 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Online Reinforcement Learning via Supervisory Safety Systems
Sep 22, 2022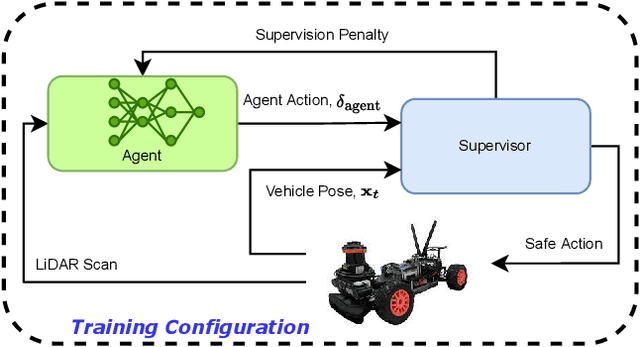
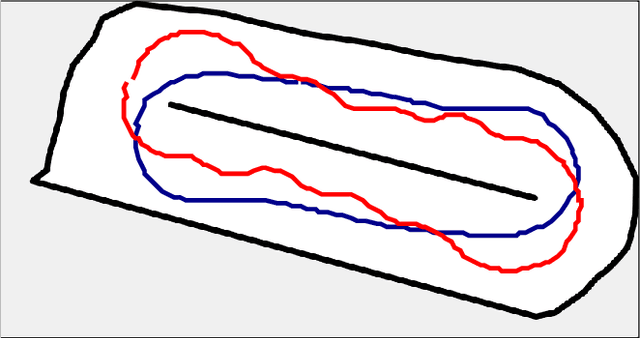
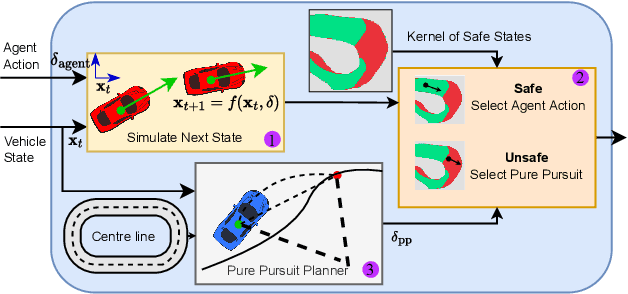
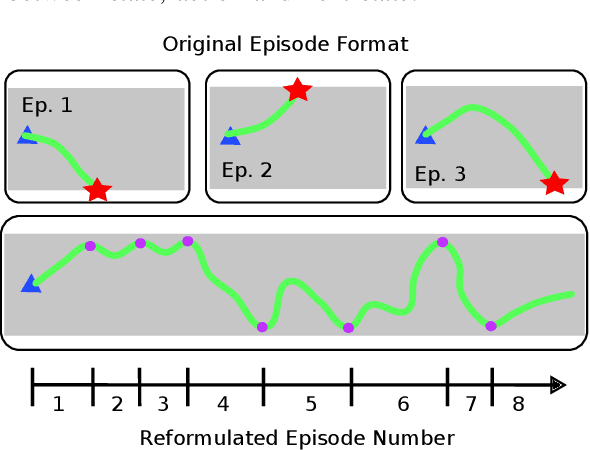
Deep reinforcement learning (DRL) is a promising method to learn control policies for robots only from demonstration and experience. To cover the whole dynamic behaviour of the robot, the DRL training is an active exploration process typically derived in simulation environments. Although this simulation training is cheap and fast, applying DRL algorithms to real-world settings is difficult. If agents are trained until they perform safely in simulation, transferring them to physical systems is difficult due to the sim-to-real gap caused by the difference between the simulation dynamics and the physical robot. In this paper, we present a method of online training a DRL agent to drive autonomously on a physical vehicle by using a model-based safety supervisor. Our solution uses a supervisory system to check if the action selected by the agent is safe or unsafe and ensure that a safe action is always implemented on the vehicle. With this, we can bypass the sim-to-real problem while training the DRL algorithm safely, quickly, and efficiently. We provide a variety of real-world experiments where we train online a small-scale, physical vehicle to drive autonomously with no prior simulation training. The evaluation results show that our method trains agents with improved sample efficiency while never crashing, and the trained agents demonstrate better driving performance than those trained in simulation.
