 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Image Priors for Black-box Data-free Knowledge Distillation
Apr 28, 2026Knowledge distillation (KD) represents a vital mechanism to transfer expertise from complex teacher networks to efficient student models. However, in decentralized or secure AI ecosystems, privacy regulations and proprietary interests often restrict access to the teacher's interface and original datasets. These constraints define a challenging black-box data-free KD scenario where only top-1 predictions and no training data are available. While recent approaches utilize synthetic data, they still face limitations in data diversity and distillation signals. We propose Diverse Image Priors Knowledge Distillation (DIP-KD), a framework that addresses these challenges through a three-phase collaborative pipeline: (1) Synthesis of image priors to capture diverse visual patterns and semantics; (2) Contrast to enhance the collective distinction between synthetic samples via contrastive learning; and (3) Distillation via a novel primer student that enables soft-probability KD. Our evaluation across 12 benchmarks shows that DIP-KD achieves state-of-the-art performance, with ablations confirming data diversity as critical for knowledge acquisition in restricted AI environments.
Improving Diversity in Black-box Few-shot Knowledge Distillation
Apr 28, 2026Knowledge distillation (KD) is a well-known technique to effectively compress a large network (teacher) to a smaller network (student) with little sacrifice in performance. However, most KD methods require a large training set and internal access to the teacher, which are rarely available due to various restrictions. These challenges have originated a more practical setting known as black-box few-shot KD, where the student is trained with few images and a black-box teacher. Recent approaches typically generate additional synthetic images but lack an active strategy to promote their diversity, a crucial factor for student learning. To address these problems, we propose a novel training scheme for generative adversarial networks, where we adaptively select high-confidence images under the teacher's supervision and introduce them to the adversarial learning on-the-fly. Our approach helps expand and improve the diversity of the distillation set, significantly boosting student accuracy. Through extensive experiments, we achieve state-of-the-art results among other few-shot KD methods on seven image datasets. The code is available at https://github.com/votrinhan88/divbfkd.
Domain-Adapted Fine-Tuning of ECG Foundation Models for Multi-Label Structural Heart Disease Screening
Apr 25, 2026Transthoracic echocardiography is the reference standard for confirming structural heart disease (SHD), but first-line screening is limited by cost, workflow burden, and specialist availability. We evaluated whether open pretrained electrocardiogram (ECG) foundation models can support echo-confirmed multi-label SHD detection using the public EchoNext Mini-Model benchmark. Six echocardiography-derived abnormalities were targeted: reduced left ventricular ejection fraction, increased left ventricular wall thickness, aortic stenosis, mitral regurgitation, tricuspid regurgitation, and right ventricular systolic dysfunction. Under a common pipeline, we compared engineered ECG features with gradient boosting, end-to-end waveform learning from scratch, and transfer from open ECG foundation models. We then applied in-domain self-supervised adaptation of an ECG foundation model (ECG-FM) on EchoNext waveforms followed by selective supervised fine-tuning, and evaluated trade-offs between discrimination and adaptation cost. Adapted ECG-FM models achieved the best overall performance: peak macro-AUROC 0.8509 and macro-AUPRC 0.4297, while a parameter-efficient operating point preserved AUROC (0.8501) and attained the highest fixed-threshold macro-F1 0.3691. Late fusion with covariates did not improve threshold-independent discrimination, and evaluated LoRA, alternative backbones, and mixture-of-foundations strategies did not surpass the best adapted single-backbone models. These results indicate that for ECG-based case finding and echocardiography triage, combining target-domain self-supervised adaptation with selective supervised updating of a pretrained ECG backbone is the most effective transfer strategy.
Adaptive Acquisition Selection for Bayesian Optimization with Large Language Models
Feb 08, 2026Bayesian Optimization critically depends on the choice of acquisition function, but no single strategy is universally optimal; the best choice is non-stationary and problem-dependent. Existing adaptive portfolio methods often base their decisions on past function values while ignoring richer information like remaining budget or surrogate model characteristics. To address this, we introduce LMABO, a novel framework that casts a pre-trained Large Language Model (LLM) as a zero-shot, online strategist for the BO process. At each iteration, LMABO uses a structured state representation to prompt the LLM to select the most suitable acquisition function from a diverse portfolio. In an evaluation across 50 benchmark problems, LMABO demonstrates a significant performance improvement over strong static, adaptive portfolio, and other LLM-based baselines. We show that the LLM's behavior is a comprehensive strategy that adapts to real-time progress, proving its advantage stems from its ability to process and synthesize the complete optimization state into an effective, adaptive policy.
