 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-REX: Benchmarking Exploratory Visual Reasoning via Chain-of-Questions
Dec 12, 2025While many vision-language models (VLMs) are developed to answer well-defined, straightforward questions with highly specified targets, as in most benchmarks, they often struggle in practice with complex open-ended tasks, which usually require multiple rounds of exploration and reasoning in the visual space. Such visual thinking paths not only provide step-by-step exploration and verification as an AI detective but also produce better interpretations of the final answers. However, these paths are challenging to evaluate due to the large exploration space of intermediate steps. To bridge the gap, we develop an evaluation suite, ``Visual Reasoning with multi-step EXploration (V-REX)'', which is composed of a benchmark of challenging visual reasoning tasks requiring native multi-step exploration and an evaluation protocol. V-REX covers rich application scenarios across diverse domains. V-REX casts the multi-step exploratory reasoning into a Chain-of-Questions (CoQ) and disentangles VLMs' capability to (1) Planning: breaking down an open-ended task by selecting a chain of exploratory questions; and (2) Following: answering curated CoQ sequentially to collect information for deriving the final answer. By curating finite options of questions and answers per step, V-REX achieves a reliable quantitative and fine-grained analysis of the intermediate steps. By assessing SOTA proprietary and open-sourced VLMs, we reveal consistent scaling trends, significant differences between planning and following abilities, and substantial room for improvement in multi-step exploratory reasoning.
Where to show Demos in Your Prompt: A Positional Bias of In-Context Learning
Jul 30, 2025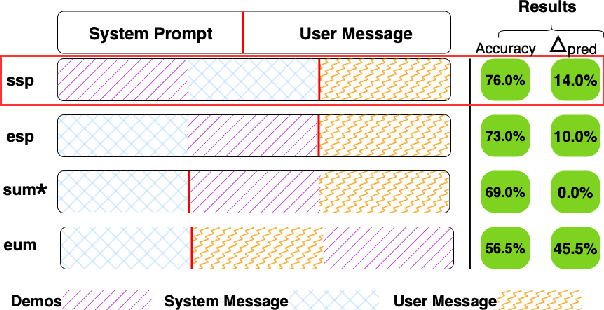

