 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Prototype Potential: An Efficient Tuning Framework for Few-Shot Class-Incremental Learning
Feb 05, 2026Few-shot class-incremental learning (FSCIL) seeks to continuously learn new classes from very limited samples while preserving previously acquired knowledge. Traditional methods often utilize a frozen pre-trained feature extractor to generate static class prototypes, which suffer from the inherent representation bias of the backbone. While recent prompt-based tuning methods attempt to adapt the backbone via minimal parameter updates, given the constraint of extreme data scarcity, the model's capacity to assimilate novel information and substantively enhance its global discriminative power is inherently limited. In this paper, we propose a novel shift in perspective: freezing the feature extractor while fine-tuning the prototypes. We argue that the primary challenge in FSCIL is not feature acquisition, but rather the optimization of decision regions within a static, high-quality feature space. To this end, we introduce an efficient prototype fine-tuning framework that evolves static centroids into dynamic, learnable components. The framework employs a dual-calibration method consisting of class-specific and task-aware offsets. These components function synergistically to improve the discriminative capacity of prototypes for ongoing incremental classes. Extensive results demonstrate that our method attains superior performance across multiple benchmarks while requiring minimal learnable parameters.
BrainVista: Modeling Naturalistic Brain Dynamics as Multimodal Next-Token Prediction
Feb 04, 2026Naturalistic fMRI characterizes the brain as a dynamic predictive engine driven by continuous sensory streams. However, modeling the causal forward evolution in realistic neural simulation is impeded by the timescale mismatch between multimodal inputs and the complex topology of cortical networks. To address these challenges, we introduce BrainVista, a multimodal autoregressive framework designed to model the causal evolution of brain states. BrainVista incorporates Network-wise Tokenizers to disentangle system-specific dynamics and a Spatial Mixer Head that captures inter-network information flow without compromising functional boundaries. Furthermore, we propose a novel Stimulus-to-Brain (S2B) masking mechanism to synchronize high-frequency sensory stimuli with hemodynamically filtered signals, enabling strict, history-only causal conditioning. We validate our framework on Algonauts 2025, CineBrain, and HAD, achieving state-of-the-art fMRI encoding performance. In long-horizon rollout settings, our model yields substantial improvements over baselines, increasing pattern correlation by 36.0\% and 33.3\% on relative to the strongest baseline Algonauts 2025 and CineBrain, respectively.
MemWeaver: Weaving Hybrid Memories for Traceable Long-Horizon Agentic Reasoning
Jan 26, 2026Large language model-based agents operating in long-horizon interactions require memory systems that support temporal consistency, multi-hop reasoning, and evidence-grounded reuse across sessions. Existing approaches largely rely on unstructured retrieval or coarse abstractions, which often lead to temporal conflicts, brittle reasoning, and limited traceability. We propose MemWeaver, a unified memory framework that consolidates long-term agent experiences into three interconnected components: a temporally grounded graph memory for structured relational reasoning, an experience memory that abstracts recurring interaction patterns from repeated observations, and a passage memory that preserves original textual evidence. MemWeaver employs a dual-channel retrieval strategy that jointly retrieves structured knowledge and supporting evidence to construct compact yet information-dense contexts for reasoning. Experiments on the LoCoMo benchmark demonstrate that MemWeaver substantially improves multi-hop and temporal reasoning accuracy while reducing input context length by over 95\% compared to long-context baselines.
Generative Chain of Behavior for User Trajectory Prediction
Jan 26, 2026Modeling long-term user behavior trajectories is essential for understanding evolving preferences and enabling proactive recommendations. However, most sequential recommenders focus on next-item prediction, overlooking dependencies across multiple future actions. We propose Generative Chain of Behavior (GCB), a generative framework that models user interactions as an autoregressive chain of semantic behaviors over multiple future steps. GCB first encodes items into semantic IDs via RQ-VAE with k-means refinement, forming a discrete latent space that preserves semantic proximity. On top of this space, a transformer-based autoregressive generator predicts multi-step future behaviors conditioned on user history, capturing long-horizon intent transitions and generating coherent trajectories. Experiments on benchmark datasets show that GCB consistently outperforms state-of-the-art sequential recommenders in multi-step accuracy and trajectory consistency. Beyond these gains, GCB offers a unified generative formulation for capturing user preference evolution.