ChartAB: A Benchmark for Chart Grounding & Dense Alignment
Oct 30, 2025Charts play an important role in visualization, reasoning, data analysis, and the exchange of ideas among humans. However, existing vision-language models (VLMs) still lack accurate perception of details and struggle to extract fine-grained structures from charts. Such limitations in chart grounding also hinder their ability to compare multiple charts and reason over them. In this paper, we introduce a novel "ChartAlign Benchmark (ChartAB)" to provide a comprehensive evaluation of VLMs in chart grounding tasks, i.e., extracting tabular data, localizing visualization elements, and recognizing various attributes from charts of diverse types and complexities. We design a JSON template to facilitate the calculation of evaluation metrics specifically tailored for each grounding task. By incorporating a novel two-stage inference workflow, the benchmark can further evaluate VLMs' capability to align and compare elements/attributes across two charts. Our analysis of evaluations on several recent VLMs reveals new insights into their perception biases, weaknesses, robustness, and hallucinations in chart understanding. These findings highlight the fine-grained discrepancies among VLMs in chart understanding tasks and point to specific skills that need to be strengthened in current models.
Data Selection for Fine-tuning Vision Language Models via Cross Modal Alignment Trajectories
Oct 01, 2025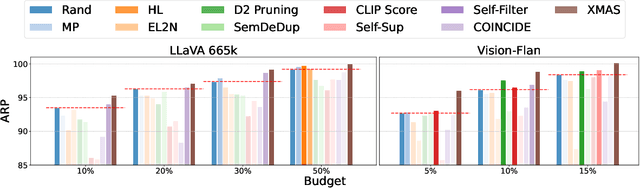

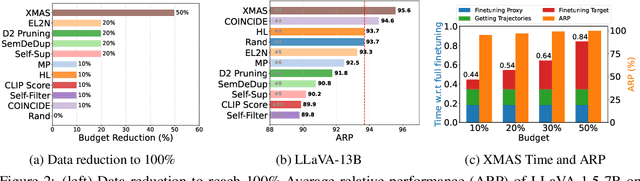

Data-efficient learning aims to eliminate redundancy in large training datasets by training models on smaller subsets of the most informative examples. While data selection has been extensively explored for vision models and large language models (LLMs), it remains underexplored for Large Vision-Language Models (LVLMs). Notably, none of existing methods can outperform random selection at different subset sizes. In this work, we propose the first principled method for data-efficient instruction tuning of LVLMs. We prove that examples with similar cross-modal attention matrices during instruction tuning have similar gradients. Thus, they influence model parameters in a similar manner and convey the same information to the model during training. Building on this insight, we propose XMAS, which clusters examples based on the trajectories of the top singular values of their attention matrices obtained from fine-tuning a small proxy LVLM. By sampling a balanced subset from these clusters, XMAS effectively removes redundancy in large-scale LVLM training data. Extensive experiments show that XMAS can discard 50% of the LLaVA-665k dataset and 85% of the Vision-Flan dataset while fully preserving performance of LLaVA-1.5-7B on 10 downstream benchmarks and speeding up its training by 1.2x. This is 30% more data reduction compared to the best baseline for LLaVA-665k. The project's website can be found at https://bigml-cs-ucla.github.io/XMAS-project-page/.
FaSTA$^*$: Fast-Slow Toolpath Agent with Subroutine Mining for Efficient Multi-turn Image Editing
Jun 26, 2025We develop a cost-efficient neurosymbolic agent to address challenging multi-turn image editing tasks such as "Detect the bench in the image while recoloring it to pink. Also, remove the cat for a clearer view and recolor the wall to yellow.'' It combines the fast, high-level subtask planning by large language models (LLMs) with the slow, accurate, tool-use, and local A$^*$ search per subtask to find a cost-efficient toolpath -- a sequence of calls to AI tools. To save the cost of A$^*$ on similar subtasks, we perform inductive reasoning on previously successful toolpaths via LLMs to continuously extract/refine frequently used subroutines and reuse them as new tools for future tasks in an adaptive fast-slow planning, where the higher-level subroutines are explored first, and only when they fail, the low-level A$^*$ search is activated. The reusable symbolic subroutines considerably save exploration cost on the same types of subtasks applied to similar images, yielding a human-like fast-slow toolpath agent "FaSTA$^*$'': fast subtask planning followed by rule-based subroutine selection per subtask is attempted by LLMs at first, which is expected to cover most tasks, while slow A$^*$ search is only triggered for novel and challenging subtasks. By comparing with recent image editing approaches, we demonstrate FaSTA$^*$ is significantly more computationally efficient while remaining competitive with the state-of-the-art baseline in terms of success rate.
