 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Evolving Visual Questioner
Jun 11, 2026Vision-language models (VLMs) are typically trained as passive answerers, while their ability to actively ask diverse, non-trivial, visual-centric and grounded questions remains underexplored. Existing visual questioners' performance is bottlenecked by the availability of high-quality training data or the cost of curating them. We show that a VLM can continuously improve itself as a visual questioner without any external supervision. We propose a self-evolving framework that uses a VLM itself as both a proposer and a filter to produce harder, more informative, and visual-centric questions, while maintaining their exploration diversity to avoid training collapse. These questions are then used to train the VLM in both questioner and answerer modes. To evaluate the questioner, we introduce an agentic protocol that assesses questions along perception, reasoning, and diversity dimensions. Experiments across various backbone VLMs show that our method substantially enhances the quality and substantially expands the difficulty boundary of autonomous question generation. Under the same budget, our self-supervision is more effective than training on the static source data. Moreover, the self-evolving questioner remains a competitive or even better answerer.
Do Synthetic Trajectories Reflect Real Reward Hacking? A Systematic Study on Monitoring In-the-Wild Hacking in Code Generation
Apr 26, 2026Reward hacking in code generation, where models exploit evaluation loopholes to obtain full reward without correctly solving the tasks, poses a critical challenge for Reinforcement Learning (RL) and the deployment of reasoning models. Existing studies have been conducted primarily on synthetic hacking trajectories. However, whether these synthetic behaviors faithfully represent naturally emerging hacking in the wild remains unclear. In this work, we present a systematic analysis of the synthetic vs. in-the-wild discrepancy in reward hacking. We examine to what extent hacking behaviors induced by prompting resemble those emerging during RL training, and whether monitors trained on synthetic trajectories generalize to naturally arising but previously unseen hacking. To scale up the curation of in-the-wild reward hacking trajectories, we modified Group Relative Policy Optimization (GRPO) by injecting conflicting unit tests as tracers and applying a "resampling-until-hack" mechanism. Through controlled comparisons between monitors trained on synthetic versus in-the-wild data, we find that (1) synthetic-data-trained monitors fail to generalize to "in-the-wild" hacking, and (2) monitors trained on our "in-the-wild" trajectories demonstrate stronger generalizability to unseen hacking types. Our results indicate that synthetic reward hacking data may not fully reflect natural reward hacking behaviors, and that relying solely on synthetic data can lead to misleading conclusions. The codebase is available at https://github.com/LichenLillc/CoTMonitoring.git
V-REX: Benchmarking Exploratory Visual Reasoning via Chain-of-Questions
Dec 12, 2025While many vision-language models (VLMs) are developed to answer well-defined, straightforward questions with highly specified targets, as in most benchmarks, they often struggle in practice with complex open-ended tasks, which usually require multiple rounds of exploration and reasoning in the visual space. Such visual thinking paths not only provide step-by-step exploration and verification as an AI detective but also produce better interpretations of the final answers. However, these paths are challenging to evaluate due to the large exploration space of intermediate steps. To bridge the gap, we develop an evaluation suite, ``Visual Reasoning with multi-step EXploration (V-REX)'', which is composed of a benchmark of challenging visual reasoning tasks requiring native multi-step exploration and an evaluation protocol. V-REX covers rich application scenarios across diverse domains. V-REX casts the multi-step exploratory reasoning into a Chain-of-Questions (CoQ) and disentangles VLMs' capability to (1) Planning: breaking down an open-ended task by selecting a chain of exploratory questions; and (2) Following: answering curated CoQ sequentially to collect information for deriving the final answer. By curating finite options of questions and answers per step, V-REX achieves a reliable quantitative and fine-grained analysis of the intermediate steps. By assessing SOTA proprietary and open-sourced VLMs, we reveal consistent scaling trends, significant differences between planning and following abilities, and substantial room for improvement in multi-step exploratory reasoning.