ParaMETA: Towards Learning Disentangled Paralinguistic Speaking Styles Representations from Speech
Jan 18, 2026Learning representative embeddings for different types of speaking styles, such as emotion, age, and gender, is critical for both recognition tasks (e.g., cognitive computing and human-computer interaction) and generative tasks (e.g., style-controllable speech generation). In this work, we introduce ParaMETA, a unified and flexible framework for learning and controlling speaking styles directly from speech. Unlike existing methods that rely on single-task models or cross-modal alignment, ParaMETA learns disentangled, task-specific embeddings by projecting speech into dedicated subspaces for each type of style. This design reduces inter-task interference, mitigates negative transfer, and allows a single model to handle multiple paralinguistic tasks such as emotion, gender, age, and language classification. Beyond recognition, ParaMETA enables fine-grained style control in Text-To-Speech (TTS) generative models. It supports both speech- and text-based prompting and allows users to modify one speaking styles while preserving others. Extensive experiments demonstrate that ParaMETA outperforms strong baselines in classification accuracy and generates more natural and expressive speech, while maintaining a lightweight and efficient model suitable for real-world applications.
PruneRAG: Confidence-Guided Query Decomposition Trees for Efficient Retrieval-Augmented Generation
Jan 16, 2026Retrieval-augmented generation (RAG) has become a powerful framework for enhancing large language models in knowledge-intensive and reasoning tasks. However, as reasoning chains deepen or search trees expand, RAG systems often face two persistent failures: evidence forgetting, where retrieved knowledge is not effectively used, and inefficiency, caused by uncontrolled query expansions and redundant retrieval. These issues reveal a critical gap between retrieval and evidence utilization in current RAG architectures. We propose PruneRAG, a confidence-guided query decomposition framework that builds a structured query decomposition tree to perform stable and efficient reasoning. PruneRAG introduces three key mechanisms: adaptive node expansion that regulates tree width and depth, confidence-guided decisions that accept reliable answers and prune uncertain branches, and fine-grained retrieval that extracts entity-level anchors to improve retrieval precision. Together, these components preserve salient evidence throughout multi-hop reasoning while significantly reducing retrieval overhead. To better analyze evidence misuse, we define the Evidence Forgetting Rate as a metric to quantify cases where golden evidence is retrieved but not correctly used. Extensive experiments across various multi-hop QA benchmarks show that PruneRAG achieves superior accuracy and efficiency over state-of-the-art baselines.
SceneAlign: Aligning Multimodal Reasoning to Scene Graphs in Complex Visual Scenes
Jan 09, 2026Multimodal large language models often struggle with faithful reasoning in complex visual scenes, where intricate entities and relations require precise visual grounding at each step. This reasoning unfaithfulness frequently manifests as hallucinated entities, mis-grounded relations, skipped steps, and over-specified reasoning. Existing preference-based approaches, typically relying on textual perturbations or answer-conditioned rationales, fail to address this challenge as they allow models to exploit language priors to bypass visual grounding. To address this, we propose SceneAlign, a framework that leverages scene graphs as structured visual information to perform controllable structural interventions. By identifying reasoning-critical nodes and perturbing them through four targeted strategies that mimic typical grounding failures, SceneAlign constructs hard negative rationales that remain linguistically plausible but are grounded in inaccurate visual facts. These contrastive pairs are used in Direct Preference Optimization to steer models toward fine-grained, structure-faithful reasoning. Across seven visual reasoning benchmarks, SceneAlign consistently improves answer accuracy and reasoning faithfulness, highlighting the effectiveness of grounding-aware alignment for multimodal reasoning.
Teaching Prompts to Coordinate: Hierarchical Layer-Grouped Prompt Tuning for Continual Learning
