 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing and Improving Speaker Similarity Assessment for Speech Synthesis
Jul 02, 2025

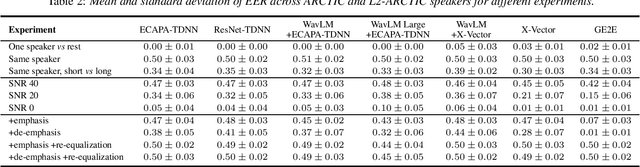
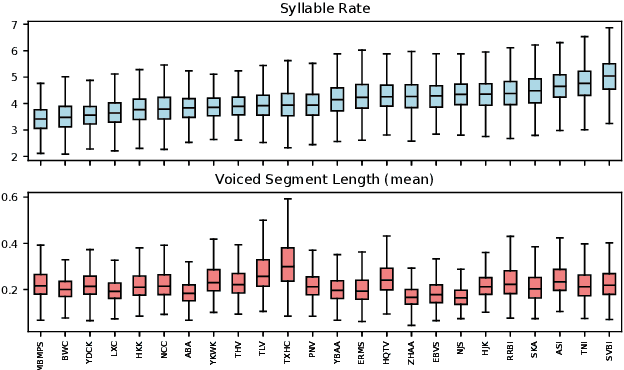
Modeling voice identity is challenging due to its multifaceted nature. In generative speech systems, identity is often assessed using automatic speaker verification (ASV) embeddings, designed for discrimination rather than characterizing identity. This paper investigates which aspects of a voice are captured in such representations. We find that widely used ASV embeddings focus mainly on static features like timbre and pitch range, while neglecting dynamic elements such as rhythm. We also identify confounding factors that compromise speaker similarity measurements and suggest mitigation strategies. To address these gaps, we propose U3D, a metric that evaluates speakers' dynamic rhythm patterns. This work contributes to the ongoing challenge of assessing speaker identity consistency in the context of ever-better voice cloning systems. We publicly release our code.
Geometry-Aware Texture Generation for 3D Head Modeling with Artist-driven Control
May 07, 2025Creating realistic 3D head assets for virtual characters that match a precise artistic vision remains labor-intensive. We present a novel framework that streamlines this process by providing artists with intuitive control over generated 3D heads. Our approach uses a geometry-aware texture synthesis pipeline that learns correlations between head geometry and skin texture maps across different demographics. The framework offers three levels of artistic control: manipulation of overall head geometry, adjustment of skin tone while preserving facial characteristics, and fine-grained editing of details such as wrinkles or facial hair. Our pipeline allows artists to make edits to a single texture map using familiar tools, with our system automatically propagating these changes coherently across the remaining texture maps needed for realistic rendering. Experiments demonstrate that our method produces diverse results with clean geometries. We showcase practical applications focusing on intuitive control for artists, including skin tone adjustments and simplified editing workflows for adding age-related details or removing unwanted features from scanned models. This integrated approach aims to streamline the artistic workflow in virtual character creation.
Spoken-Term Discovery using Discrete Speech Units
Aug 26, 2024

