 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models Don't Know What You Want: Evaluating Personalization in Deep Research Needs Real Users
Mar 17, 2026Deep Research (DR) tools (e.g. OpenAI DR) help researchers cope with ballooning publishing counts. Such tools can synthesize scientific papers to answer researchers' queries, but lack understanding of their users. We change that in MyScholarQA (MySQA), a personalized DR tool that: 1) infers a profile of a user's research interests; 2) proposes personalized actions for a user's input query; and 3) writes a multi-section report for the query that follows user-approved actions. We first test MySQA with NLP's standard protocol: we design a benchmark of synthetic users and LLM judges, where MySQA beats baselines in citation metrics and personalized action-following. However, we suspect this process does not cover all aspects of personalized DR users value, so we interview users in an online version of MySQA to unmask them. We reveal nine nuanced errors of personalized DR undetectable by our LLM judges, and we study qualitative feedback to form lessons for future DR design. In all, we argue for a pillar of personalization that easy-to-use LLM judges can lead NLP to overlook: real progress in personalization is only possible with real users.
BenchMarker: An Education-Inspired Toolkit for Highlighting Flaws in Multiple-Choice Benchmarks
Feb 05, 2026Multiple-choice question answering (MCQA) is standard in NLP, but benchmarks lack rigorous quality control. We present BenchMarker, an education-inspired toolkit using LLM judges to flag three common MCQ flaws: 1) contamination - items appearing exactly online; 2) shortcuts - cues in the choices that enable guessing; and 3) writing errors - structural/grammatical issues based on a 19-rule education rubric. We validate BenchMarker with human annotations, then run the tool to audit 12 benchmarks, revealing: 2) contaminated MCQs tend to inflate accuracy, while writing errors tend to lower it and change rankings beyond random; and 3) prior benchmark repairs address their targeted issues (i.e., lowering accuracy with LLM-written distractors), but inadvertently add new flaws (i.e. implausible distractors, many correct answers). Overall, flaws in MCQs degrade NLP evaluation, but education research offers a path forward. We release BenchMarker to bridge the fields and improve MCQA benchmark design.
Semantically-Aware Rewards for Open-Ended R1 Training in Free-Form Generation
Jun 18, 2025Evaluating open-ended long-form generation is challenging because it is hard to define what clearly separates good from bad outputs. Existing methods often miss key aspects like coherence, style, or relevance, or are biased by pretraining data, making open-ended long-form evaluation an underexplored problem. To address this gap, we propose PrefBERT, a scoring model for evaluating open-ended long-form generation in GRPO and guiding its training with distinct rewards for good and bad outputs. Trained on two response evaluation datasets with diverse long-form styles and Likert-rated quality, PrefBERT effectively supports GRPO by offering better semantic reward feedback than traditional metrics ROUGE-L and BERTScore do. Through comprehensive evaluations, including LLM-as-a-judge, human ratings, and qualitative analysis, we show that PrefBERT, trained on multi-sentence and paragraph-length responses, remains reliable across varied long passages and aligns well with the verifiable rewards GRPO needs. Human evaluations confirm that using PrefBERT as the reward signal to train policy models yields responses better aligned with human preferences than those trained with traditional metrics. Our code is available at https://github.com/zli12321/long_form_rl.