Towards Learning to Speak and Hear Through Multi-Agent Communication over a Continuous Acoustic Channel
Nov 04, 2021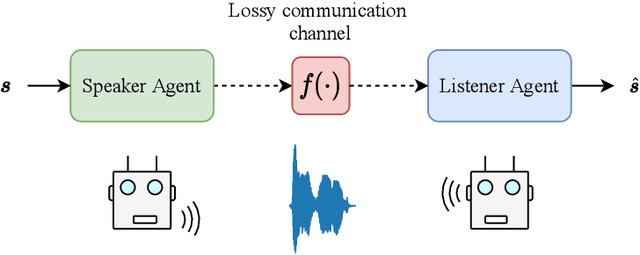

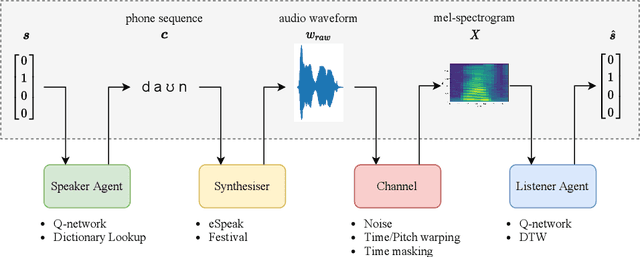
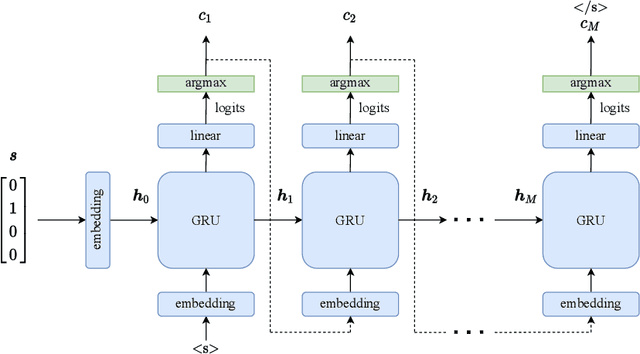
While multi-agent reinforcement learning has been used as an effective means to study emergent communication between agents, existing work has focused almost exclusively on communication with discrete symbols. Human communication often takes place (and emerged) over a continuous acoustic channel; human infants acquire language in large part through continuous signalling with their caregivers. We therefore ask: Are we able to observe emergent language between agents with a continuous communication channel trained through reinforcement learning? And if so, what is the impact of channel characteristics on the emerging language? We propose an environment and training methodology to serve as a means to carry out an initial exploration of these questions. We use a simple messaging environment where a "speaker" agent needs to convey a concept to a "listener". The Speaker is equipped with a vocoder that maps symbols to a continuous waveform, this is passed over a lossy continuous channel, and the Listener needs to map the continuous signal to the concept. Using deep Q-learning, we show that basic compositionality emerges in the learned language representations. We find that noise is essential in the communication channel when conveying unseen concept combinations. And we show that we can ground the emergent communication by introducing a caregiver predisposed to "hearing" or "speaking" English. Finally, we describe how our platform serves as a starting point for future work that uses a combination of deep reinforcement learning and multi-agent systems to study our questions of continuous signalling in language learning and emergence.
