 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Speaker Characteristics in the Dimensions of Self-Supervised Speech Features
Mar 03, 2026How do speech models trained through self-supervised learning structure their representations? Previous studies have looked at how information is encoded in feature vectors across different layers. But few studies have considered whether speech characteristics are captured within individual dimensions of SSL features. In this paper we specifically look at speaker information using PCA on utterance-averaged representations. Using WavLM, we find that the principal dimension that explains most variance encodes pitch and associated characteristics like gender. Other individual principal dimensions correlate with intensity, noise levels, the second formant, and higher frequency characteristics. Finally, in synthesis experiments we show that most characteristics can be controlled by changing the corresponding dimensions. This provides a simple method to control characteristics of the output voice in synthesis applications.
ZeroSyl: Simple Zero-Resource Syllable Tokenization for Spoken Language Modeling
Feb 17, 2026Pure speech language models aim to learn language directly from raw audio without textual resources. A key challenge is that discrete tokens from self-supervised speech encoders result in excessively long sequences, motivating recent work on syllable-like units. However, methods like Sylber and SyllableLM rely on intricate multi-stage training pipelines. We propose ZeroSyl, a simple training-free method to extract syllable boundaries and embeddings directly from a frozen WavLM model. Using L2 norms of features in WavLM's intermediate layers, ZeroSyl achieves competitive syllable segmentation performance. The resulting segments are mean-pooled, discretized using K-means, and used to train a language model. ZeroSyl outperforms prior syllabic tokenizers across lexical, syntactic, and narrative benchmarks. Scaling experiments show that while finer-grained units are beneficial for lexical tasks, our discovered syllabic units exhibit better scaling behavior for syntactic modeling.
Automatically assessing oral narratives of Afrikaans and isiXhosa children
Jul 18, 2025Developing narrative and comprehension skills in early childhood is critical for later literacy. However, teachers in large preschool classrooms struggle to accurately identify students who require intervention. We present a system for automatically assessing oral narratives of preschool children in Afrikaans and isiXhosa. The system uses automatic speech recognition followed by a machine learning scoring model to predict narrative and comprehension scores. For scoring predicted transcripts, we compare a linear model to a large language model (LLM). The LLM-based system outperforms the linear model in most cases, but the linear system is competitive despite its simplicity. The LLM-based system is comparable to a human expert in flagging children who require intervention. We lay the foundation for automatic oral assessments in classrooms, giving teachers extra capacity to focus on personalised support for children's learning.
Feature-based analysis of oral narratives from Afrikaans and isiXhosa children
Jul 17, 2025Oral narrative skills are strong predictors of later literacy development. This study examines the features of oral narratives from children who were identified by experts as requiring intervention. Using simple machine learning methods, we analyse recorded stories from four- and five-year-old Afrikaans- and isiXhosa-speaking children. Consistent with prior research, we identify lexical diversity (unique words) and length-based features (mean utterance length) as indicators of typical development, but features like articulation rate prove less informative. Despite cross-linguistic variation in part-of-speech patterns, the use of specific verbs and auxiliaries associated with goal-directed storytelling is correlated with a reduced likelihood of requiring intervention. Our analysis of two linguistically distinct languages reveals both language-specific and shared predictors of narrative proficiency, with implications for early assessment in multilingual contexts.
Towards few-shot isolated word reading assessment
Jul 16, 2025We explore an ASR-free method for isolated word reading assessment in low-resource settings. Our few-shot approach compares input child speech to a small set of adult-provided reference templates. Inputs and templates are encoded using intermediate layers from large self-supervised learned (SSL) models. Using an Afrikaans child speech benchmark, we investigate design options such as discretising SSL features and barycentre averaging of the templates. Idealised experiments show reasonable performance for adults, but a substantial drop for child speech input, even with child templates. Despite the success of employing SSL representations in low-resource speech tasks, our work highlights the limitations of SSL representations for processing child data when used in a few-shot classification system.
