 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkip a Layer or Loop It? Learning Program-of-Layers in LLMs
Jun 04, 2026Large language models (LLMs) perform inference by following a fixed depth and order, non-recurrent execution of all layers. We reveal the wide existence of training-free, flexible, dynamic program-of-layers (PoLar), where pretrained layers can be packed as modules and then skipped or looped to form a customized program for each input. For most inputs, substantially shorter program executions can achieve the same or better accuracy, while incorrect predictions of the original LLM can be corrected by alternative programs with fewer layers. These observations indicate that inference admits multiple valid latent computations beyond the standard forward pass. To efficiently achieve PoLar in practice, we propose a lightweight PoLar prediction network, which learns to generate execution programs that dynamically skip or repeat pretrained layers for each input. Experiments on mathematical reasoning benchmarks demonstrate that PoLar consistently improves accuracy over standard inference and prior dynamic-depth methods, often while executing fewer layers, and that these gains persist under out-of-distribution evaluation. Our results suggest that fixed-depth execution captures only a narrow subset of an LLM's latent reasoning capacity.
Plan First, Judge Later, Run Better: A DMAIC-Inspired Agentic System for Industrial Anomaly Detection
Jun 03, 2026Large language model (LLM) agents have shown promise in automating complex data-analysis workflows, but their reliable deployment remains challenging in high-stakes industrial scenarios. Industrial anomaly detection (IAD) is essential for manufacturing quality, safety, and efficiency, yet existing LLM-based IAD agents mainly focus on execution while under-exploiting strategy formulation. Consequently, they struggle to handle heterogeneous modalities in a unified and cost-effective manner. Inspired by the DMAIC quality-management framework, we propose DMAIC-IAD (DMAIC-inspired Agentic Industrial Anomaly Detection), a "Plan First, Judge Later" multi-agent system that aligns LLM agents with structured industrial problem-solving. DMAIC-IAD distills heterogeneous references into standardized operating procedures (SOPs) before strategy generation, and introduces a pre-trained execution-free judge model to rank candidate strategies without costly runtime trials. Extensive experiments across four modalities show that DMAIC-IAD improves average detection performance over applicable agentic baselines by 37.76%.
Adaptive Patching Is Harder Than It Looks For Time-Series Forecasting
Jun 02, 2026Adaptive patching is a recent and compelling proposal for time-series Transformers: allocate finer patches where the sequence looks locally informative. This paper asks under what conditions a content-adaptive patching operator should outperform a tuned uniform one. Local heterogeneity alone is not enough: under pointwise forecasting losses, a complex-looking region is not automatically one where finer patching reduces the loss. We model patching as a budgeted bitrate allocation and derive an explicit threshold that a dynamic patching rule must satisfy to beat a well-tuned uniform baseline, then bound the achievable improvement both locally (a quadratic surrogate) and globally (a strong-convexity bound under the model's assumptions). Two structural results follow: without a coupling constraint, scalar local complexity cannot produce a non-uniform optimum under a common loss landscape; and once the backbone is trained to its representation-aware optimum, the alignment gain collapses around a well-tuned uniform patch size. To test these predictions, we run a controlled isolation study on three representative architectures, replacing each adaptive mechanism with a uniform patch-size sweep while keeping the backbone, data, and training protocol fixed. On standard long-horizon forecasting benchmarks, the validation-selected uniform baseline is competitive with the dynamic counterpart, with per-setting effects concentrated near zero and no consistent directional advantage once results are aggregated by dataset. The larger gains we do observe are method- and dataset-specific. Adaptive patching should therefore be evaluated against a tuned uniform baseline; its value depends on whether a cheap and reliable routing signal can identify where finer patches actually reduce forecasting loss.