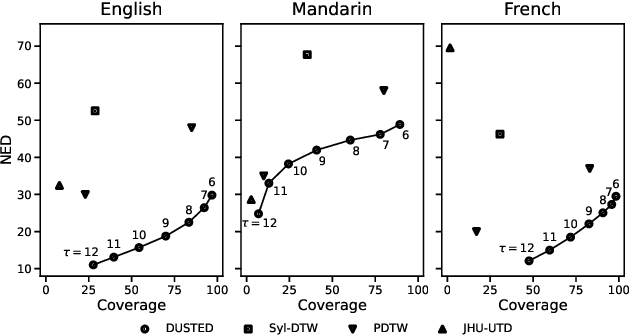

Discovering a lexicon from unlabeled audio is a longstanding challenge for zero-resource speech processing. One approach is to search for frequently occurring patterns in speech. We revisit this idea with DUSTED: Discrete Unit Spoken-TErm Discovery. Leveraging self-supervised models, we encode input audio into sequences of discrete units. Next, we find repeated patterns by searching for similar unit sub-sequences, inspired by alignment algorithms from bioinformatics. Since discretization discards speaker information, DUSTED finds better matches across speakers, improving the coverage and consistency of the discovered patterns. We demonstrate these improvements on the ZeroSpeech Challenge, achieving state-of-the-art results on the spoken-term discovery track. Finally, we analyze the duration distribution of the patterns, showing that our method finds longer word- or phrase-like terms.
BinaryAlign: Word Alignment as Binary Sequence Labeling
Jul 16, 2024Real world deployments of word alignment are almost certain to cover both high and low resource languages. However, the state-of-the-art for this task recommends a different model class depending on the availability of gold alignment training data for a particular language pair. We propose BinaryAlign, a novel word alignment technique based on binary sequence labeling that outperforms existing approaches in both scenarios, offering a unifying approach to the task. Additionally, we vary the specific choice of multilingual foundation model, perform stratified error analysis over alignment error type, and explore the performance of BinaryAlign on non-English language pairs. We make our source code publicly available.
Zero-shot Cross-Lingual Transfer for Synthetic Data Generation in Grammatical Error Detection
Jul 16, 2024Grammatical Error Detection (GED) methods rely heavily on human annotated error corpora. However, these annotations are unavailable in many low-resource languages. In this paper, we investigate GED in this context. Leveraging the zero-shot cross-lingual transfer capabilities of multilingual pre-trained language models, we train a model using data from a diverse set of languages to generate synthetic errors in other languages. These synthetic error corpora are then used to train a GED model. Specifically we propose a two-stage fine-tuning pipeline where the GED model is first fine-tuned on multilingual synthetic data from target languages followed by fine-tuning on human-annotated GED corpora from source languages. This approach outperforms current state-of-the-art annotation-free GED methods. We also analyse the errors produced by our method and other strong baselines, finding that our approach produces errors that are more diverse and more similar to human errors.
UPose3D: Uncertainty-Aware 3D Human Pose Estimation with Cross-View and Temporal Cues
Apr 23, 2024We introduce UPose3D, a novel approach for multi-view 3D human pose estimation, addressing challenges in accuracy and scalability. Our method advances existing pose estimation frameworks by improving robustness and flexibility without requiring direct 3D annotations. At the core of our method, a pose compiler module refines predictions from a 2D keypoints estimator that operates on a single image by leveraging temporal and cross-view information. Our novel cross-view fusion strategy is scalable to any number of cameras, while our synthetic data generation strategy ensures generalization across diverse actors, scenes, and viewpoints. Finally, UPose3D leverages the prediction uncertainty of both the 2D keypoint estimator and the pose compiler module. This provides robustness to outliers and noisy data, resulting in state-of-the-art performance in out-of-distribution settings. In addition, for in-distribution settings, UPose3D yields a performance rivaling methods that rely on 3D annotated data, while being the state-of-the-art among methods relying only on 2D supervision.
EDMSound: Spectrogram Based Diffusion Models for Efficient and High-Quality Audio Synthesis
Nov 18, 2023



Audio diffusion models can synthesize a wide variety of sounds. Existing models often operate on the latent domain with cascaded phase recovery modules to reconstruct waveform. This poses challenges when generating high-fidelity audio. In this paper, we propose EDMSound, a diffusion-based generative model in spectrogram domain under the framework of elucidated diffusion models (EDM). Combining with efficient deterministic sampler, we achieved similar Fr\'echet audio distance (FAD) score as top-ranked baseline with only 10 steps and reached state-of-the-art performance with 50 steps on the DCASE2023 foley sound generation benchmark. We also revealed a potential concern regarding diffusion based audio generation models that they tend to generate samples with high perceptual similarity to the data from training data. Project page: https://agentcooper2002.github.io/EDMSound/
Rhythm Modeling for Voice Conversion
Jul 12, 2023



Voice conversion aims to transform source speech into a different target voice. However, typical voice conversion systems do not account for rhythm, which is an important factor in the perception of speaker identity. To bridge this gap, we introduce Urhythmic-an unsupervised method for rhythm conversion that does not require parallel data or text transcriptions. Using self-supervised representations, we first divide source audio into segments approximating sonorants, obstruents, and silences. Then we model rhythm by estimating speaking rate or the duration distribution of each segment type. Finally, we match the target speaking rate or rhythm by time-stretching the speech segments. Experiments show that Urhythmic outperforms existing unsupervised methods in terms of quality and prosody. Code and checkpoints: https://github.com/bshall/urhythmic. Audio demo page: https://ubisoft-laforge.github.io/speech/urhythmic.
ZeroEGGS: Zero-shot Example-based Gesture Generation from Speech
Sep 23, 2022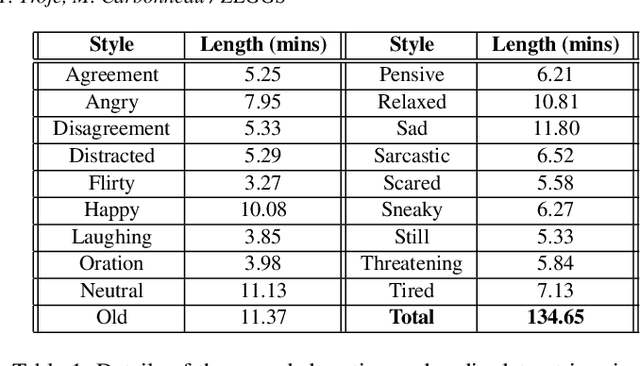
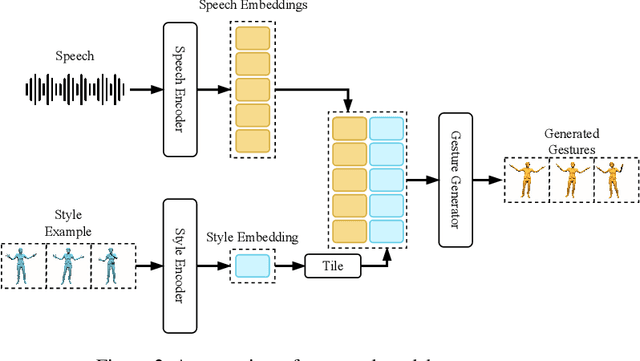

