 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe mutual exclusivity bias of bilingual visually grounded speech models
Jun 04, 2025Mutual exclusivity (ME) is a strategy where a novel word is associated with a novel object rather than a familiar one, facilitating language learning in children. Recent work has found an ME bias in a visually grounded speech (VGS) model trained on English speech with paired images. But ME has also been studied in bilingual children, who may employ it less due to cross-lingual ambiguity. We explore this pattern computationally using bilingual VGS models trained on combinations of English, French, and Dutch. We find that bilingual models generally exhibit a weaker ME bias than monolingual models, though exceptions exist. Analyses show that the combined visual embeddings of bilingual models have a smaller variance for familiar data, partly explaining the increase in confusion between novel and familiar concepts. We also provide new insights into why the ME bias exists in VGS models in the first place. Code and data: https://github.com/danoneata/me-vgs
Improved Visually Prompted Keyword Localisation in Real Low-Resource Settings
Sep 09, 2024



Given an image query, visually prompted keyword localisation (VPKL) aims to find occurrences of the depicted word in a speech collection. This can be useful when transcriptions are not available for a low-resource language (e.g. if it is unwritten). Previous work showed that VPKL can be performed with a visually grounded speech model trained on paired images and unlabelled speech. But all experiments were done on English. Moreover, transcriptions were used to get positive and negative pairs for the contrastive loss. This paper introduces a few-shot learning scheme to mine pairs automatically without transcriptions. On English, this results in only a small drop in performance. We also - for the first time - consider VPKL on a real low-resource language, Yoruba. While scores are reasonable, here we see a bigger drop in performance compared to using ground truth pairs because the mining is less accurate in Yoruba.
Visually Grounded Speech Models for Low-resource Languages and Cognitive Modelling
Sep 03, 2024This dissertation examines visually grounded speech (VGS) models that learn from unlabelled speech paired with images. It focuses on applications for low-resource languages and understanding human language acquisition. We introduce a task called visually prompted keyword localisation to detect and localise keywords in speech using images. We demonstrate the effectiveness of VGS models in few-shot learning scenarios for low-resource languages like Yoruba. Additionally, we examine the mutual exclusivity bias in VGS models. Our monolingual VGS model exhibits this bias, but we found that multilingualism does not affect the bias in this VGS model similarly to what is observed in children.
Visually Grounded Speech Models have a Mutual Exclusivity Bias
Mar 20, 2024When children learn new words, they employ constraints such as the mutual exclusivity (ME) bias: a novel word is mapped to a novel object rather than a familiar one. This bias has been studied computationally, but only in models that use discrete word representations as input, ignoring the high variability of spoken words. We investigate the ME bias in the context of visually grounded speech models that learn from natural images and continuous speech audio. Concretely, we train a model on familiar words and test its ME bias by asking it to select between a novel and a familiar object when queried with a novel word. To simulate prior acoustic and visual knowledge, we experiment with several initialisation strategies using pretrained speech and vision networks. Our findings reveal the ME bias across the different initialisation approaches, with a stronger bias in models with more prior (in particular, visual) knowledge. Additional tests confirm the robustness of our results, even when different loss functions are considered.
Visually grounded few-shot word learning in low-resource settings
Jun 21, 2023


We propose a visually grounded speech model that learns new words and their visual depictions from just a few word-image example pairs. Given a set of test images and a spoken query, we ask the model which image depicts the query word. Previous work has simplified this few-shot learning problem by either using an artificial setting with digit word-image pairs or by using a large number of examples per class. Moreover, all previous studies were performed using English speech-image data. We propose an approach that can work on natural word-image pairs but with less examples, i.e. fewer shots, and then illustrate how this approach can be applied for multimodal few-shot learning in a real low-resource language, Yoruba. Our approach involves using the given word-image example pairs to mine new unsupervised word-image training pairs from large collections of unlabelledspeech and images. Additionally, we use a word-to-image attention mechanism to determine word-image similarity. With this new model, we achieve better performance with fewer shots than previous approaches on an existing English benchmark. Many of the model's mistakes are due to confusion between visual concepts co-occurring in similar contexts. The experiments on Yoruba show the benefit of transferring knowledge from a multimodal model trained on a larger set of English speech-image data.
Visually grounded few-shot word acquisition with fewer shots
May 25, 2023