HAD: Heterogeneity-Aware Distillation for Lifelong Heterogeneous Learning
Mar 27, 2026Lifelong learning aims to preserve knowledge acquired from previous tasks while incorporating knowledge from a sequence of new tasks. However, most prior work explores only streams of homogeneous tasks (\textit{e.g.}, only classification tasks) and neglects the scenario of learning across heterogeneous tasks that possess different structures of outputs. In this work, we formalize this broader setting as lifelong heterogeneous learning (LHL). Departing from conventional lifelong learning, the task sequence of LHL spans different task types, and the learner needs to retain heterogeneous knowledge for different output space structures. To instantiate the LHL, we focus on LHL in the context of dense prediction (LHL4DP), a realistic and challenging scenario. To this end, we propose the Heterogeneity-Aware Distillation (HAD) method, an exemplar-free approach that preserves previously gained heterogeneous knowledge by self-distillation in each training phase. The proposed HAD comprises two complementary components, including a distribution-balanced heterogeneity-aware distillation loss to alleviate the global imbalance of prediction distribution and a salience-guided heterogeneity-aware distillation loss that concentrates learning on informative edge pixels extracted with the Sobel operator. Extensive experiments demonstrate that the proposed HAD method significantly outperforms existing methods in this new scenario.
Review of Passenger Flow Modelling Approaches Based on a Bibliometric Analysis
Nov 12, 2025This paper presents a bibliometric analysis of the field of short-term passenger flow forecasting within local public transit, covering 814 publications that span from 1984 to 2024. In addition to common bibliometric analysis tools, a variant of a citation network was developed, and topic modelling was conducted. The analysis reveals that research activity exhibited sporadic patterns prior to 2008, followed by a marked acceleration, characterised by a shift from conventional statistical and machine learning methodologies (e.g., ARIMA, SVM, and basic neural networks) to specialised deep learning architectures. Based on this insight, a connection to more general fields such as machine learning and time series modelling was established. In addition to modelling, spatial, linguistic, and modal biases were identified and findings from existing secondary literature were validated and quantified. This revealed existing gaps, such as constrained data fusion, open (multivariate) data, and underappreciated challenges related to model interpretability, cost-efficiency, and a balance between algorithmic performance and practical deployment considerations. In connection with the superordinate fields, the growth in relevance of foundation models is also noteworthy.
Routing Manifold Alignment Improves Generalization of Mixture-of-Experts LLMs
Nov 12, 2025Sparse Mixture-of-Experts (MoE) have been widely adopted in recent large language models since it can efficiently scale up the model capability without increasing the inference cost. However, evaluations on broad downstream tasks reveal a consistent suboptimality of the routers in existing MoE LLMs, which results in a severe performance gap (e.g., 10-20% in accuracy) to the optimal routing. In this paper, we show that aligning the manifold of routing weights with that of task embedding can effectively reduce the gap and improve MoE LLMs' generalization performance. Our method, "Routing Manifold Alignment (RoMA)", introduces an additional manifold regularization term in the post-training objective and only requires lightweight finetuning of routers (with other parameters frozen). Specifically, the regularization encourages the routing weights of each sample to be close to those of its successful neighbors (whose routing weights lead to correct answers) in a task embedding space. Consequently, samples targeting similar tasks will share similar expert choices across layers. Building such bindings between tasks and experts over different samples is essential to achieve better generalization. Moreover, RoMA demonstrates the advantage of unifying the task understanding (by embedding models) with solution generation (by MoE LLMs). In experiments, we finetune routers in OLMoE, DeepSeekMoE, and Qwen3-MoE using RoMA. Evaluations on diverse benchmarks and extensive comparisons with baselines show the substantial improvement brought by RoMA.