Do We Need All the Synthetic Data? Towards Targeted Synthetic Image Augmentation via Diffusion Models
May 27, 2025



Synthetically augmenting training datasets with diffusion models has been an effective strategy for improving generalization of image classifiers. However, existing techniques struggle to ensure the diversity of generation and increase the size of the data by up to 10-30x to improve the in-distribution performance. In this work, we show that synthetically augmenting part of the data that is not learned early in training outperforms augmenting the entire dataset. By analyzing a two-layer CNN, we prove that this strategy improves generalization by promoting homogeneity in feature learning speed without amplifying noise. Our extensive experiments show that by augmenting only 30%-40% of the data, our method boosts the performance by up to 2.8% in a variety of scenarios, including training ResNet, ViT and DenseNet on CIFAR-10, CIFAR-100, and TinyImageNet, with a range of optimizers including SGD and SAM. Notably, our method applied with SGD outperforms the SOTA optimizer, SAM, on CIFAR-100 and TinyImageNet. It can also easily stack with existing weak and strong augmentation strategies to further boost the performance.
ColorBench: Can VLMs See and Understand the Colorful World? A Comprehensive Benchmark for Color Perception, Reasoning, and Robustness
Apr 10, 2025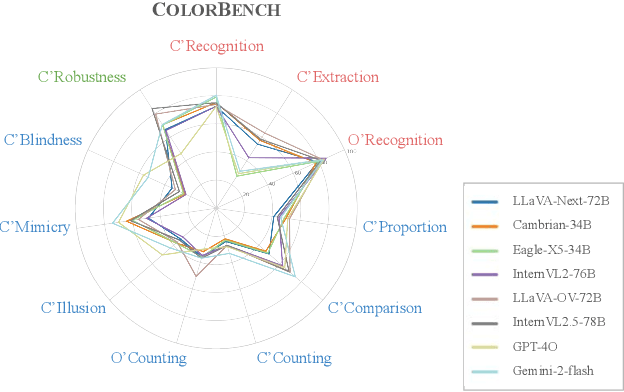
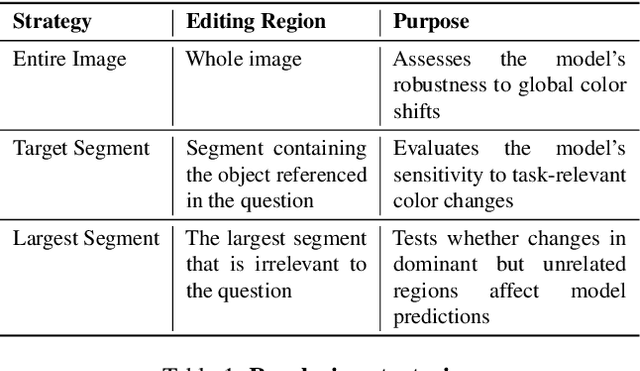
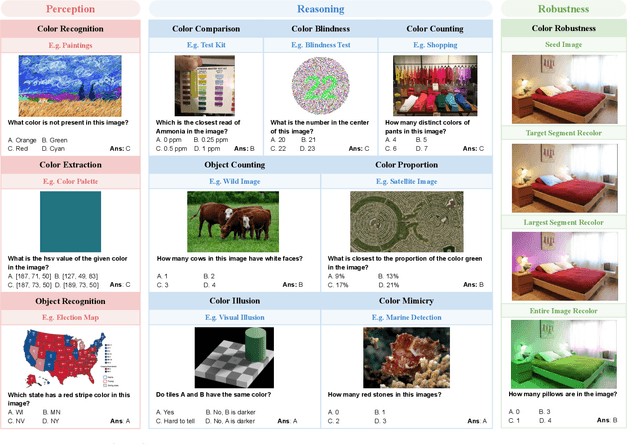
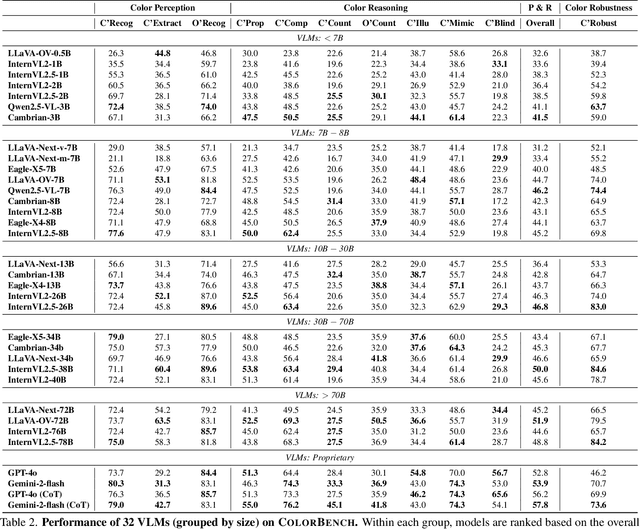
Color plays an important role in human perception and usually provides critical clues in visual reasoning. However, it is unclear whether and how vision-language models (VLMs) can perceive, understand, and leverage color as humans. This paper introduces ColorBench, an innovative benchmark meticulously crafted to assess the capabilities of VLMs in color understanding, including color perception, reasoning, and robustness. By curating a suite of diverse test scenarios, with grounding in real applications, ColorBench evaluates how these models perceive colors, infer meanings from color-based cues, and maintain consistent performance under varying color transformations. Through an extensive evaluation of 32 VLMs with varying language models and vision encoders, our paper reveals some undiscovered findings: (i) The scaling law (larger models are better) still holds on ColorBench, while the language model plays a more important role than the vision encoder. (ii) However, the performance gaps across models are relatively small, indicating that color understanding has been largely neglected by existing VLMs. (iii) CoT reasoning improves color understanding accuracies and robustness, though they are vision-centric tasks. (iv) Color clues are indeed leveraged by VLMs on ColorBench but they can also mislead models in some tasks. These findings highlight the critical limitations of current VLMs and underscore the need to enhance color comprehension. Our ColorBenchcan serve as a foundational tool for advancing the study of human-level color understanding of multimodal AI.
