 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal One-Shot Learning of Speech and Images
Paper and Code
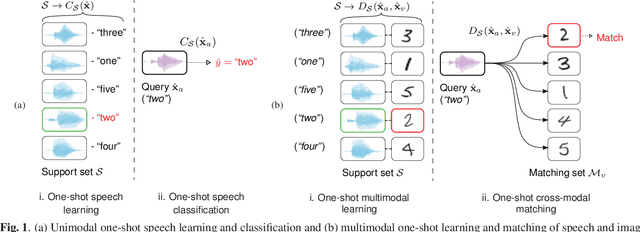
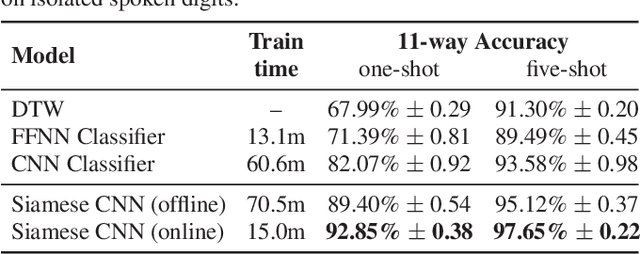


Imagine a robot is shown new concepts visually together with spoken tags, e.g. "milk", "eggs", "butter". After seeing one paired audio-visual example per class, it is shown a new set of unseen instances of these objects, and asked to pick the "milk". Without receiving any hard labels, could it learn to match the new continuous speech input to the correct visual instance? Although unimodal one-shot learning has been studied, where one labelled example in a single modality is given per class, this example motivates multimodal one-shot learning. Our main contribution is to formally define this task, and to propose several baseline and advanced models. We use a dataset of paired spoken and visual digits to specifically investigate recent advances in Siamese convolutional neural networks. Our best Siamese model achieves twice the accuracy of a nearest neighbour model using pixel-distance over images and dynamic time warping over speech in 11-way cross-modal matching.