GTR-Bench: Evaluating Geo-Temporal Reasoning in Vision-Language Models
Oct 09, 2025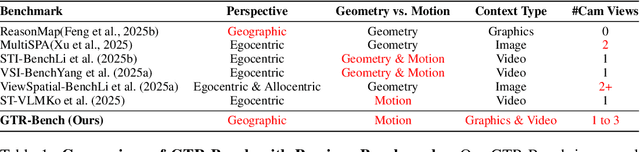
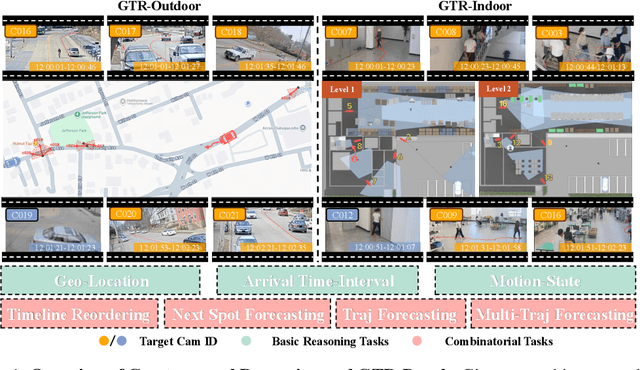
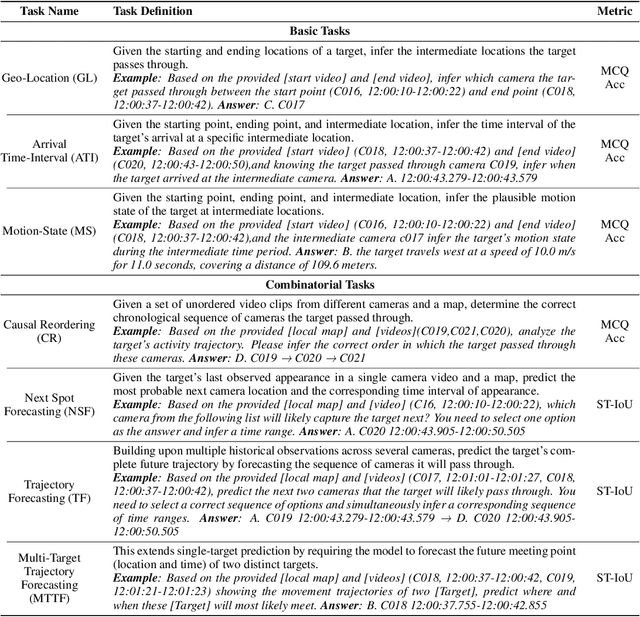
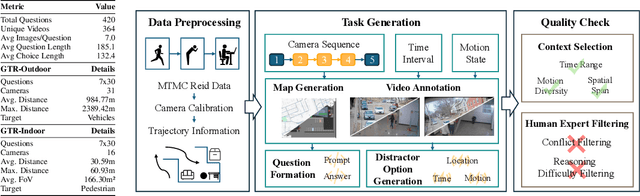
Recently spatial-temporal intelligence of Visual-Language Models (VLMs) has attracted much attention due to its importance for Autonomous Driving, Embodied AI and General Artificial Intelligence. Existing spatial-temporal benchmarks mainly focus on egocentric perspective reasoning with images/video context, or geographic perspective reasoning with graphics context (eg. a map), thus fail to assess VLMs' geographic spatial-temporal intelligence with both images/video and graphics context, which is important for areas like traffic management and emergency response. To address the gaps, we introduce Geo-Temporal Reasoning benchmark (GTR-Bench), a novel challenge for geographic temporal reasoning of moving targets in a large-scale camera network. GTR-Bench is more challenging as it requires multiple perspective switches between maps and videos, joint reasoning across multiple videos with non-overlapping fields of view, and inference over spatial-temporal regions that are unobserved by any video context. Evaluations of more than 10 popular VLMs on GTR-Bench demonstrate that even the best proprietary model, Gemini-2.5-Pro (34.9%), significantly lags behind human performance (78.61%) on geo-temporal reasoning. Moreover, our comprehensive analysis on GTR-Bench reveals three primary deficiencies of current models for geo-temporal reasoning. (1) VLMs' reasoning is impaired by an imbalanced utilization of spatial-temporal context. (2) VLMs are weak in temporal forecasting, which leads to worse performance on temporal-emphasized tasks than on spatial-emphasized tasks. (3) VLMs lack the proficiency to comprehend or align the map data with multi-view video inputs. We believe GTR-Bench offers valuable insights and opens up new opportunities for research and applications in spatial-temporal intelligence. Benchmark and code will be released at https://github.com/X-Luffy/GTR-Bench.