We propose a visually grounded speech model that acquires new words and their visual depictions from just a few word-image example pairs. Given a set of test images and a spoken query, we ask the model which image depicts the query word. Previous work has simplified this problem by either using an artificial setting with digit word-image pairs or by using a large number of examples per class. We propose an approach that can work on natural word-image pairs but with less examples, i.e. fewer shots. Our approach involves using the given word-image example pairs to mine new unsupervised word-image training pairs from large collections of unlabelled speech and images. Additionally, we use a word-to-image attention mechanism to determine word-image similarity. With this new model, we achieve better performance with fewer shots than any existing approach.
Towards visually prompted keyword localisation for zero-resource spoken languages
Oct 12, 2022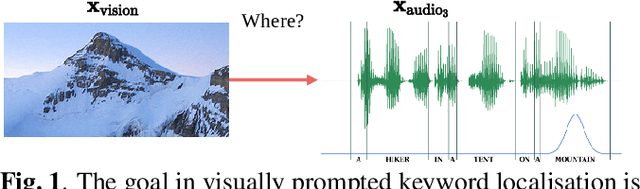
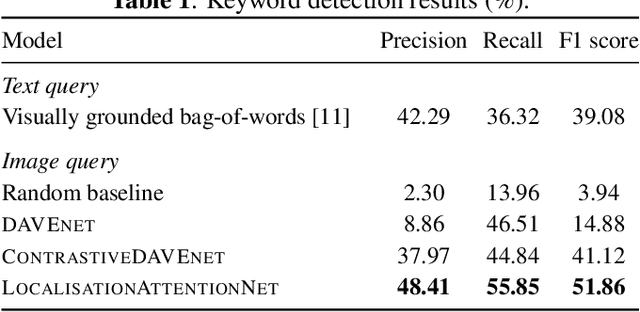
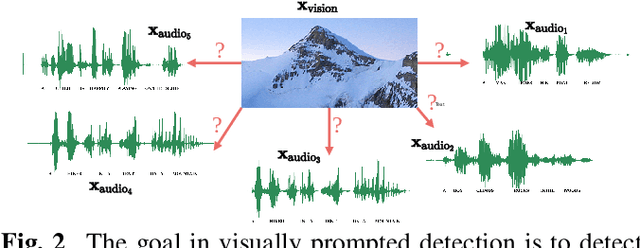
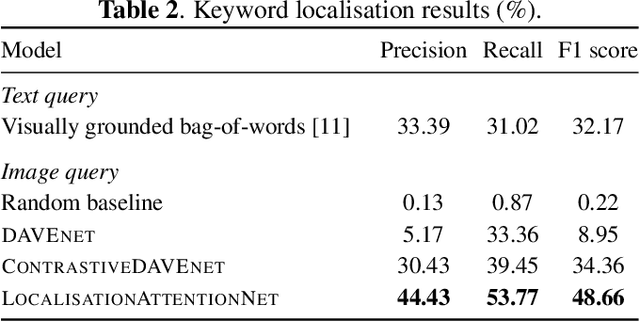
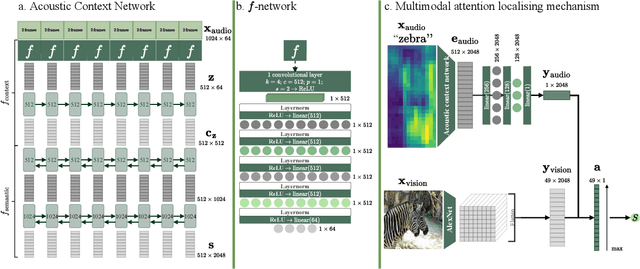
Imagine being able to show a system a visual depiction of a keyword and finding spoken utterances that contain this keyword from a zero-resource speech corpus. We formalise this task and call it visually prompted keyword localisation (VPKL): given an image of a keyword, detect and predict where in an utterance the keyword occurs. To do VPKL, we propose a speech-vision model with a novel localising attention mechanism which we train with a new keyword sampling scheme. We show that these innovations give improvements in VPKL over an existing speech-vision model. We also compare to a visual bag-of-words (BoW) model where images are automatically tagged with visual labels and paired with unlabelled speech. Although this visual BoW can be queried directly with a written keyword (while our's takes image queries), our new model still outperforms the visual BoW in both detection and localisation, giving a 16% relative improvement in localisation F1.
Analyzing Speaker Information in Self-Supervised Models to Improve Zero-Resource Speech Processing
Aug 02, 2021
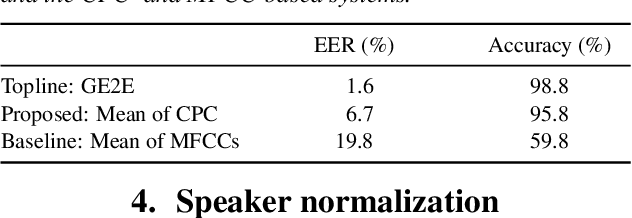
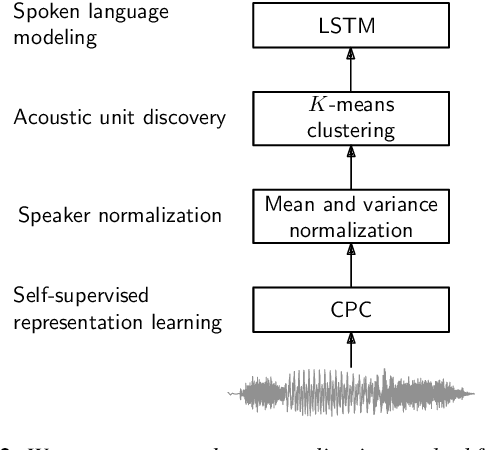
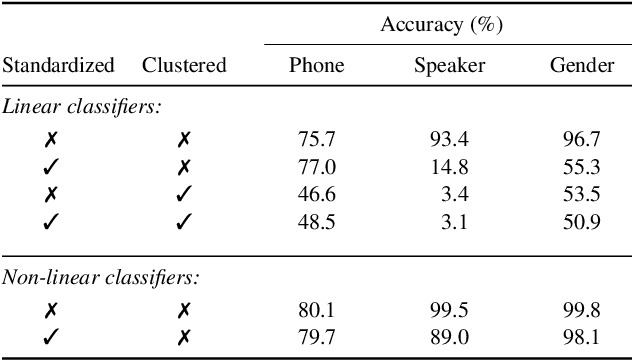
Contrastive predictive coding (CPC) aims to learn representations of speech by distinguishing future observations from a set of negative examples. Previous work has shown that linear classifiers trained on CPC features can accurately predict speaker and phone labels. However, it is unclear how the features actually capture speaker and phonetic information, and whether it is possible to normalize out the irrelevant details (depending on the downstream task). In this paper, we first show that the per-utterance mean of CPC features captures speaker information to a large extent. Concretely, we find that comparing means performs well on a speaker verification task. Next, probing experiments show that standardizing the features effectively removes speaker information. Based on this observation, we propose a speaker normalization step to improve acoustic unit discovery using K-means clustering of CPC features. Finally, we show that a language model trained on the resulting units achieves some of the best results in the ZeroSpeech2021~Challenge.
Direct multimodal few-shot learning of speech and images
Dec 10, 2020



