understand the given context and then engages in multi-turn QA to satisfy the user's information needs. Whilst the focus of most of the existing research work is subjected to single-turn QA, the field of multi-turn QA has recently grasped attention and prominence owing to the availability of large-scale, multi-turn QA datasets and the development of pre-trained language models. With a good amount of models and research papers adding to the literature every year recently, there is a dire need of arranging and presenting the related work in a unified manner to streamline future research. This survey, therefore, is an effort to present a comprehensive review of the state-of-the-art research trends of CQA primarily based on reviewed papers from 2016-2021. Our findings show that there has been a trend shift from single-turn to multi-turn QA which empowers the field of Conversational AI from different perspectives. This survey is intended to provide an epitome for the research community with the hope of laying a strong foundation for the field of CQA.
BERT-CoQAC: BERT-based Conversational Question Answering in Context
Apr 23, 2021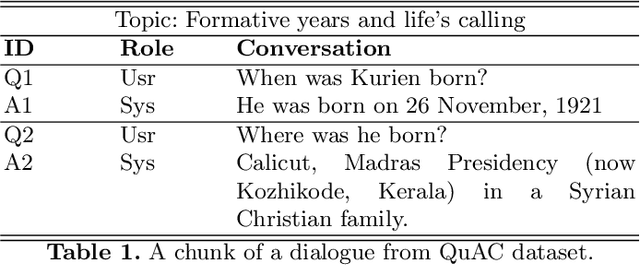
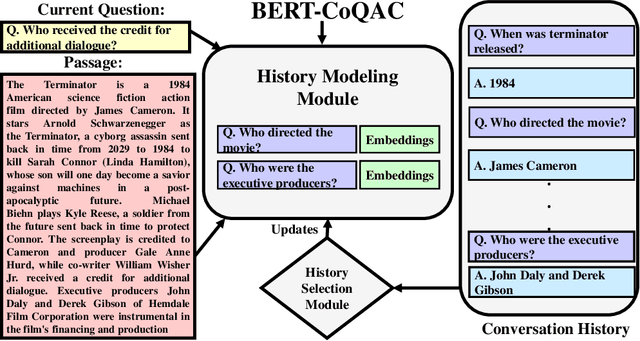
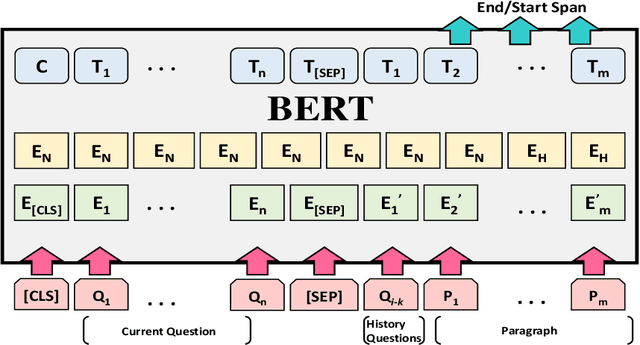
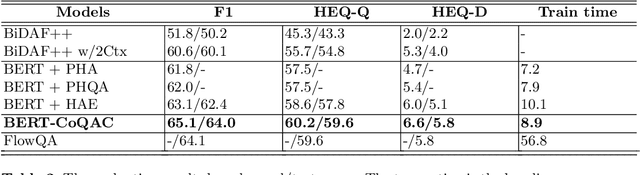
As one promising way to inquire about any particular information through a dialog with the bot, question answering dialog systems have gained increasing research interests recently. Designing interactive QA systems has always been a challenging task in natural language processing and used as a benchmark to evaluate a machine's ability of natural language understanding. However, such systems often struggle when the question answering is carried out in multiple turns by the users to seek more information based on what they have already learned, thus, giving rise to another complicated form called Conversational Question Answering (CQA). CQA systems are often criticized for not understanding or utilizing the previous context of the conversation when answering the questions. To address the research gap, in this paper, we explore how to integrate conversational history into the neural machine comprehension system. On one hand, we introduce a framework based on a publically available pre-trained language model called BERT for incorporating history turns into the system. On the other hand, we propose a history selection mechanism that selects the turns that are relevant and contributes the most to answer the current question. Experimentation results revealed that our framework is comparable in performance with the state-of-the-art models on the QuAC leader board. We also conduct a number of experiments to show the side effects of using entire context information which brings unnecessary information and noise signals resulting in a decline in the model's performance.