VideoHallu: Evaluating and Mitigating Multi-modal Hallucinations for Synthetic Videos
May 02, 2025Synthetic video generation with foundation models has gained attention for its realism and wide applications. While these models produce high-quality frames, they often fail to respect common sense and physical laws, resulting in abnormal content. Existing metrics like VideoScore emphasize general quality but ignore such violations and lack interpretability. A more insightful approach is using multi-modal large language models (MLLMs) as interpretable evaluators, as seen in FactScore. Yet, MLLMs' ability to detect abnormalities in synthetic videos remains underexplored. To address this, we introduce VideoHallu, a benchmark featuring synthetic videos from models like Veo2, Sora, and Kling, paired with expert-designed QA tasks solvable via human-level reasoning across various categories. We assess several SoTA MLLMs, including GPT-4o, Gemini-2.5-Pro, Qwen-2.5-VL, and newer models like Video-R1 and VideoChat-R1. Despite strong real-world performance on MVBench and MovieChat, these models still hallucinate on basic commonsense and physics tasks in synthetic settings, underscoring the challenge of hallucination. We further fine-tune SoTA MLLMs using Group Relative Policy Optimization (GRPO) on real and synthetic commonsense/physics data. Results show notable accuracy gains, especially with counterexample integration, advancing MLLMs' reasoning capabilities. Our data is available at https://github.com/zli12321/VideoHallu.
Large Language Models Are Effective Human Annotation Assistants, But Not Good Independent Annotators
Mar 09, 2025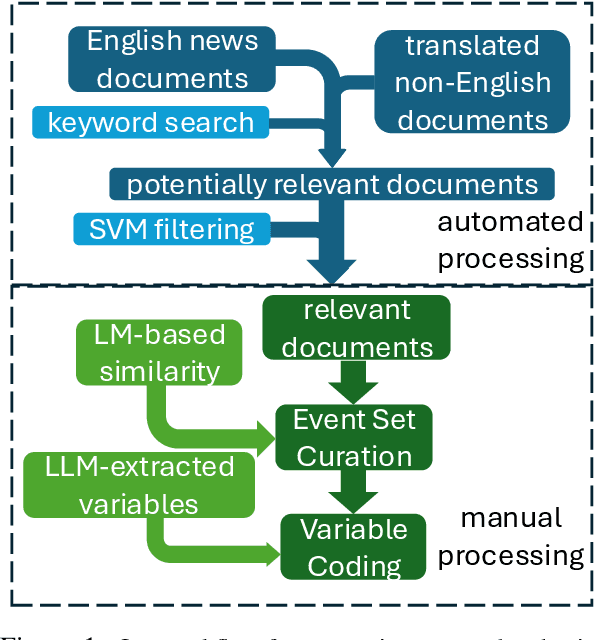
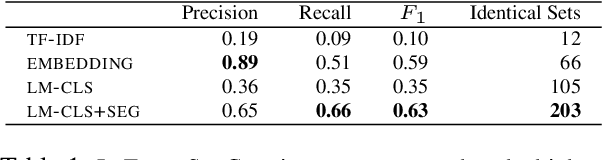

Event annotation is important for identifying market changes, monitoring breaking news, and understanding sociological trends. Although expert annotators set the gold standards, human coding is expensive and inefficient. Unlike information extraction experiments that focus on single contexts, we evaluate a holistic workflow that removes irrelevant documents, merges documents about the same event, and annotates the events. Although LLM-based automated annotations are better than traditional TF-IDF-based methods or Event Set Curation, they are still not reliable annotators compared to human experts. However, adding LLMs to assist experts for Event Set Curation can reduce the time and mental effort required for Variable Annotation. When using LLMs to extract event variables to assist expert annotators, they agree more with the extracted variables than fully automated LLMs for annotation.