Toward Collaborative Reinforcement Learning Agents that Communicate Through Text-Based Natural Language
Jul 21, 2021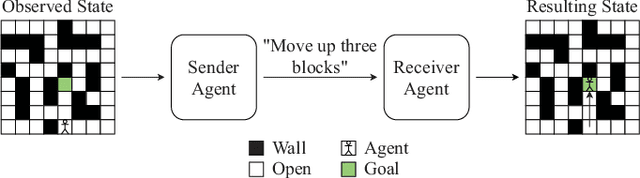
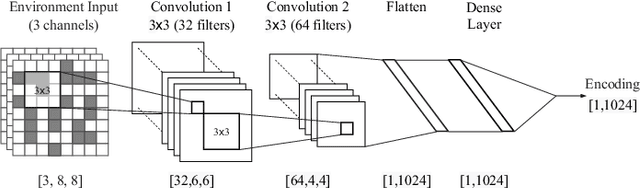
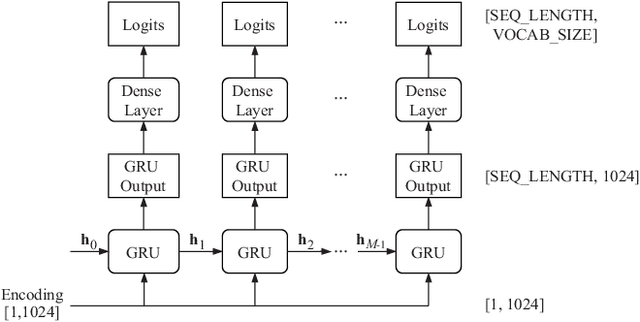

Communication between agents in collaborative multi-agent settings is in general implicit or a direct data stream. This paper considers text-based natural language as a novel form of communication between multiple agents trained with reinforcement learning. This could be considered first steps toward a truly autonomous communication without the need to define a limited set of instructions, and natural collaboration between humans and robots. Inspired by the game of Blind Leads, we propose an environment where one agent uses natural language instructions to guide another through a maze. We test the ability of reinforcement learning agents to effectively communicate through discrete word-level symbols and show that the agents are able to sufficiently communicate through natural language with a limited vocabulary. Although the communication is not always perfect English, the agents are still able to navigate the maze. We achieve a BLEU score of 0.85, which is an improvement of 0.61 over randomly generated sequences while maintaining a 100% maze completion rate. This is a 3.5 times the performance of the random baseline using our reference set.
* 5 pages, 6 figures, 3 tables; published in 2021 Southern African Universities Power Engineering Conference/Robotics and Mechatronics/Pattern Recognition Association of South Africa (SAUPEC/RobMech/PRASA), 2021, pp. 1-6, (c) 2021 IEEE
From Navigation to Racing: Reward Signal Design for Autonomous Racing
Mar 18, 2021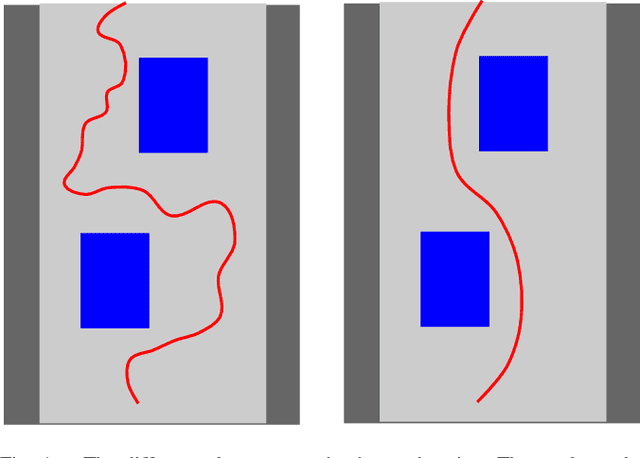
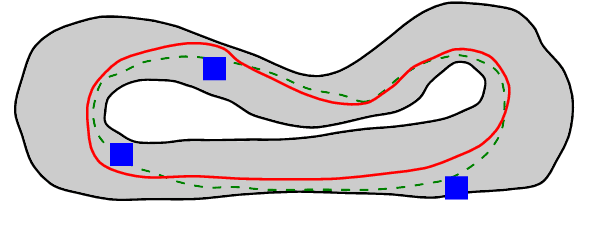
The problem of autonomous navigation is to generate a set of navigation references which when followed move the vehicle from a starting position to and end goal location while avoiding obstacles. Autonomous racing complicates the navigation problem by adding the objective of minimising the time to complete a track. Solutions aiming for a minimum time solution require that the planner is concerned with the optimality of the trajectory according to the vehicle dynamics. Neural networks, trained from experience with reinforcement learning, have shown to be effective local planners which generate navigation references to follow a global plan and avoid obstacles. We address the problem designing a reward signal which can be used to train neural network-based local planners to race in a time-efficient manner and avoid obstacles. The general challenge of reward signal design is to represent a desired behavior in an equation that can be calculated at each time step. The specific challenge of designing a reward signal for autonomous racing is to encode obstacle-free, time optimal racing trajectories in a clear signal We propose several methods of encoding ideal racing behavior based using a combination of the position and velocity of the vehicle and the actions taken by the network. The reward function candidates are expressed as equations and evaluated in the context of F1/10th autonomous racing. The results show that the best reward signal rewards velocity along, and punishes the lateral deviation from a precalculated, optimal reference trajectory.