A Short Survey of Pre-trained Language Models for Conversational AI-A NewAge in NLP
Apr 22, 2021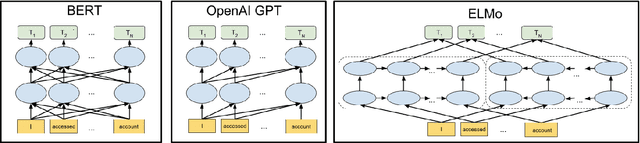

Building a dialogue system that can communicate naturally with humans is a challenging yet interesting problem of agent-based computing. The rapid growth in this area is usually hindered by the long-standing problem of data scarcity as these systems are expected to learn syntax, grammar, decision making, and reasoning from insufficient amounts of task-specific dataset. The recently introduced pre-trained language models have the potential to address the issue of data scarcity and bring considerable advantages by generating contextualized word embeddings. These models are considered counterpart of ImageNet in NLP and have demonstrated to capture different facets of language such as hierarchical relations, long-term dependency, and sentiment. In this short survey paper, we discuss the recent progress made in the field of pre-trained language models. We also deliberate that how the strengths of these language models can be leveraged in designing more engaging and more eloquent conversational agents. This paper, therefore, intends to establish whether these pre-trained models can overcome the challenges pertinent to dialogue systems, and how their architecture could be exploited in order to overcome these challenges. Open challenges in the field of dialogue systems have also been deliberated.
Deep Conversational Recommender Systems: A New Frontier for Goal-Oriented Dialogue Systems
Apr 28, 2020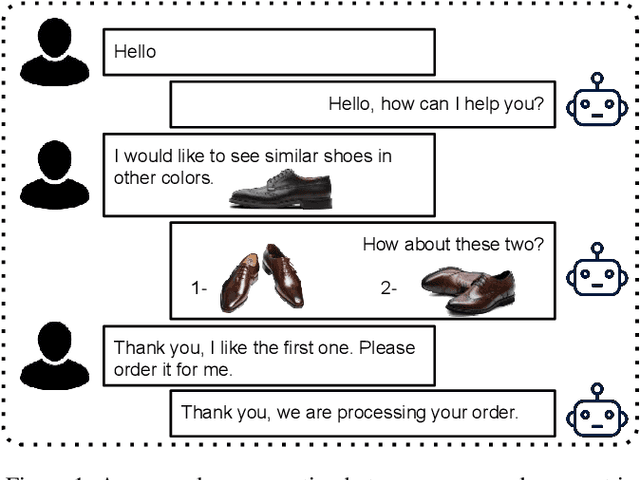
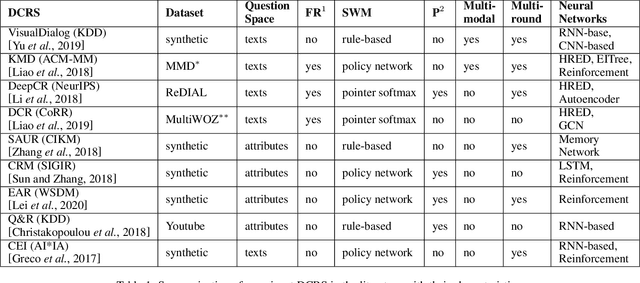
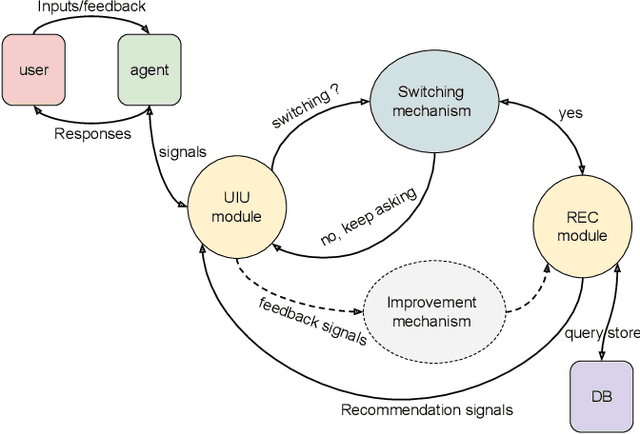
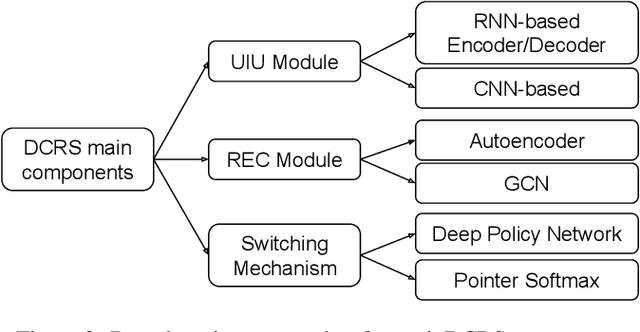
In recent years, the emerging topics of recommender systems that take advantage of natural language processing techniques have attracted much attention, and one of their applications is the Conversational Recommender System (CRS). Unlike traditional recommender systems with content-based and collaborative filtering approaches, CRS learns and models user's preferences through interactive dialogue conversations. In this work, we provide a summarization of the recent evolution of CRS, where deep learning approaches are applied to CRS and have produced fruitful results. We first analyze the research problems and present key challenges in the development of Deep Conversational Recommender Systems (DCRS), then present the current state of the field taken from the most recent researches, including the most common deep learning models that benefit DCRS. Finally, we discuss future directions for this vibrant area.