 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Are Effective Human Annotation Assistants, But Not Good Independent Annotators
Mar 09, 2025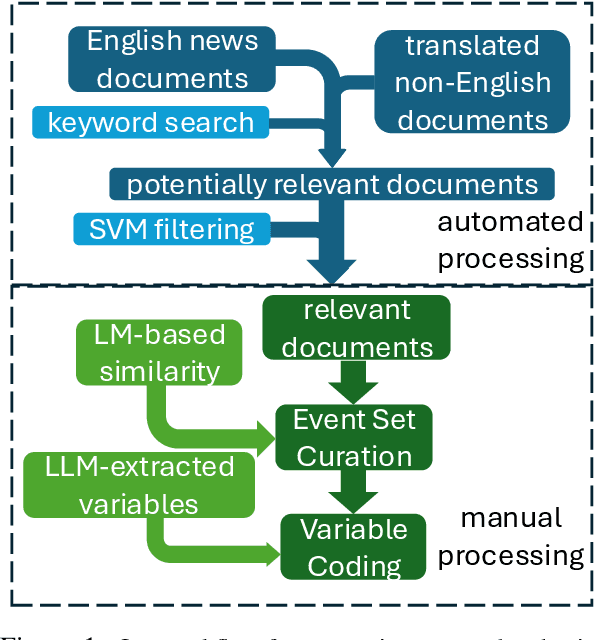
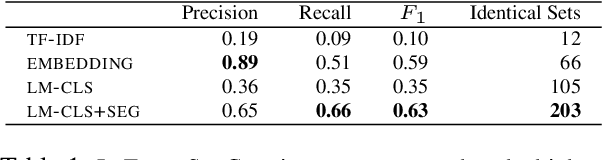

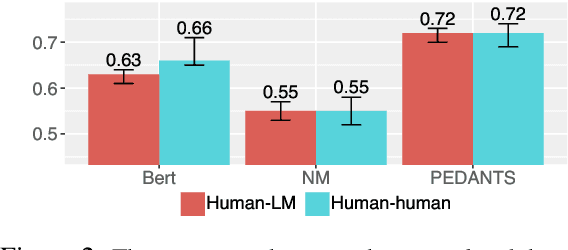
Event annotation is important for identifying market changes, monitoring breaking news, and understanding sociological trends. Although expert annotators set the gold standards, human coding is expensive and inefficient. Unlike information extraction experiments that focus on single contexts, we evaluate a holistic workflow that removes irrelevant documents, merges documents about the same event, and annotates the events. Although LLM-based automated annotations are better than traditional TF-IDF-based methods or Event Set Curation, they are still not reliable annotators compared to human experts. However, adding LLMs to assist experts for Event Set Curation can reduce the time and mental effort required for Variable Annotation. When using LLMs to extract event variables to assist expert annotators, they agree more with the extracted variables than fully automated LLMs for annotation.
Accelerating Online Reinforcement Learning via Supervisory Safety Systems
Sep 22, 2022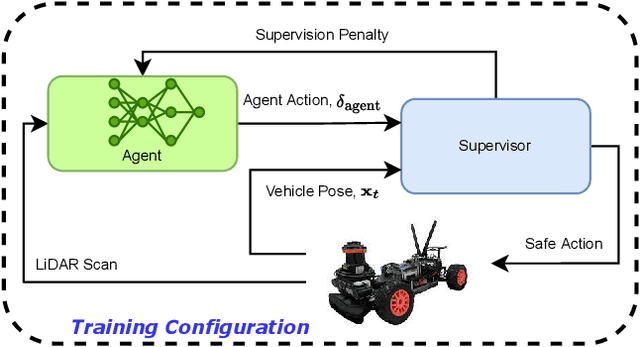
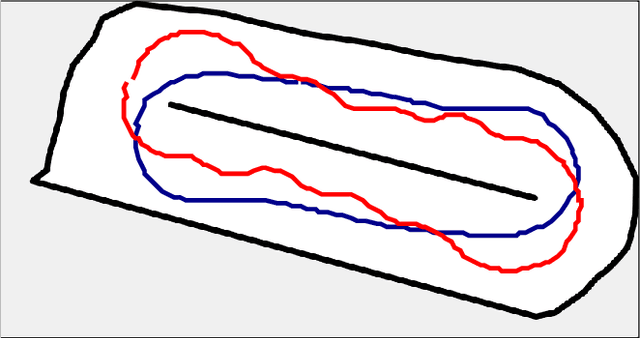
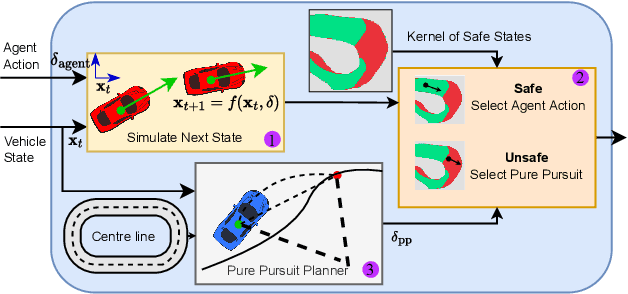
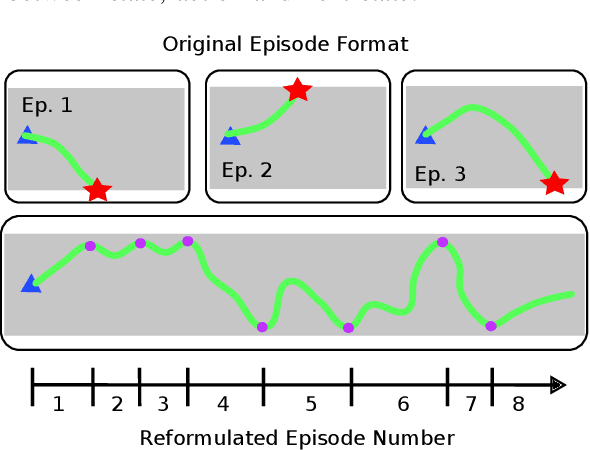
Deep reinforcement learning (DRL) is a promising method to learn control policies for robots only from demonstration and experience. To cover the whole dynamic behaviour of the robot, the DRL training is an active exploration process typically derived in simulation environments. Although this simulation training is cheap and fast, applying DRL algorithms to real-world settings is difficult. If agents are trained until they perform safely in simulation, transferring them to physical systems is difficult due to the sim-to-real gap caused by the difference between the simulation dynamics and the physical robot. In this paper, we present a method of online training a DRL