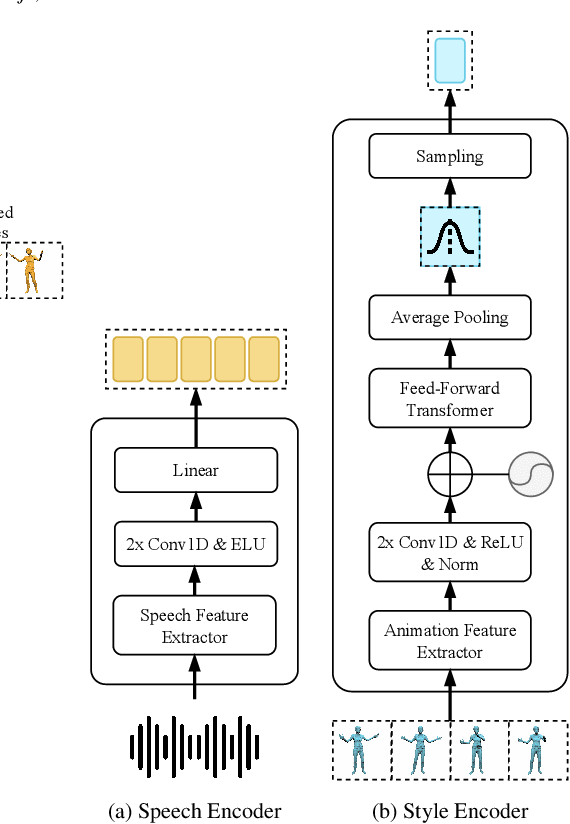
We present ZeroEGGS, a neural network framework for speech-driven gesture generation with zero-shot style control by example. This means style can be controlled via only a short example motion clip, even for motion styles unseen during training. Our model uses a Variational framework to learn a style embedding, making it easy to modify style through latent space manipulation or blending and scaling of style embeddings. The probabilistic nature of our framework further enables the generation of a variety of outputs given the same input, addressing the stochastic nature of gesture motion. In a series of experiments, we first demonstrate the flexibility and generalizability of our model to new speakers and styles. In a user study, we then show that our model outperforms previous state-of-the-art techniques in naturalness of motion, appropriateness for speech, and style portrayal. Finally, we release a high-quality dataset of full-body gesture motion including fingers, with speech, spanning across 19 different styles.
A Comparison of Discrete and Soft Speech Units for Improved Voice Conversion
Nov 03, 2021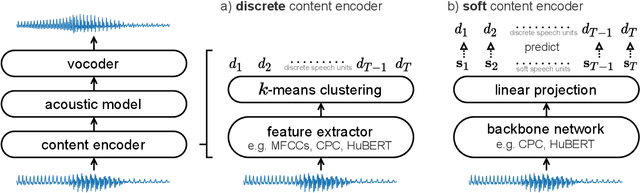
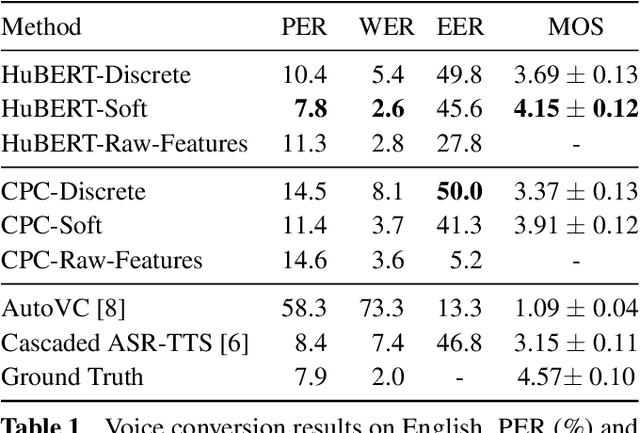

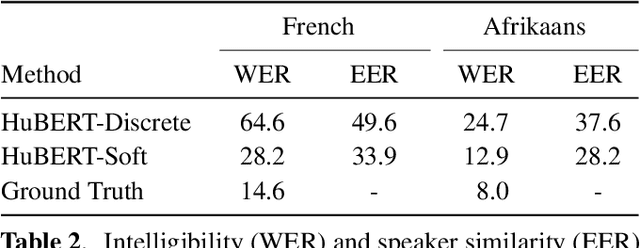
The goal of voice conversion is to transform source speech into a target voice, keeping the content unchanged. In this paper, we focus on self-supervised representation learning for voice conversion. Specifically, we compare discrete and soft speech units as input features. We find that discrete representations effectively remove speaker information but discard some linguistic content - leading to mispronunciations. As a solution, we propose soft speech units. To learn soft units, we predict a distribution over discrete speech units. By modeling uncertainty, soft units capture more content information, improving the intelligibility and naturalness of converted speech. Samples available at https://ubisoft-laforge.github.io/speech/soft-vc/