GRACE: A Granular Benchmark for Evaluating Model Calibration against Human Calibration
Feb 27, 2025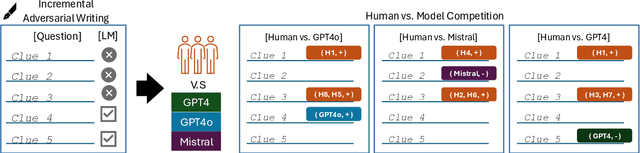
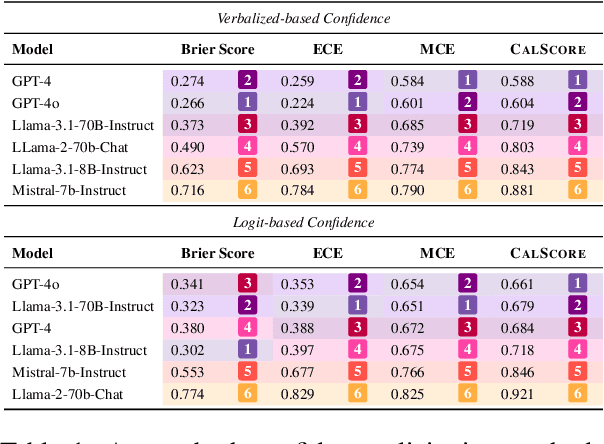
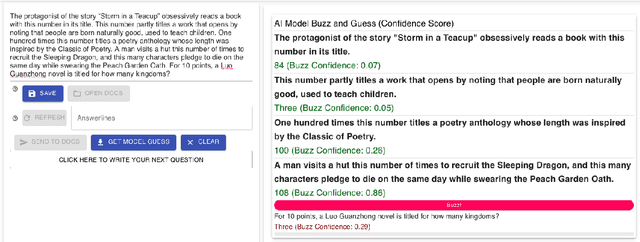
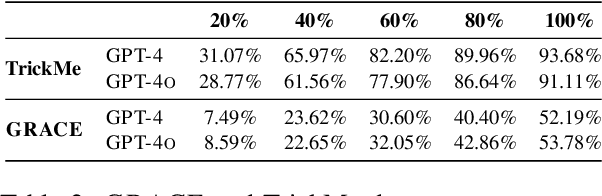
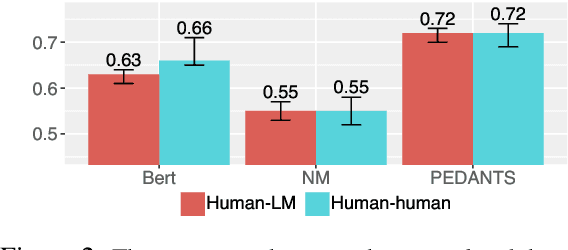
Language models are often miscalibrated, leading to confidently incorrect answers. We introduce GRACE, a benchmark for language model calibration that incorporates comparison with human calibration. GRACE consists of question-answer pairs, in which each question contains a series of clues that gradually become easier, all leading to the same answer; models must answer correctly as early as possible as the clues are revealed. This setting permits granular measurement of model calibration based on how early, accurately, and confidently a model answers. After collecting these questions, we host live human vs. model competitions to gather 1,749 data points on human and model teams' timing, accuracy, and confidence. We propose a metric, CalScore, that uses GRACE to analyze model calibration errors and identify types of model miscalibration that differ from human behavior. We find that although humans are less accurate than models, humans are generally better calibrated. Since state-of-the-art models struggle on GRACE, it effectively evaluates progress on improving model calibration.
Which of These Best Describes Multiple Choice Evaluation with LLMs? A) Forced B) Flawed C) Fixable D) All of the Above
Feb 19, 2025



Multiple choice question answering (MCQA) is popular for LLM evaluation due to its simplicity and human-like testing, but we argue for its reform. We first reveal flaws in MCQA's format, as it struggles to: 1) test generation/subjectivity; 2) match LLM use cases; and 3) fully test knowledge. We instead advocate for generative formats based on human testing-where LLMs construct and explain answers-better capturing user needs and knowledge while remaining easy to score. We then show even when MCQA is a useful format, its datasets suffer from: leakage; unanswerability; shortcuts; and saturation. In each issue, we give fixes from education, like rubrics to guide MCQ writing; scoring methods to bridle guessing; and Item Response Theory to build harder MCQs. Lastly, we discuss LLM errors in MCQA-robustness, biases, and unfaithful explanations-showing how our prior solutions better measure or address these issues. While we do not need to desert MCQA, we encourage more efforts in refining the task based on educational testing, advancing evaluations.