Autonomous Obstacle Avoidance by Learning Policies for Reference Modification
Feb 22, 2021

The key problem for autonomous robots is how to navigate through complex, obstacle filled environments. The navigation problem is broken up into generating a reference path to the goal and then using a local planner to track the reference path and avoid obstacles by generating velocity and steering references for a control system to execute. This paper presents a novel local planner architecture for path following and obstacle avoidance by proposing a hybrid system that uses a classic path following algorithm in parallel with a neural network. Our solution, called the modification architecture, uses a path following algorithm to follow a reference path and a neural network to modify the references generated by the path follower in order to prevent collisions. The neural network is trained using reinforcement learning to deviate from the reference trajectory just enough to avoid crashing. We present our local planner in a hierarchical planning framework, nested between a global reference planner and a low-level control system. The system is evaluated in the context of F1/10th scale autonomous racing in random forests and on a race track. The results demonstrate that our solution is able to follow a reference trajectory while avoiding obstacles using only 10 sparse laser range finder readings. Our hybrid system overcomes previous limitations by not requiring an obstacle map, human demonstrations, or an instrumented training setup.
Unsupervised feature learning for speech using correspondence and Siamese networks
Mar 28, 2020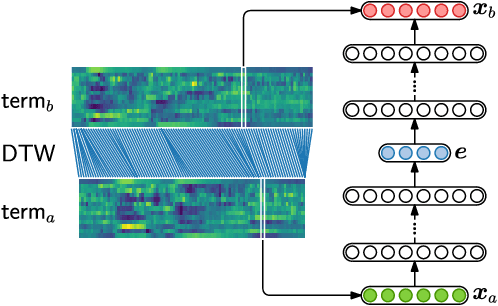
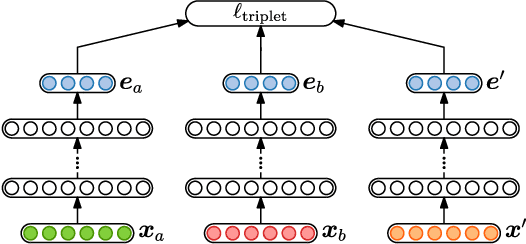
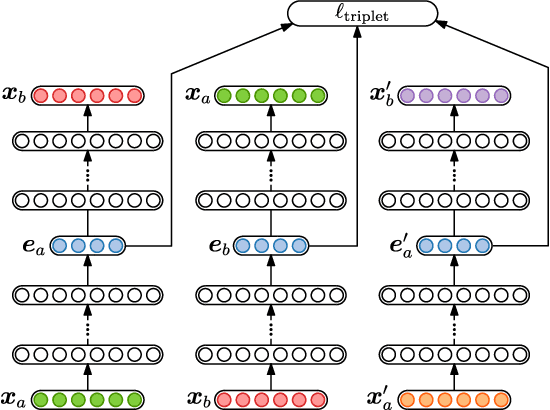
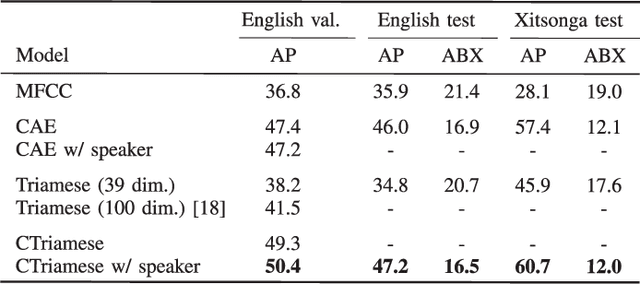
In zero-resource settings where transcribed speech audio is unavailable, unsupervised feature learning is essential for downstream speech processing tasks. Here we compare two recent methods for frame-level acoustic feature learning. For both methods, unsupervised term discovery is used to find pairs of word examples of the same unknown type. Dynamic