 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIf dropout limits trainable depth, does critical initialisation still matter? A large-scale statistical analysis on ReLU networks
Oct 13, 2019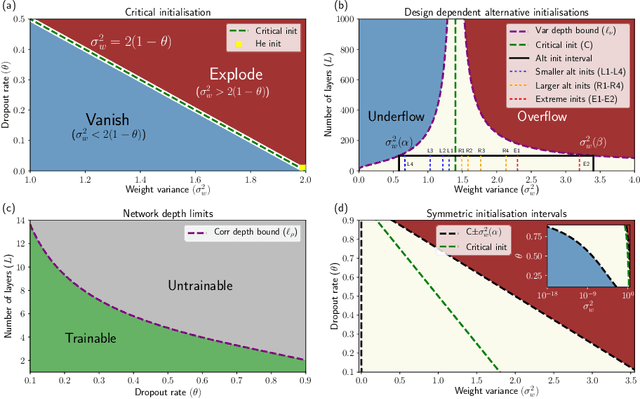

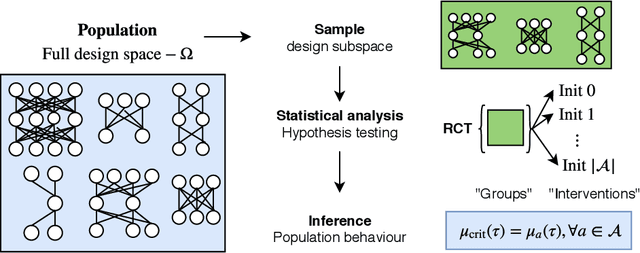
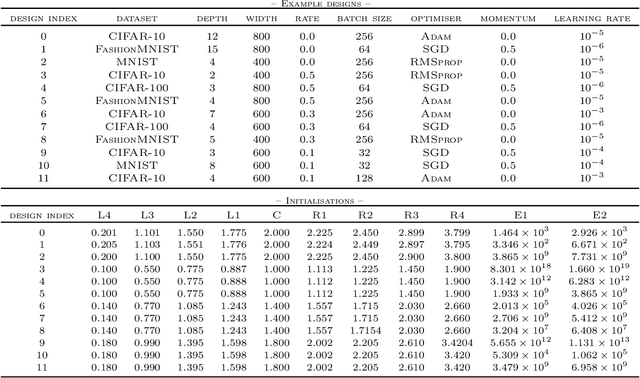
Recent work in signal propagation theory has shown that dropout limits the depth to which information can propagate through a neural network. In this paper, we investigate the effect of initialisation on training speed and generalisation for ReLU networks within this depth limit. We ask the following research question: given that critical initialisation is crucial for training at large depth, if dropout limits the depth at which networks are trainable, does initialising critically still matter? We conduct a large-scale controlled experiment, and perform a statistical analysis of over $12000$ trained networks. We find that (1) trainable networks show no statistically significant difference in performance over a wide range of non-critical initialisations; (2) for initialisations that show a statistically significant difference, the net effect on performance is small; (3) only extreme initialisations (very small or very large) perform worse than criticality. These findings also apply to standard ReLU networks of moderate depth as a special case of zero dropout. Our results therefore suggest that, in the shallow-to-moderate depth setting, critical initialisation provides zero performance gains when compared to off-critical initialisations and that searching for off-critical initialisations that might improve training speed or generalisation, is likely to be a fruitless endeavour.
Unsupervised acoustic unit discovery for speech synthesis using discrete latent-variable neural networks
Apr 16, 2019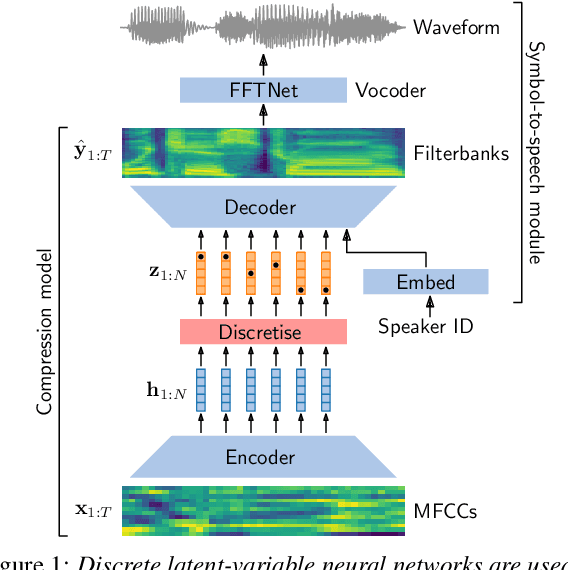