Language-Instructed Reasoning for Group Activity Detection via Multimodal Large Language Model
Sep 19, 2025Group activity detection (GAD) aims to simultaneously identify group members and categorize their collective activities within video sequences. Existing deep learning-based methods develop specialized architectures (e.g., transformer networks) to model the dynamics of individual roles and semantic dependencies between individuals and groups. However, they rely solely on implicit pattern recognition from visual features and struggle with contextual reasoning and explainability. In this work, we propose LIR-GAD, a novel framework of language-instructed reasoning for GAD via Multimodal Large Language Model (MLLM). Our approach expand the original vocabulary of MLLM by introducing an activity-level <ACT> token and multiple cluster-specific <GROUP> tokens. We process video frames alongside two specially designed tokens and language instructions, which are then integrated into the MLLM. The pretrained commonsense knowledge embedded in the MLLM enables the <ACT> token and <GROUP> tokens to effectively capture the semantic information of collective activities and learn distinct representational features of different groups, respectively. Also, we introduce a multi-label classification loss to further enhance the <ACT> token's ability to learn discriminative semantic representations. Then, we design a Multimodal Dual-Alignment Fusion (MDAF) module that integrates MLLM's hidden embeddings corresponding to the designed tokens with visual features, significantly enhancing the performance of GAD. Both quantitative and qualitative experiments demonstrate the superior performance of our proposed method in GAD taks.
Fishing for Answers: Exploring One-shot vs. Iterative Retrieval Strategies for Retrieval Augmented Generation
Sep 05, 2025Retrieval-Augmented Generation (RAG) based on Large Language Models (LLMs) is a powerful solution to understand and query the industry's closed-source documents. However, basic RAG often struggles with complex QA tasks in legal and regulatory domains, particularly when dealing with numerous government documents. The top-$k$ strategy frequently misses golden chunks, leading to incomplete or inaccurate answers. To address these retrieval bottlenecks, we explore two strategies to improve evidence coverage and answer quality. The first is a One-SHOT retrieval method that adaptively selects chunks based on a token budget, allowing as much relevant content as possible to be included within the model's context window. Additionally, we design modules to further filter and refine the chunks. The second is an iterative retrieval strategy built on a Reasoning Agentic RAG framework, where a reasoning LLM dynamically issues search queries, evaluates retrieved results, and progressively refines the context over multiple turns. We identify query drift and retrieval laziness issues and further design two modules to tackle them. Through extensive experiments on a dataset of government documents, we aim to offer practical insights and guidance for real-world applications in legal and regulatory domains.
HiPlan: Hierarchical Planning for LLM-Based Agents with Adaptive Global-Local Guidance
Aug 26, 2025Large language model (LLM)-based agents have demonstrated remarkable capabilities in decision-making tasks, but struggle significantly with complex, long-horizon planning scenarios. This arises from their lack of macroscopic guidance, causing disorientation and failures in complex tasks, as well as insufficient continuous oversight during execution, rendering them unresponsive to environmental changes and prone to deviations. To tackle these challenges, we introduce HiPlan, a hierarchical planning framework that provides adaptive global-local guidance to boost LLM-based agents'decision-making. HiPlan decomposes complex tasks into milestone action guides for general direction and step-wise hints for detailed actions. During the offline phase, we construct a milestone library from expert demonstrations, enabling structured experience reuse by retrieving semantically similar tasks and milestones. In the execution phase, trajectory segments from past milestones are dynamically adapted to generate step-wise hints that align current observations with the milestone objectives, bridging gaps and correcting deviations. Extensive experiments across two challenging benchmarks demonstrate that HiPlan substantially outperforms strong baselines, and ablation studies validate the complementary benefits of its hierarchical components.