 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpoken-Term Discovery using Discrete Speech Units
Paper and Code
Aug 26, 2024

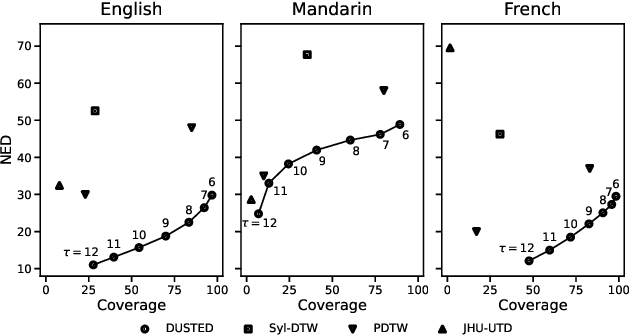

Discovering a lexicon from unlabeled audio is a longstanding challenge for zero-resource speech processing. One approach is to search for frequently occurring patterns in speech. We revisit this idea with DUSTED: Discrete Unit Spoken-TErm Discovery. Leveraging self-supervised models, we encode input audio into sequences of discrete units. Next, we find repeated patterns by searching for similar unit sub-sequences, inspired by alignment algorithms from bioinformatics. Since discretization discards speaker information, DUSTED finds better matches across speakers, improving the coverage and consistency of the discovered patterns. We demonstrate these improvements on the ZeroSpeech Challenge, achieving state-of-the-art results on the spoken-term discovery track. Finally, we analyze the duration distribution of the patterns, showing that our method finds longer word- or phrase-like terms.