 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReciprocal Latent Fields for Precomputed Sound Propagation
Feb 06, 2026Realistic sound propagation is essential for immersion in a virtual scene, yet physically accurate wave-based simulations remain computationally prohibitive for real-time applications. Wave coding methods address this limitation by precomputing and compressing impulse responses of a given scene into a set of scalar acoustic parameters, which can reach unmanageable sizes in large environments with many source-receiver pairs. We introduce Reciprocal Latent Fields (RLF), a memory-efficient framework for encoding and predicting these acoustic parameters. The RLF framework employs a volumetric grid of trainable latent embeddings decoded with a symmetric function, ensuring acoustic reciprocity. We study a variety of decoders and show that leveraging Riemannian metric learning leads to a better reproduction of acoustic phenomena in complex scenes. Experimental validation demonstrates that RLF maintains replication quality while reducing the memory footprint by several orders of magnitude. Furthermore, a MUSHRA-like subjective listening test indicates that sound rendered via RLF is perceptually indistinguishable from ground-truth simulations.
Analyzing and Improving Speaker Similarity Assessment for Speech Synthesis
Jul 02, 2025

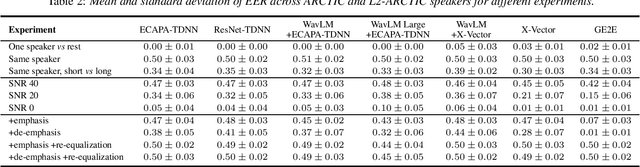
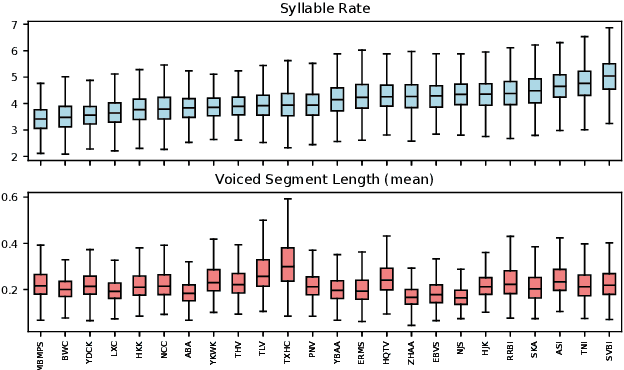
Modeling voice identity is challenging due to its multifaceted nature. In generative speech systems, identity is often assessed using automatic speaker verification (ASV) embeddings, designed for discrimination rather than characterizing identity. This paper investigates which aspects of a voice are captured in such representations. We find that widely used ASV embeddings focus mainly on static features like timbre and pitch range, while neglecting dynamic elements such as rhythm. We also identify confounding factors that compromise speaker similarity measurements and suggest mitigation strategies. To address these gaps, we propose U3D, a metric that evaluates speakers' dynamic rhythm patterns. This work contributes to the ongoing challenge of assessing speaker identity consistency in the context of ever-better voice cloning systems. We publicly release our code.
A Comparison of Discrete and Soft Speech Units for Improved Voice Conversion
Nov 03, 2021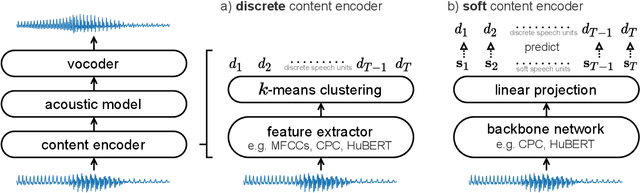
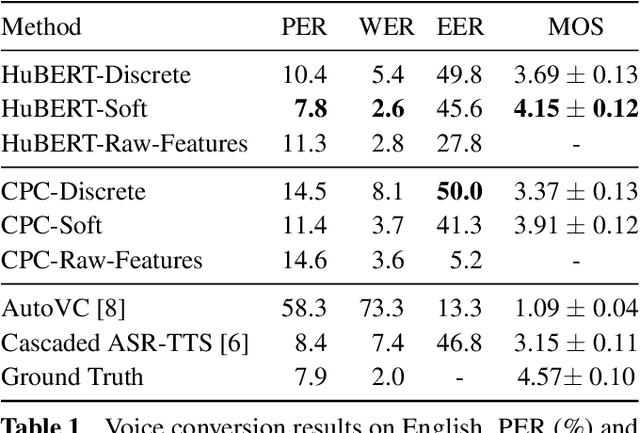

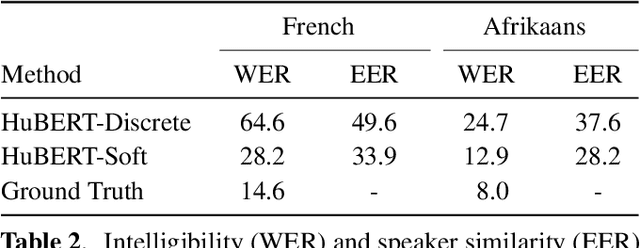
The goal of voice conversion is to transform source speech into a target voice, keeping the content unchanged. In this paper, we focus on self-supervised representation learning for voice conversion. Specifically, we compare discrete and soft speech units as input features. We find that discrete representations effectively remove speaker information but discard some linguistic content - leading to mispronunciations. As a solution, we propose soft speech units. To learn soft units, we predict a distribution over discrete speech units. By modeling uncertainty, soft units capture more content information, improving the intelligibility and naturalness of converted speech. Samples available at https://ubisoft-laforge.github.io/speech/soft-vc/
Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
Aug 04, 2021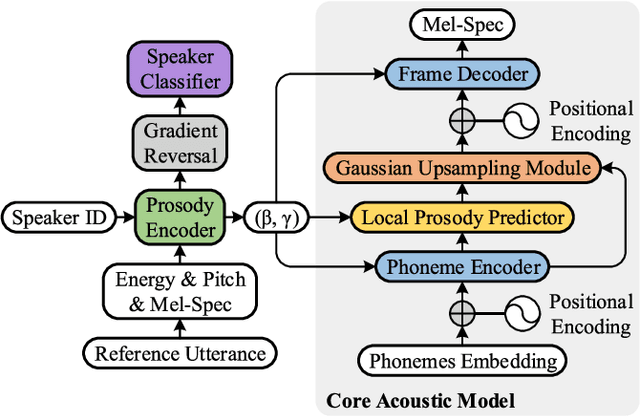

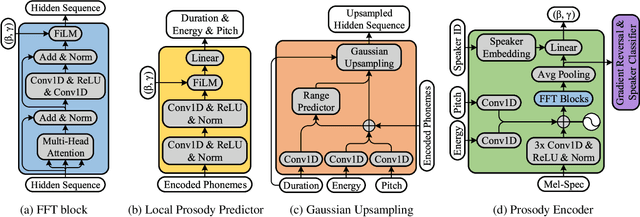

This paper presents Daft-Exprt, a multi-speaker acoustic model advancing the state-of-the-art on inter-speaker and inter-text prosody transfer. This improvement is achieved using FiLM conditioning layers, alongside adversarial training that encourages disentanglement between prosodic information and speaker identity. The acoustic model inherits attractive qualities from FastSpeech 2, such as fast inference and local prosody attributes prediction for finer grained control over generation. Experimental results show that Daft-Exprt significantly outperforms strong baselines on prosody transfer tasks, while yielding naturalness comparable to state-of-the-art expressive models. Moreover, results indicate that adversarial training effectively discards speaker identity information from the prosody representation, which ensures Daft-Exprt will consistently generate speech with the desired voice. We publicly release our code and provide speech samples from our experiments.