Analyzing and Improving Speaker Similarity Assessment for Speech Synthesis
Jul 02, 2025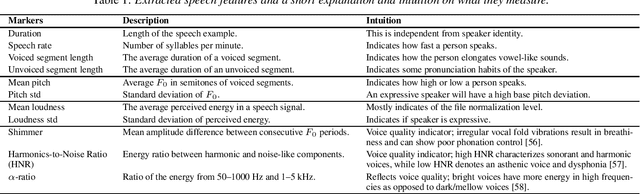

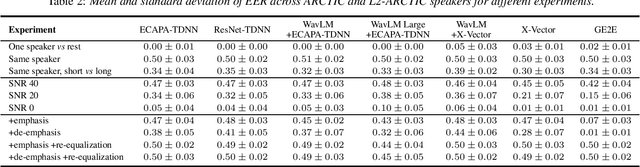
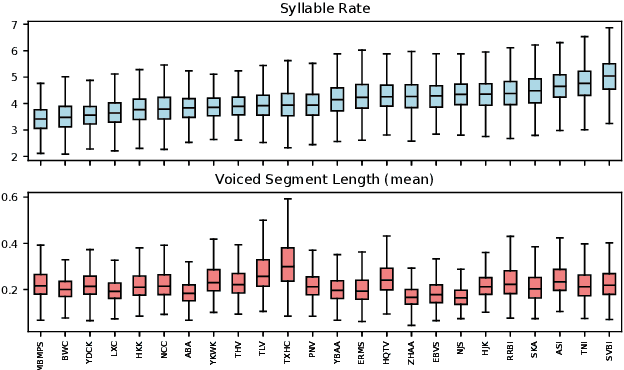
Modeling voice identity is challenging due to its multifaceted nature. In generative speech systems, identity is often assessed using automatic speaker verification (ASV) embeddings, designed for discrimination rather than characterizing identity. This paper investigates which aspects of a voice are captured in such representations. We find that widely used ASV embeddings focus mainly on static features like timbre and pitch range, while neglecting dynamic elements such as rhythm. We also identify confounding factors that compromise speaker similarity measurements and suggest mitigation strategies. To address these gaps, we propose U3D, a metric that evaluates speakers' dynamic rhythm patterns. This work contributes to the ongoing challenge of assessing speaker identity consistency in the context of ever-better voice cloning systems. We publicly release our code.
The mutual exclusivity bias of bilingual visually grounded speech models
Jun 04, 2025Mutual exclusivity (ME) is a strategy where a novel word is associated with a novel object rather than a familiar one, facilitating language learning in children. Recent work has found an ME bias in a visually grounded speech (VGS) model trained on English speech with paired images. But ME has also been studied in bilingual children, who may employ it less due to cross-lingual ambiguity. We explore this pattern computationally using bilingual VGS models trained on combinations of English, French, and Dutch. We find that bilingual models generally exhibit a weaker ME bias than monolingual models, though exceptions exist. Analyses show that the combined visual embeddings of bilingual models have a smaller variance for familiar data, partly explaining the increase in confusion between novel and familiar concepts. We also provide new insights into why the ME bias exists in VGS models in the first place. Code and data: https://github.com/danoneata/me-vgs
Spoken Language Modeling with Duration-Penalized Self-Supervised Units
May 29, 2025Spoken language models (SLMs) operate on acoustic units obtained by discretizing self-supervised speech representations. Although the characteristics of these units directly affect performance, the interaction between codebook size and unit coarseness (i.e., duration) remains unexplored. We investigate SLM performance as we vary codebook size and unit coarseness using the simple duration-penalized dynamic programming (DPDP) method. New analyses are performed across different linguistic levels. At the phone and word levels, coarseness provides little benefit, as long as the codebook size is chosen appropriately. However, when producing whole sentences in a resynthesis task, SLMs perform better with coarser units. In lexical and syntactic language modeling tasks, coarser units also give higher accuracies at lower bitrates. We therefore show that coarser units aren't always better, but that DPDP is a simple and efficient way to obtain coarser units for the tasks where they are beneficial.