ColorBench: Can VLMs See and Understand the Colorful World? A Comprehensive Benchmark for Color Perception, Reasoning, and Robustness
Apr 10, 2025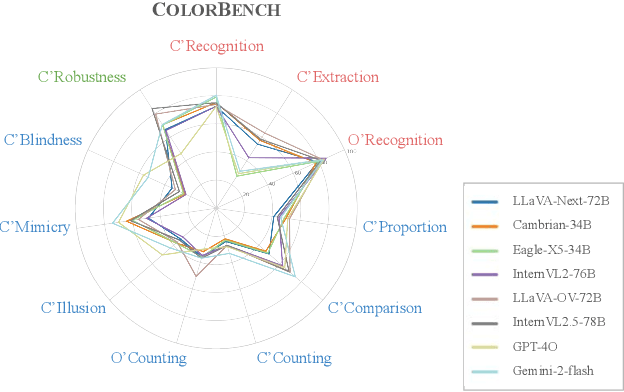
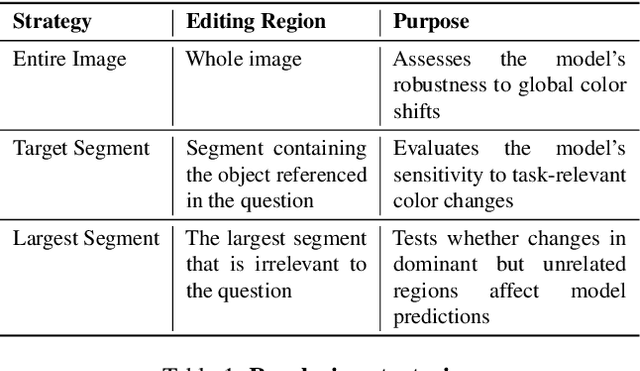
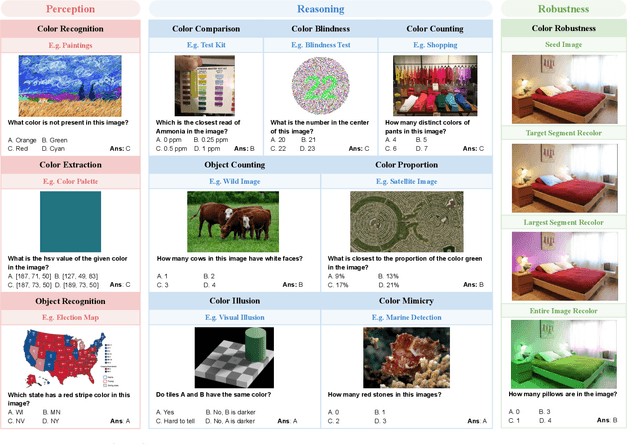
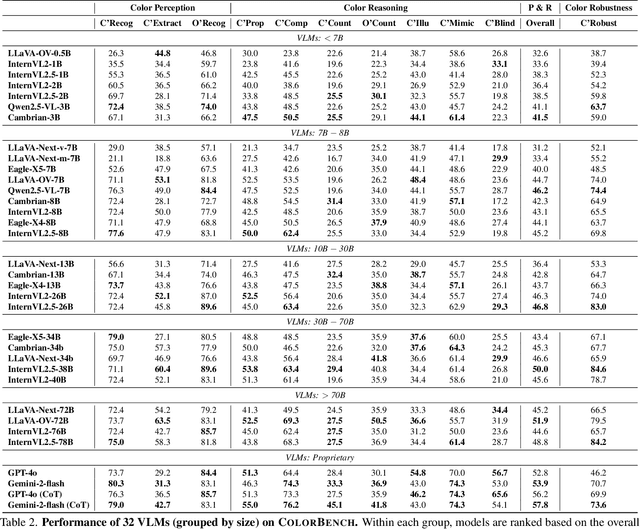
Color plays an important role in human perception and usually provides critical clues in visual reasoning. However, it is unclear whether and how vision-language models (VLMs) can perceive, understand, and leverage color as humans. This paper introduces ColorBench, an innovative benchmark meticulously crafted to assess the capabilities of VLMs in color understanding, including color perception, reasoning, and robustness. By curating a suite of diverse test scenarios, with grounding in real applications, ColorBench evaluates how these models perceive colors, infer meanings from color-based cues, and maintain consistent performance under varying color transformations. Through an extensive evaluation of 32 VLMs with varying language models and vision encoders, our paper reveals some undiscovered findings: (i) The scaling law (larger models are better) still holds on ColorBench, while the language model plays a more important role than the vision encoder. (ii) However, the performance gaps across models are relatively small, indicating that color understanding has been largely neglected by existing VLMs. (iii) CoT reasoning improves color understanding accuracies and robustness, though they are vision-centric tasks. (iv) Color clues are indeed leveraged by VLMs on ColorBench but they can also mislead models in some tasks. These findings highlight the critical limitations of current VLMs and underscore the need to enhance color comprehension. Our ColorBenchcan serve as a foundational tool for advancing the study of human-level color understanding of multimodal AI.