Nov 15, 2025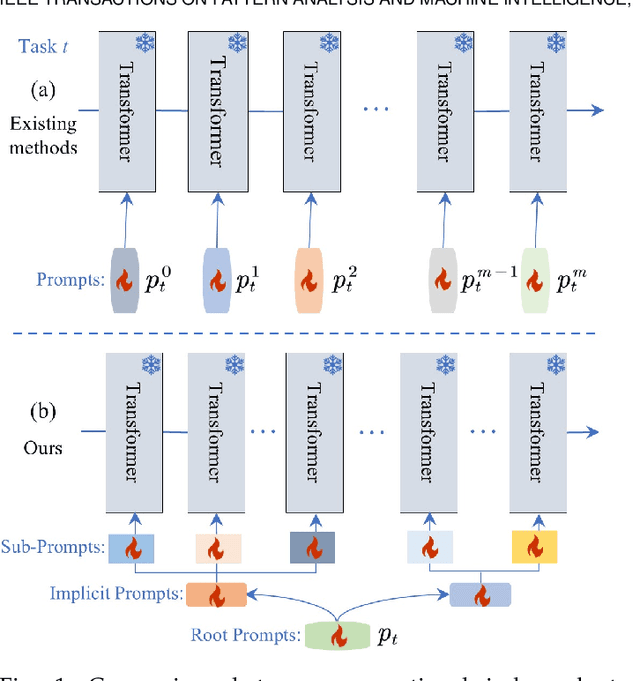
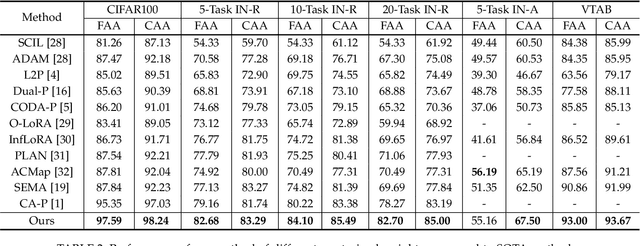
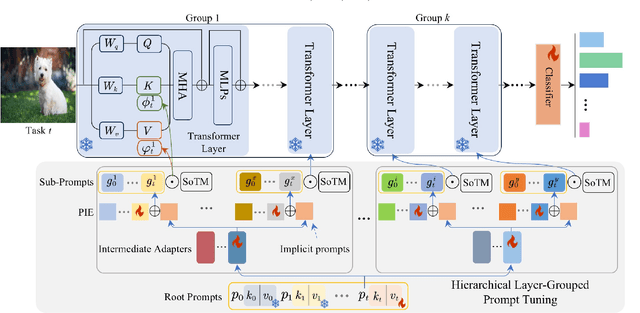
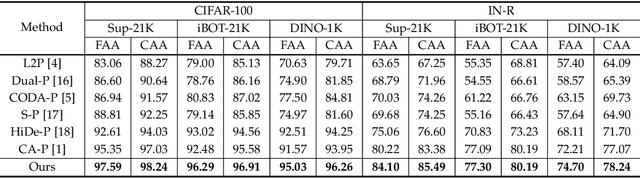
Prompt-based continual learning methods fine-tune only a small set of additional learnable parameters while keeping the pre-trained model's parameters frozen. It enables efficient adaptation to new tasks while mitigating the risk of catastrophic forgetting. These methods typically attach one independent task-specific prompt to each layer of pre-trained models to locally modulate its features, ensuring that the layer's representation aligns with the requirements of the new task. However, although introducing learnable prompts independently at each layer provides high flexibility for adapting to new tasks, this overly flexible tuning could make certain layers susceptible to unnecessary updates. As all prompts till the current task are added together as a final prompt for all seen tasks, the model may easily overwrite feature representations essential to previous tasks, which increases the risk of catastrophic forgetting. To address this issue, we propose a novel hierarchical layer-grouped prompt tuning method for continual learning. It improves model stability in two ways: (i) Layers in the same group share roughly the same prompts, which are adjusted by position encoding. This helps preserve the intrinsic feature relationships and propagation pathways of the pre-trained model within each group. (ii) It utilizes a single task-specific root prompt to learn to generate sub-prompts for each layer group. In this way, all sub-prompts are conditioned on the same root prompt, enhancing their synergy and reducing independence. Extensive experiments across four benchmarks demonstrate that our method achieves favorable performance compared with several state-of-the-art methods.
Self-Supervised Cross-Modal Learning for Image-to-Point Cloud Registration
Sep 19, 2025Bridging 2D and 3D sensor modalities is critical for robust perception in autonomous systems. However, image-to-point cloud (I2P) registration remains challenging due to the semantic-geometric gap between texture-rich but depth-ambiguous images and sparse yet metrically precise point clouds, as well as the tendency of existing methods to converge to local optima. To overcome these limitations, we introduce CrossI2P, a self-supervised framework that unifies cross-modal learning and two-stage registration in a single end-to-end pipeline. First, we learn a geometric-semantic fused embedding space via dual-path contrastive learning, enabling annotation-free, bidirectional alignment of 2D textures and 3D structures. Second, we adopt a coarse-to-fine registration paradigm: a global stage establishes superpoint-superpixel correspondences through joint intra-modal context and cross-modal interaction modeling, followed by a geometry-constrained point-level refinement for precise registration. Third, we employ a dynamic training mechanism with gradient normalization to balance losses for feature alignment, correspondence refinement, and pose estimation. Extensive experiments demonstrate that CrossI2P outperforms state-of-the-art methods by 23.7% on the KITTI Odometry benchmark and by 37.9% on nuScenes, significantly improving both accuracy and robustness.
Ensemble Distribution Distillation for Self-Supervised Human Activity Recognition
Sep 10, 2025Human Activity Recognition (HAR) has seen significant advancements with the adoption of deep learning techniques, yet challenges remain in terms of data requirements, reliability and robustness. This paper explores a novel application of Ensemble Distribution Distillation (EDD) within a self-supervised learning framework for HAR aimed at overcoming these challenges. By leveraging unlabeled data and a partially supervised training strategy, our approach yields an increase in predictive accuracy, robust estimates of uncertainty, and substantial increases in robustness against adversarial perturbation; thereby significantly improving reliability in real-world scenarios without increasing computational complexity at inference. We demonstrate this with an evaluation on several publicly available datasets. The contributions of this work include the development of a self-supervised EDD framework, an innovative data augmentation technique designed for HAR, and empirical validation of the proposed method's effectiveness in increasing robustness and reliability.