Should I Trust You? Detecting Deception in Negotiations using Counterfactual RL
Feb 18, 2025An increasingly prevalent socio-technical problem is people being taken in by offers that sound ``too good to be true'', where persuasion and trust shape decision-making. This paper investigates how \abr{ai} can help detect these deceptive scenarios. We analyze how humans strategically deceive each other in \textit{Diplomacy}, a board game that requires both natural language communication and strategic reasoning. This requires extracting logical forms of proposed agreements in player communications and computing the relative rewards of the proposal using agents' value functions. Combined with text-based features, this can improve our deception detection. Our method detects human deception with a high precision when compared to a Large Language Model approach that flags many true messages as deceptive. Future human-\abr{ai} interaction tools can build on our methods for deception detection by triggering \textit{friction} to give users a chance of interrogating suspicious proposals.
Whose Boat Does it Float? Improving Personalization in Preference Tuning via Inferred User Personas
Jan 20, 2025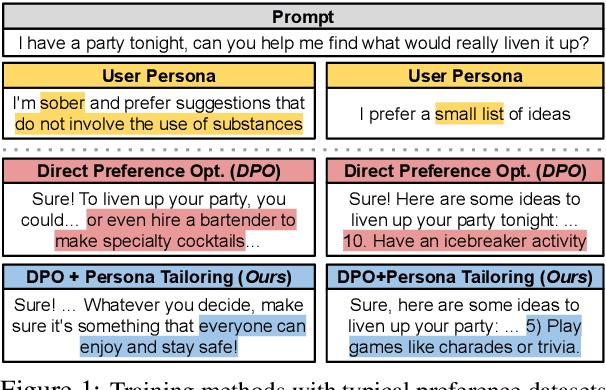

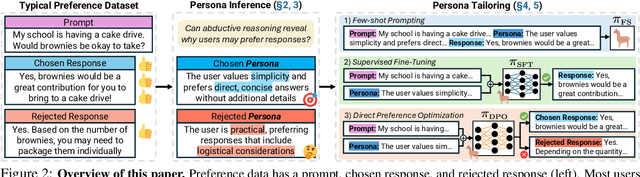
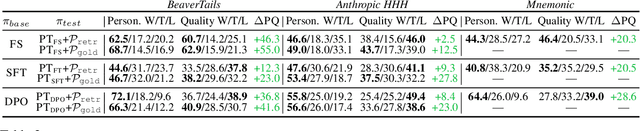
LLMs are tuned to follow instructions (aligned) by learning which of two outputs users prefer for a prompt. However, this preference data format does not convey why users prefer responses that are chosen or rejected, so LLMs trained on these datasets cannot tailor responses to varied user needs. To surface these parameters of personalization, we apply abductive reasoning to preference data, inferring needs and interests of users, i.e. personas, that may prefer each output. We test this idea in two steps: Persona Inference (PI)-abductively inferring personas of users who prefer chosen or rejected outputs-and Persona Tailoring (PT)-training models to tailor responses to personas from PI. We find: 1) LLMs infer personas accurately explaining why different users may prefer both chosen or rejected outputs; 2) Training on preference data augmented with PI personas via PT boosts personalization, enabling models to support user-written personas; and 3) Rejected response personas form harder personalization evaluations, showing PT better aids users with uncommon preferences versus typical alignment methods. We argue for an abductive view of preferences for personalization, asking not only which response is better but when, why, and for whom.
Personalized Help for Optimizing Low-Skilled Users' Strategy
Nov 14, 2024AIs can beat humans in game environments; however, how helpful those agents are to human remains understudied. We augment CICERO, a natural language agent that demonstrates superhuman performance in Diplomacy, to generate both move and message advice based on player intentions. A dozen Diplomacy games with novice and experienced players, with varying advice settings, show that some of the generated advice is beneficial. It helps novices compete with experienced players and in some instances even surpass them. The mere presence of advice can be advantageous, even if players do not follow it.