Diffusion Curriculum: Synthetic-to-Real Generative Curriculum Learning via Image-Guided Diffusion
Oct 17, 2024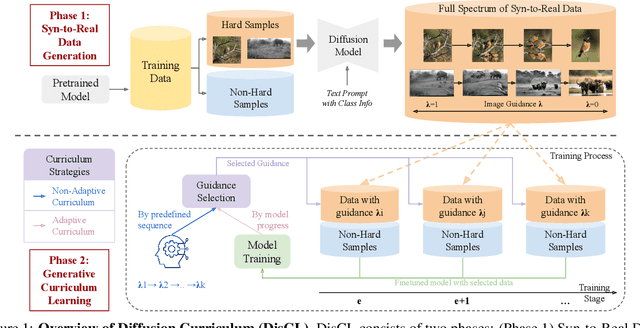
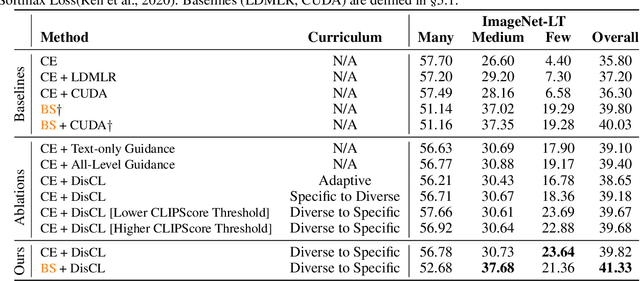

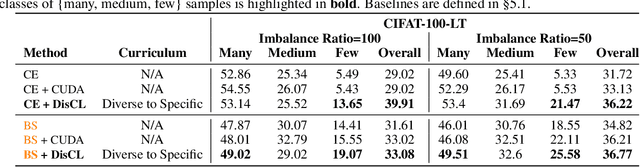
Low-quality or scarce data has posed significant challenges for training deep neural networks in practice. While classical data augmentation cannot contribute very different new data, diffusion models opens up a new door to build self-evolving AI by generating high-quality and diverse synthetic data through text-guided prompts. However, text-only guidance cannot control synthetic images' proximity to the original images, resulting in out-of-distribution data detrimental to the model performance. To overcome the limitation, we study image guidance to achieve a spectrum of interpolations between synthetic and real images. With stronger image guidance, the generated images are similar to the training data but hard to learn. While with weaker image guidance, the synthetic images will be easier for model but contribute to a larger distribution gap with the original data. The generated full spectrum of data enables us to build a novel "Diffusion Curriculum (DisCL)". DisCL adjusts the image guidance level of image synthesis for each training stage: It identifies and focuses on hard samples for the model and assesses the most effective guidance level of synthetic images to improve hard data learning. We apply DisCL to two challenging tasks: long-tail (LT) classification and learning from low-quality data. It focuses on lower-guidance images of high-quality to learn prototypical features as a warm-up of learning higher-guidance images that might be weak on diversity or quality. Extensive experiments showcase a gain of 2.7% and 2.1% in OOD and ID macro-accuracy when applying DisCL to iWildCam dataset. On ImageNet-LT, DisCL improves the base model's tail-class accuracy from 4.4% to 23.64% and leads to a 4.02% improvement in all-class accuracy.
Mosaic IT: Enhancing Instruction Tuning with Data Mosaics
May 22, 2024Finetuning large language models with a variety of instruction-response pairs has enhanced their capability to understand and follow instructions. Current instruction tuning primarily relies on teacher models or human intervention to generate and refine the instructions and responses, which are costly, non-sustainable, and may lack diversity. In this paper, we introduce Mosaic Instruction Tuning (Mosaic-IT), a human/model-free method that can efficiently create rich and diverse augmentations from existing instruction tuning data to enhance the finetuned LLM.Mosaic-IT randomly concatenates multiple instruction data into one and trains the model to produce the corresponding responses with predefined higher-level meta-instructions to strengthen its multi-step instruction-following and format-following skills. Our extensive evaluations demonstrate a superior performance and training efficiency of Mosaic-IT, which achieves consistent performance improvements over various benchmarks and an 80% reduction in training costs compared with original instruction tuning. Our codes and data are available at https://github.com/tianyi-lab/Mosaic-IT.
PANDA (Pedantic ANswer-correctness Determination and Adjudication):Improving Automatic Evaluation for Question Answering and Text Generation
Feb 17, 2024



Question answering (QA) can only make progress if we know if an answer is correct, but for many of the most challenging and interesting QA examples, current answer correctness (AC) metrics do not align with human judgments, particularly verbose, free form answers from large language models (LLM). There are two challenges: a lack of data and that models are too big. LLM based scorers correlate better with humans, but this expensive task has only been tested on limited QA datasets. We rectify these issues by providing clear guidelines for evaluating machine QA adopted from human QA contests. We also introduce Precise ANswer correctness Determination and Adjudication (PANDA), a small, efficient, deterministic AC classifier (812 KB) that more accurately evaluates answer correctness.
CFMatch: Aligning Automated Answer Equivalence Evaluation with Expert Judgments For Open-Domain Question Answering
Jan 24, 2024

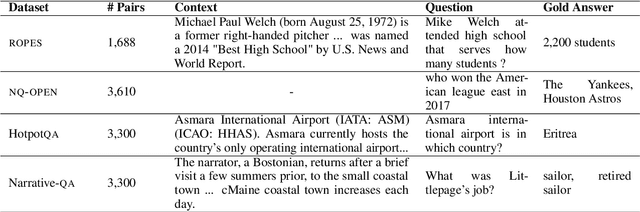

Question answering (QA) can only make progress if we know if an answer is correct, but for many of the most challenging and interesting QA examples, current evaluation metrics to determine answer equivalence (AE) often do not align with human judgments, particularly more verbose, free-form answers from large language models (LLM). There are two challenges: a lack of data and that models are too big: LLM-based scorers can correlate better with human judges, but this task has only been tested on limited QA datasets, and even when available, update of the model is limited because LLMs are large and often expensive. We rectify both of these issues by providing clear and consistent guidelines for evaluating AE in machine QA adopted from professional human QA contests. We also introduce a combination of standard evaluation and a more efficient, robust, and lightweight discriminate AE classifier-based matching method (CFMatch, smaller than 1 MB), trained and validated to more accurately evaluate answer correctness in accordance with adopted expert AE rules that are more aligned with human judgments.