agent to drive autonomously on a physical vehicle by using a model-based safety supervisor. Our solution uses a supervisory system to check if the action selected by the agent is safe or unsafe and ensure that a safe action is always implemented on the vehicle. With this, we can bypass the sim-to-real problem while training the DRL algorithm safely, quickly, and efficiently. We provide a variety of real-world experiments where we train online a small-scale, physical vehicle to drive autonomously with no prior simulation training. The evaluation results show that our method trains agents with improved sample efficiency while never crashing, and the trained agents demonstrate better driving performance than those trained in simulation.
From Navigation to Racing: Reward Signal Design for Autonomous Racing
Mar 18, 2021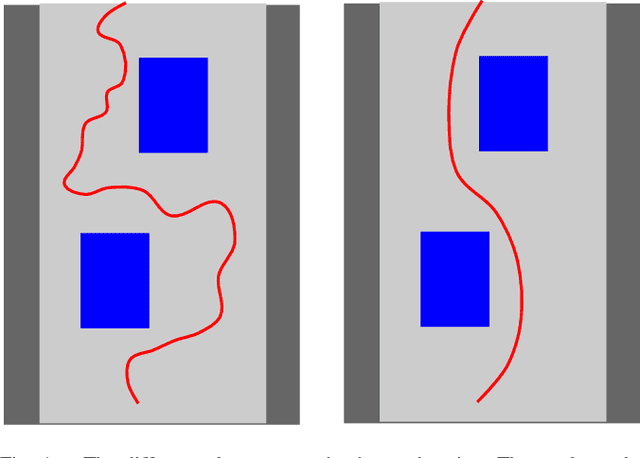
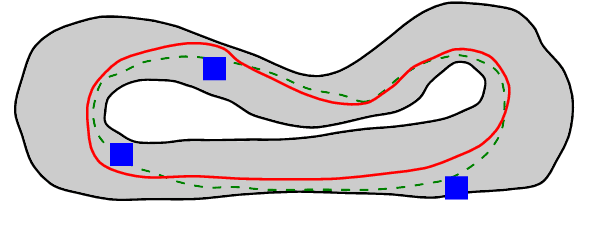
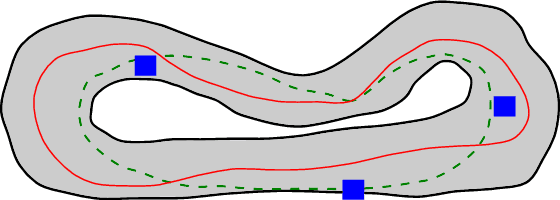
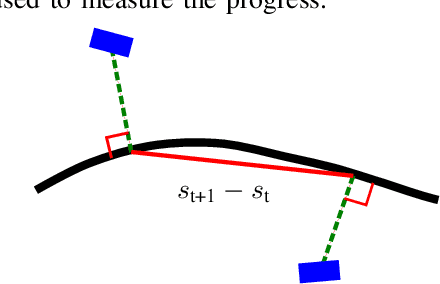
The problem of autonomous navigation is to generate a set of navigation references which when followed move the vehicle from a starting position to and end goal location while avoiding obstacles. Autonomous racing complicates the navigation problem by adding the objective of minimising the time to complete a track. Solutions aiming for a minimum time solution require that the planner is concerned with the optimality of the trajectory according to the vehicle dynamics. Neural networks, trained from experience with reinforcement learning, have shown to be effective local planners which generate navigation references to follow a global plan and avoid obstacles. We address the problem designing a reward signal which can be used to train neural network-based local planners to race in a time-efficient manner and avoid obstacles. The general challenge of reward signal design is to represent a desired behavior in an equation that can be calculated at each time step. The specific challenge of designing a reward signal for autonomous racing is to encode obstacle-free, time optimal racing trajectories