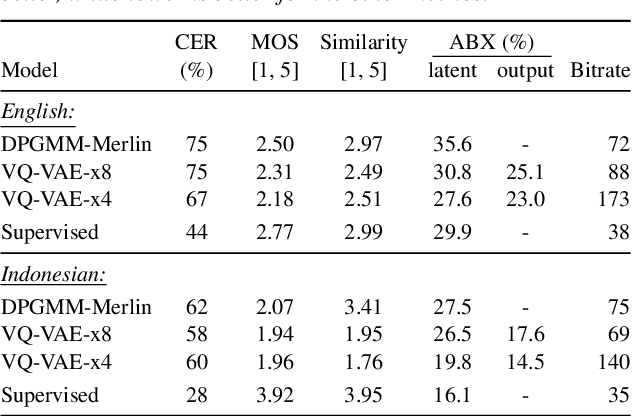
For our submission to the ZeroSpeech 2019 challenge, we apply discrete latent-variable neural networks to unlabelled speech and use the discovered units for speech synthesis. Unsupervised discrete subword modelling could be useful for studies of phonetic category learning in infants or in low-resource speech technology requiring symbolic input. We use an autoencoder (AE) architecture with intermediate discretisation. We decouple acoustic unit discovery from speaker modelling by conditioning the AE's decoder on the training speaker identity. At test time, unit discovery is performed on speech from an unseen speaker, followed by unit decoding conditioned on a known target speaker to obtain reconstructed filterbanks. This output is fed to a neural vocoder to synthesise speech in the target speaker's voice. For discretisation, categorical variational autoencoders (CatVAEs), vector-quantised VAEs (VQ-VAEs) and straight-through estimation are compared at different compression levels on two languages. Our final model uses convolutional encoding, VQ-VAE discretisation, deconvolutional decoding and an FFTNet vocoder. We show that decoupled speaker conditioning intrinsically improves discrete acoustic representations, yielding competitive synthesis quality compared to the challenge baseline.
Multimodal One-Shot Learning of Speech and Images
Nov 09, 2018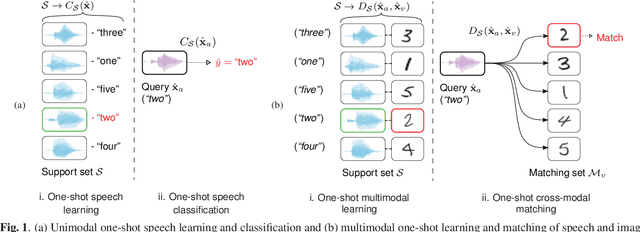
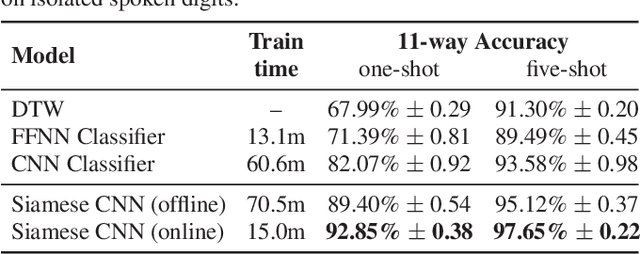


Imagine a robot is shown new concepts visually together with spoken tags, e.g. "milk", "eggs", "butter". After seeing one paired audio-visual example per class, it is shown a new set of unseen instances of these objects, and asked to pick the "milk". Without receiving any hard labels, could it learn to match the new continuous speech input to the correct visual instance? Although unimodal one-shot learning has been studied, where one labelled example in a single modality is given per class, this example motivates multimodal one-shot learning. Our main contribution is to formally define this task, and to propose several baseline and advanced models. We use a dataset of paired spoken and visual digits to specifically investigate recent advances in Siamese convolutional neural networks. Our best Siamese model achieves twice the accuracy of a nearest neighbour model using pixel-distance over images and dynamic time warping over speech in 11-way cross-modal matching.