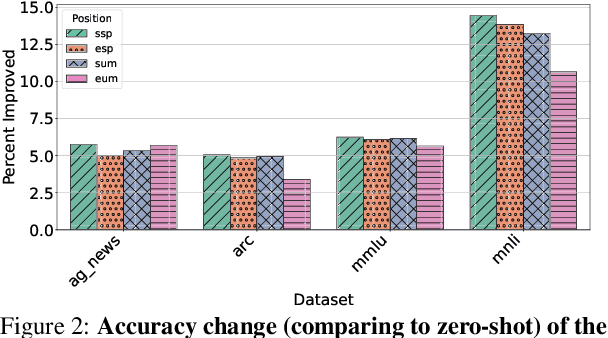

In-context learning (ICL) is a critical emerging capability of large language models (LLMs), enabling few-shot learning during inference by including a few demonstrations (demos) in the prompt. However, it has been found that ICL's performance can be sensitive to the choices of demos and their order. This paper investigates an unexplored new positional bias of ICL for the first time: we observe that the predictions and accuracy can drift drastically when the positions of demos, the system prompt, and the user message in LLM input are varied. We refer to this bias as DEMOS' POSITION IN PROMPT (DPP) bias. We design a systematic evaluation pipeline to study this type of positional bias across classification, question answering, summarization, and reasoning tasks. We introduce two metrics, ACCURACY-CHANGE and PREDICTION-CHANGE, to quantify net gains and output volatility induced by changes in the demos' position. Extensive experiments on ten LLMs from four open-source model families (QWEN, LLAMA3, MISTRAL, COHERE) verify that the bias significantly affects their accuracy and predictions: placing demos at the start of the prompt yields the most stable and accurate outputs with gains of up to +6 points. In contrast, placing demos at the end of the user message flips over 30\% of predictions without improving correctness on QA tasks. Smaller models are most affected by this sensitivity, though even large models remain marginally affected on complex tasks.
ColorBench: Can VLMs See and Understand the Colorful World? A Comprehensive Benchmark for Color Perception, Reasoning, and Robustness
Apr 10, 2025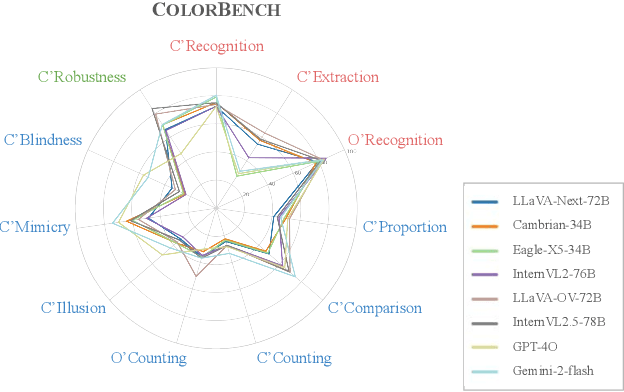
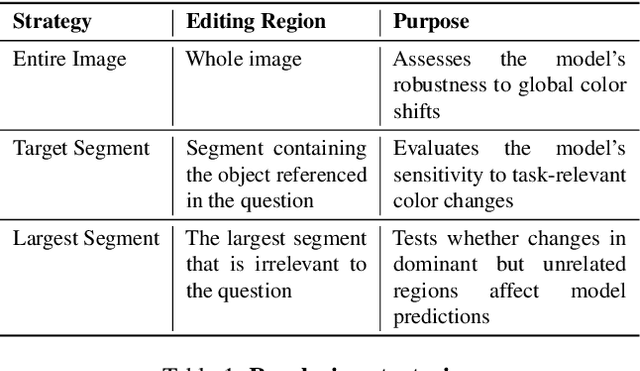
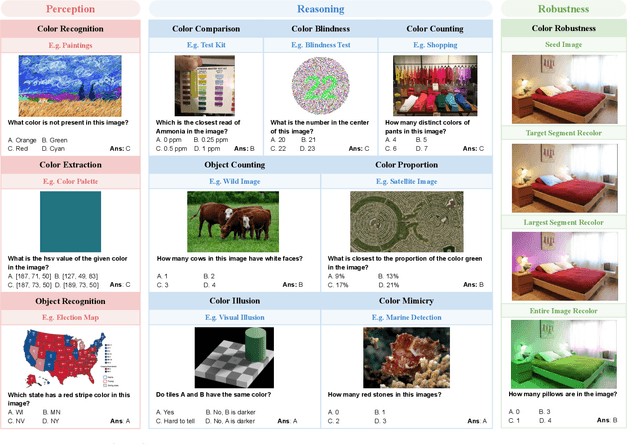
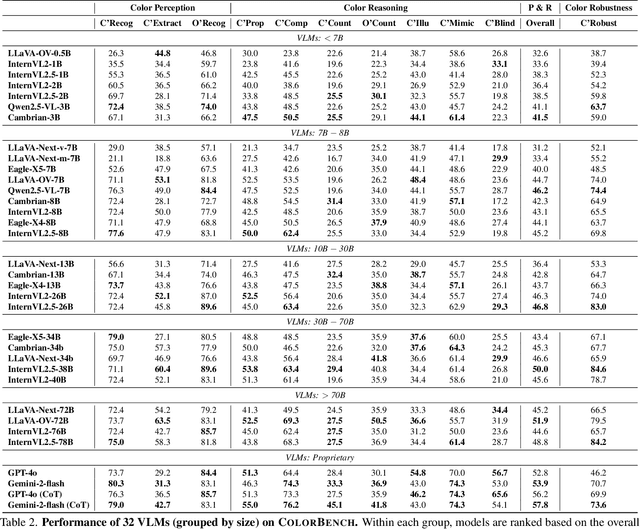
Color plays an important role in human perception and usually provides critical clues in visual reasoning. However, it is unclear whether and how vision-language models (VLMs) can perceive, understand, and leverage color as humans. This paper introduces ColorBench, an innovative benchmark meticulously crafted to assess the capabilities of VLMs in color understanding, including color perception, reasoning, and robustness. By curating a suite of diverse test scenarios, with grounding in real applications, ColorBench evaluates how these models perceive colors, infer meanings from color-based cues, and maintain consistent performance under varying color transformations. Through an extensive evaluation of 32 VLMs with varying language models and vision encoders, our paper reveals some undiscovered findings: (i) The scaling law (larger models are better) still holds on ColorBench, while the language model plays a more important role than the vision encoder. (ii) However, the performance gaps across models are relatively small, indicating that color understanding has been largely neglected by existing VLMs. (iii) CoT reasoning improves color understanding accuracies and robustness, though they are vision-centric tasks. (iv) Color clues are indeed leveraged by VLMs on ColorBench but they can also mislead models in some tasks. These findings highlight the critical limitations of current VLMs and underscore the need to enhance color comprehension. Our ColorBenchcan serve as a foundational tool for advancing the study of human-level color understanding of multimodal AI.
My LLM might Mimic AAE -- But When Should it?
Feb 06, 2025
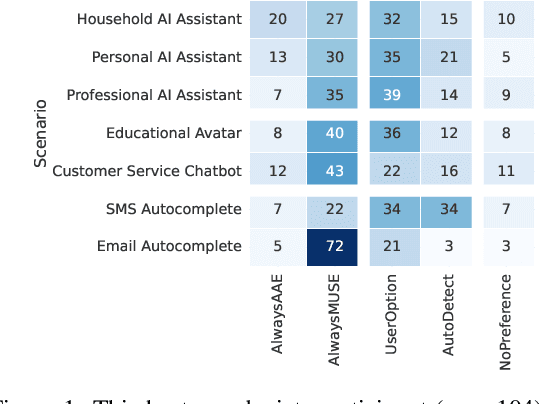


We examine the representation of African American English (AAE) in large language models (LLMs), exploring (a) the perceptions Black Americans have of how effective these technologies are at producing authentic AAE, and (b) in what contexts Black Americans find this desirable. Through both a survey of Black Americans ($n=$ 104) and annotation of LLM-produced AAE by Black Americans ($n=$ 228), we find that Black Americans favor choice and autonomy in determining when AAE is appropriate in LLM output. They tend to prefer that LLMs default to communicating in Mainstream U.S. English in formal settings, with greater interest in AAE production in less formal settings. When LLMs were appropriately prompted and provided in context examples, our participants found their outputs to have a level of AAE authenticity on par with transcripts of Black American speech. Select code and data for our project can be found here: https://github.com/smelliecat/AAEMime.git