in a clear signal We propose several methods of encoding ideal racing behavior based using a combination of the position and velocity of the vehicle and the actions taken by the network. The reward function candidates are expressed as equations and evaluated in the context of F1/10th autonomous racing. The results show that the best reward signal rewards velocity along, and punishes the lateral deviation from a precalculated, optimal reference trajectory.
Autonomous Obstacle Avoidance by Learning Policies for Reference Modification
Feb 22, 2021
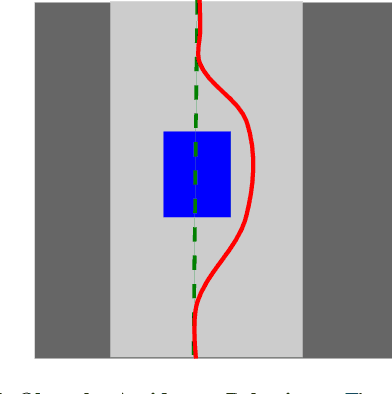
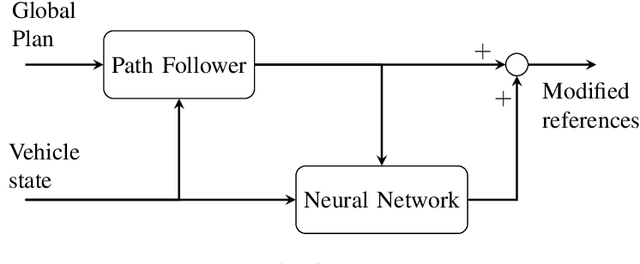

The key problem for autonomous robots is how to navigate through complex, obstacle filled environments. The navigation problem is broken up into generating a reference path to the goal and then using a local planner to track the reference path and avoid obstacles by generating velocity and steering references for a control system to execute. This paper presents a novel local planner architecture for path following and obstacle avoidance by proposing a hybrid system that uses a classic path following algorithm in parallel with a neural network. Our solution, called the modification architecture, uses a path following algorithm to follow a reference path and a neural network to modify the references generated by the path follower in order to prevent collisions. The neural network is trained using reinforcement learning to deviate from the reference trajectory just enough to avoid crashing. We present our local planner in a hierarchical planning framework, nested between a global reference planner and a low-level control system. The system is evaluated in the context of F1/10th scale autonomous racing in random forests and on a race track. The results demonstrate that our solution is able to follow a reference trajectory while avoiding obstacles using only 10 sparse laser range finder readings. Our hybrid system overcomes previous limitations by not requiring an obstacle map, human demonstrations, or an instrumented training setup.