Speech Recognition for Automatically Assessing Afrikaans and isiXhosa Preschool Oral Narratives
Jan 11, 2025We develop automatic speech recognition (ASR) systems for stories told by Afrikaans and isiXhosa preschool children. Oral narratives provide a way to assess children's language development before they learn to read. We consider a range of prior child-speech ASR strategies to determine which is best suited to this unique setting. Using Whisper and only 5 minutes of transcribed in-domain child speech, we find that additional in-domain adult data (adult speech matching the story domain) provides the biggest improvement, especially when coupled with voice conversion. Semi-supervised learning also helps for both languages, while parameter-efficient fine-tuning helps on Afrikaans but not on isiXhosa (which is under-represented in the Whisper model). Few child-speech studies look at non-English data, and even fewer at the preschool ages of 4 and 5. Our work therefore represents a unique validation of a wide range of previous child-speech ASR strategies in an under-explored setting.
MARS6: A Small and Robust Hierarchical-Codec Text-to-Speech Model
Jan 10, 2025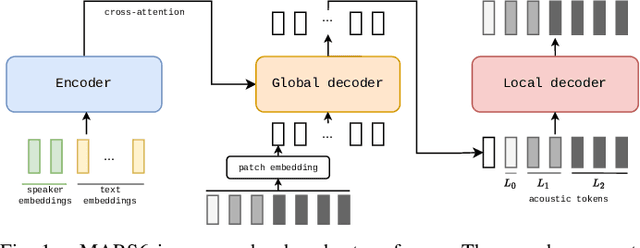
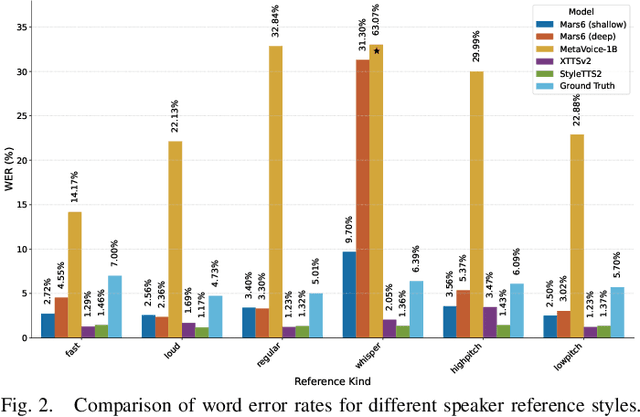
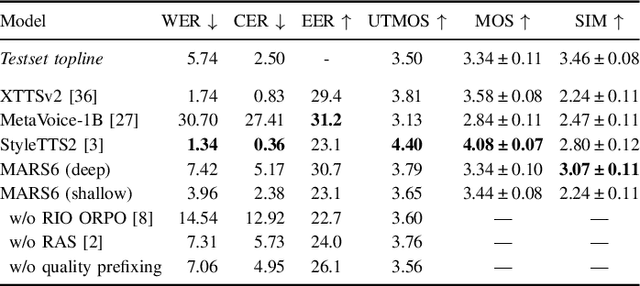
Codec-based text-to-speech (TTS) models have shown impressive quality with zero-shot voice cloning abilities. However, they often struggle with more expressive references or complex text inputs. We present MARS6, a robust encoder-decoder transformer for rapid, expressive TTS. MARS6 is built on recent improvements in spoken language modelling. Utilizing a hierarchical setup for its decoder, new speech tokens are processed at a rate of only 12 Hz, enabling efficient modelling of long-form text while retaining reconstruction quality. We combine several recent training and inference techniques to reduce repetitive generation and improve output stability and quality. This enables the 70M-parameter MARS6 to achieve similar performance to models many times larger. We show this in objective and subjective evaluations, comparing TTS output quality and reference speaker cloning ability. Project page: https://camb-ai.github.io/mars6-turbo/