programming is then used to align the feature frames between each word pair, serving as weak top-down supervision for the two models. For the correspondence autoencoder (CAE), matching frames are presented as input-output pairs. The Triamese network uses a contrastive loss to reduce the distance between frames of the same predicted word type while increasing the distance between negative examples. For the first time, these feature extractors are compared on the same discrimination tasks using the same weak supervision pairs. We find that, on the two datasets considered here, the CAE outperforms the Triamese network. However, we show that a new hybrid correspondence-Triamese approach (CTriamese), consistently outperforms both the CAE and Triamese models in terms of average precision and ABX error rates on both English and Xitsonga evaluation data.
* 5 pages, 3 figures, 2 tables; accepted to the IEEE Signal Processing Letters, (c) 2020 IEEE
Deep motion estimation for parallel inter-frame prediction in video compression
Dec 11, 2019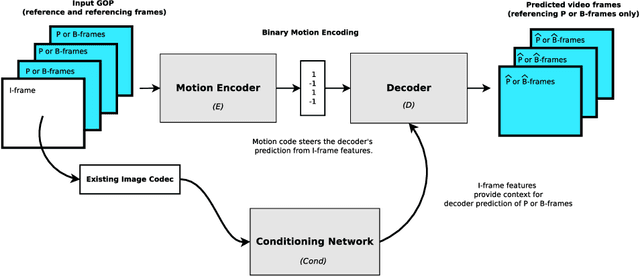
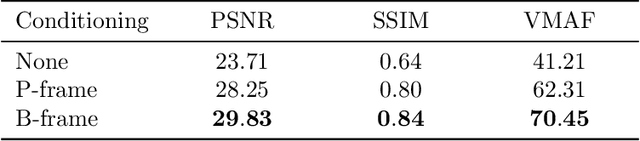
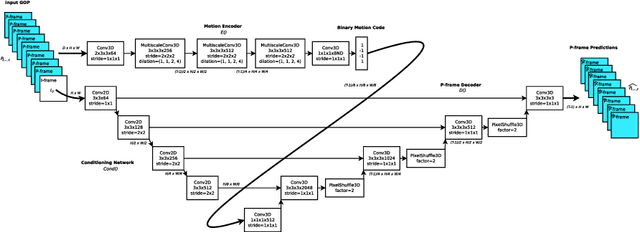

Standard video codecs rely on optical flow to guide inter-frame prediction: pixels from reference frames are moved via motion vectors to predict target video frames. We propose to learn binary motion codes that are encoded based on an input video sequence. These codes are not limited to 2D translations, but can capture complex motion (warping, rotation and occlusion). Our motion codes are learned as part of a single neural network which also learns to compress and decode them. This approach supports parallel video frame decoding instead of the sequential motion estimation and compensation of flow-based methods. We also introduce 3D dynamic bit assignment to adapt to object displacements caused by motion, yielding additional bit savings. By replacing the optical flow-based block-motion algorithms found in an existing video codec with our learned inter-frame prediction model, our approach outperforms the standard H.264 and H.265 video codecs across at low bitrates.