On the Effectiveness and Generalization of Race Representations for Debiasing High-Stakes Decisions
Apr 07, 2025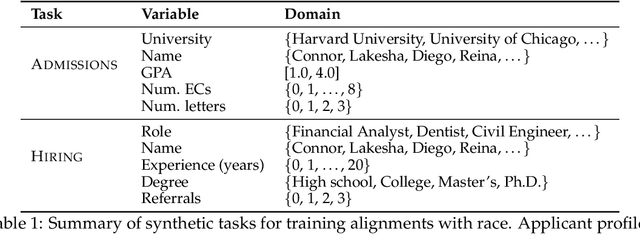
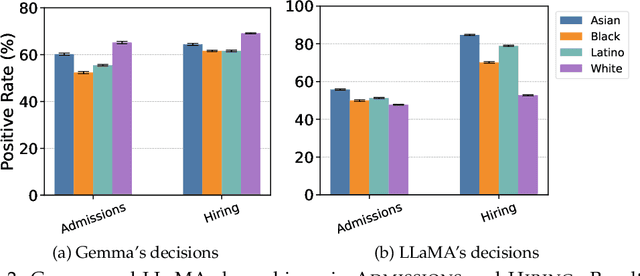
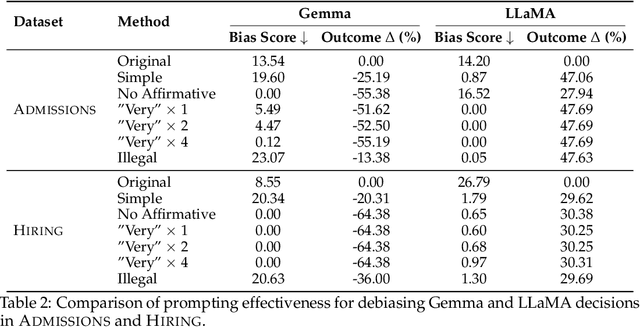
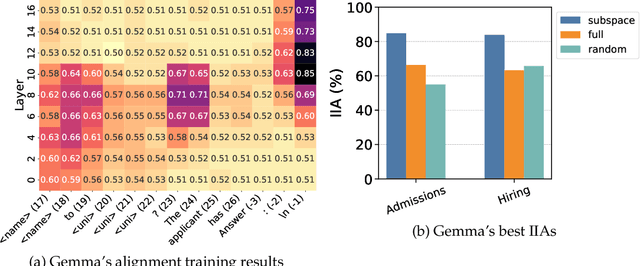
Understanding and mitigating biases is critical for the adoption of large language models (LLMs) in high-stakes decision-making. We introduce Admissions and Hiring, decision tasks with hypothetical applicant profiles where a person's race can be inferred from their name, as simplified test beds for racial bias. We show that Gemma 2B Instruct and LLaMA 3.2 3B Instruct exhibit strong biases. Gemma grants admission to 26% more White than Black applicants, and LLaMA hires 60% more Asian than White applicants. We demonstrate that these biases are resistant to prompt engineering: multiple prompting strategies all fail to promote fairness. In contrast, using distributed alignment search, we can identify "race subspaces" within model activations and intervene on them to debias model decisions. Averaging the representation across all races within the subspaces reduces Gemma's bias by 37-57%. Finally, we examine the generalizability of Gemma's race subspaces, and find limited evidence for generalization, where changing the prompt format can affect the race representation. Our work suggests mechanistic approaches may provide a promising venue for improving the fairness of LLMs, but a universal race representation remains elusive.