We propose direct multimodal few-shot models that learn a shared embedding space of spoken words and images from only a few paired examples. Imagine an agent is shown an image along with a spoken word describing the object in the picture, e.g. pen, book and eraser. After observing a few paired examples of each class, the model is asked to identify the "book" in a set of unseen pictures. Previous work used a two-step indirect approach relying on learned unimodal representations: speech-speech and image-image comparisons are performed across the support set of given speech-image pairs. We propose two direct models which instead learn a single multimodal space where inputs from different modalities are directly comparable: a multimodal triplet network (MTriplet) and a multimodal correspondence autoencoder (MCAE). To train these direct models, we mine speech-image pairs: the support set is used to pair up unlabelled in-domain speech and images. In a speech-to-image digit matching task, direct models outperform indirect models, with the MTriplet achieving the best multimodal five-shot accuracy. We show that the improvements are due to the combination of unsupervised and transfer learning in the direct models, and the absence of two-step compounding errors.
Unsupervised vs. transfer learning for multimodal one-shot matching of speech and images
Aug 14, 2020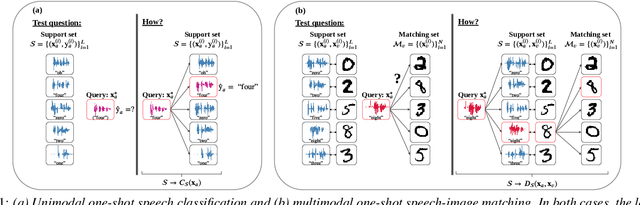

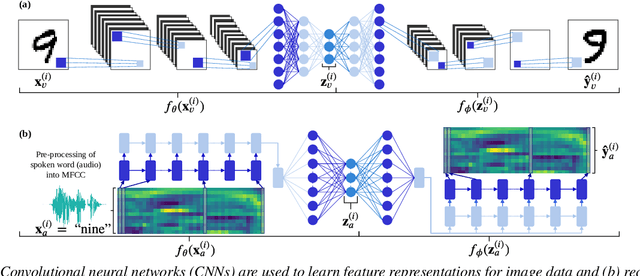
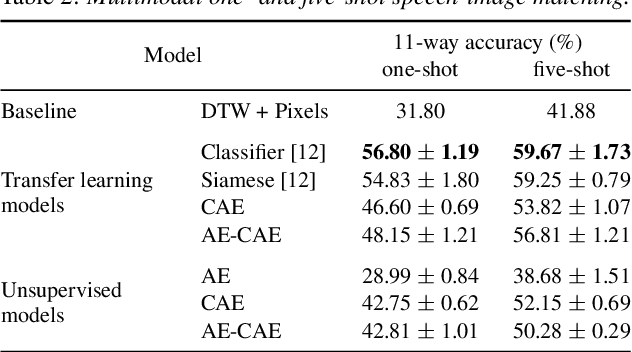
We consider the task of multimodal one-shot speech-image matching. An agent is shown a picture along with a spoken word describing the object in the picture, e.g. cookie, broccoli and ice-cream. After observing one paired speech-image example per class, it is shown a new set of unseen pictures, and asked to pick the "ice-cream". Previous work attempted to tackle this problem using transfer learning: supervised models are trained on labelled background data not containing any of the one-shot classes. Here we compare transfer learning to unsupervised models trained on unlabelled in-domain data. On a dataset of paired isolated spoken and visual digits, we specifically compare unsupervised autoencoder-like models to supervised classifier and Siamese neural networks. In both unimodal and multimodal few-shot matching experiments, we find that transfer learning outperforms unsupervised training. We also present experiments towards combining the two methodologies, but find that transfer learning still performs best (despite idealised experiments showing the benefits of unsupervised learning).