BINet: a binary inpainting network for deep patch-based image compression
Dec 11, 2019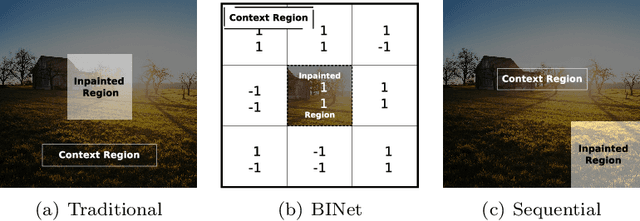

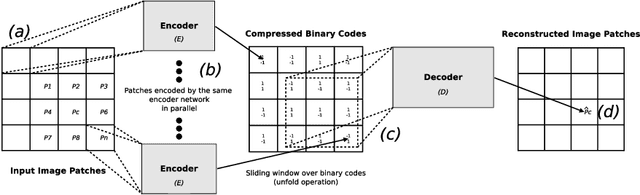

Recent deep learning models outperform standard lossy image compression codecs. However, applying these models on a patch-by-patch basis requires that each image patch be encoded and decoded independently. The influence from adjacent patches is therefore lost, leading to block artefacts at low bitrates. We propose the Binary Inpainting Network (BINet), an autoencoder framework which incorporates binary inpainting to reinstate interdependencies between adjacent patches, for improved patch-based compression of still images. When decoding a patch, BINet additionally uses the binarised encodings from surrounding patches to guide its reconstruction. In contrast to sequential inpainting methods where patches are decoded based on previons reconstructions, BINet operates directly on the binary codes of surrounding patches without access to the original or reconstructed image data. Encoding and decoding can therefore be performed in parallel. We demonstrate that BINet improves the compression quality of a competitive deep image codec across a range of compression levels.
Multimodal One-Shot Learning of Speech and Images
Nov 09, 2018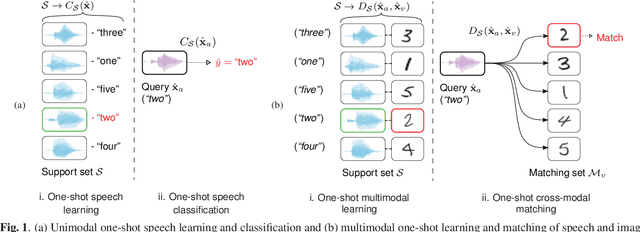
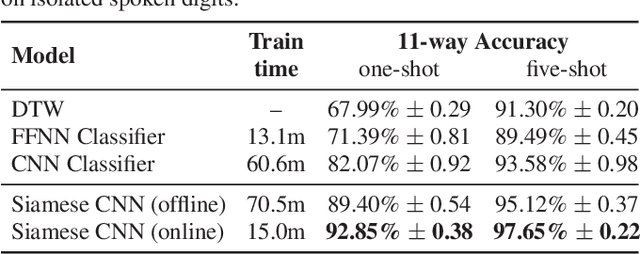


Imagine a robot is shown new concepts visually together with spoken tags, e.g. "milk", "eggs", "butter". After seeing one paired audio-visual example per class, it is shown a new set of unseen instances of these objects, and asked to pick the "milk". Without receiving any hard labels, could it learn to match the new continuous speech input to the correct visual instance? Although unimodal one-shot learning has been studied, where one labelled example in a single modality is given per class, this example motivates multimodal one-shot learning. Our main contribution is to formally define this task, and to propose several baseline and advanced models. We use a dataset of paired spoken and visual digits to specifically investigate recent advances in Siamese convolutional neural networks. Our best Siamese model achieves twice the accuracy of a nearest neighbour model using pixel-distance over images and dynamic time warping over speech in 11-way cross-modal matching.