 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing and Improving Speaker Similarity Assessment for Speech Synthesis
Jul 02, 2025Modeling voice identity is challenging due to its multifaceted nature. In generative speech systems, identity is often assessed using automatic speaker verification (ASV) embeddings, designed for discrimination rather than characterizing identity. This paper investigates which aspects of a voice are captured in such representations. We find that widely used ASV embeddings focus mainly on static features like timbre and pitch range, while neglecting dynamic elements such as rhythm. We also identify confounding factors that compromise speaker similarity measurements and suggest mitigation strategies. To address these gaps, we propose U3D, a metric that evaluates speakers' dynamic rhythm patterns. This work contributes to the ongoing challenge of assessing speaker identity consistency in the context of ever-better voice cloning systems. We publicly release our code.
Unsupervised Word Discovery: Boundary Detection with Clustering vs. Dynamic Programming
Sep 22, 2024



We look at the long-standing problem of segmenting unlabeled speech into word-like segments and clustering these into a lexicon. Several previous methods use a scoring model coupled with dynamic programming to find an optimal segmentation. Here we propose a much simpler strategy: we predict word boundaries using the dissimilarity between adjacent self-supervised features, then we cluster the predicted segments to construct a lexicon. For a fair comparison, we update the older ES-KMeans dynamic programming method with better features and boundary constraints. On the five-language ZeroSpeech benchmarks, our simple approach gives similar state-of-the-art results compared to the new ES-KMeans+ method, while being almost five times faster.
Spoken-Term Discovery using Discrete Speech Units
Aug 26, 2024

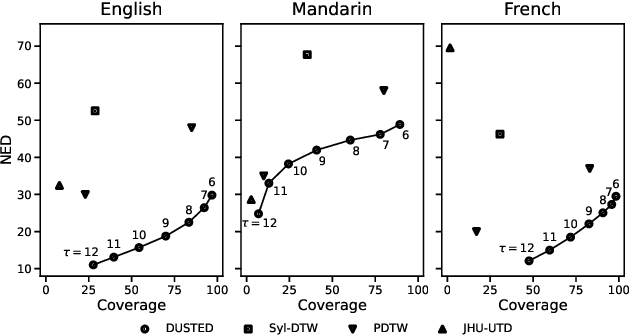

Discovering a lexicon from unlabeled audio is a longstanding challenge for zero-resource speech processing. One approach is to search for frequently occurring patterns in speech. We revisit this idea with DUSTED: Discrete Unit Spoken-TErm Discovery. Leveraging self-supervised models, we encode input audio into sequences of discrete units. Next, we find repeated patterns by searching for similar unit sub-sequences, inspired by alignment algorithms from bioinformatics. Since discretization discards speaker information, DUSTED finds better matches across speakers, improving the coverage and consistency of the discovered patterns. We demonstrate these improvements on the ZeroSpeech Challenge, achieving state-of-the-art results on the spoken-term discovery track. Finally, we analyze the duration distribution of the patterns, showing that our method finds longer word- or phrase-like terms.
Revisiting speech segmentation and lexicon learning with better features
Jan 31, 2024We revisit a self-supervised method that segments unlabelled speech into word-like segments. We start from the two-stage duration-penalised dynamic programming method that performs zero-resource segmentation without learning an explicit lexicon. In the first acoustic unit discovery stage, we replace contrastive predictive coding features with HuBERT. After word segmentation in the second stage, we get an acoustic word embedding for each segment by averaging HuBERT features. These embeddings are clustered using K-means to get a lexicon. The result is good full-coverage segmentation with a lexicon that achieves state-of-the-art performance on the ZeroSpeech benchmarks.
Rhythm Modeling for Voice Conversion
Jul 12, 2023



Voice conversion aims to transform source speech into a different target voice. However, typical voice conversion systems do not account for rhythm, which is an important factor in the perception of speaker identity. To bridge this gap, we introduce Urhythmic-an unsupervised method for rhythm conversion that does not require parallel data or text transcriptions. Using self-supervised representations, we first divide source audio into segments approximating sonorants, obstruents, and silences. Then we model rhythm by estimating speaking rate or the duration distribution of each segment type. Finally, we match the target speaking rate or rhythm by time-stretching the speech segments. Experiments show that Urhythmic outperforms existing unsupervised methods in terms of quality and prosody. Code and checkpoints: https://github.com/bshall/urhythmic. Audio demo page: https://ubisoft-laforge.github.io/speech/urhythmic.
Voice Conversion With Just Nearest Neighbors
May 30, 2023


Any-to-any voice conversion aims to transform source speech into a target voice with just a few examples of the target speaker as a reference. Recent methods produce convincing conversions, but at the cost of increased complexity -- making results difficult to reproduce and build on. Instead, we keep it simple. We propose k-nearest neighbors voice conversion (kNN-VC): a straightforward yet effective method for any-to-any conversion. First, we extract self-supervised representations of the source and reference speech. To convert to the target speaker, we replace each frame of the source representation with its nearest neighbor in the reference. Finally, a pretrained vocoder synthesizes audio from the converted representation. Objective and subjective evaluations show that kNN-VC improves speaker similarity with similar intelligibility scores to existing methods. Code, samples, trained models: https://bshall.github.io/knn-vc
Visually grounded few-shot word acquisition with fewer shots
May 25, 2023



We propose a visually grounded speech model that acquires new words and their visual depictions from just a few word-image example pairs. Given a set of test images and a spoken query, we ask the model which image depicts the query word. Previous work has simplified this problem by either using an artificial setting with digit word-image pairs or by using a large number of examples per class. We propose an approach that can work on natural word-image pairs but with less examples, i.e. fewer shots. Our approach involves using the given word-image example pairs to mine new unsupervised word-image training pairs from large collections of unlabelled speech and images. Additionally, we use a word-to-image attention mechanism to determine word-image similarity. With this new model, we achieve better performance with fewer shots than any existing approach.
A Comparison of Discrete and Soft Speech Units for Improved Voice Conversion
Nov 03, 2021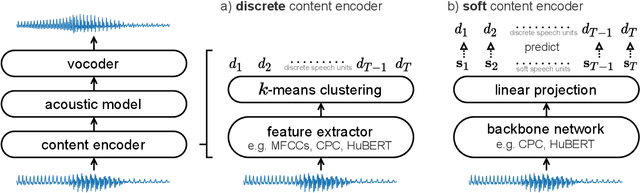
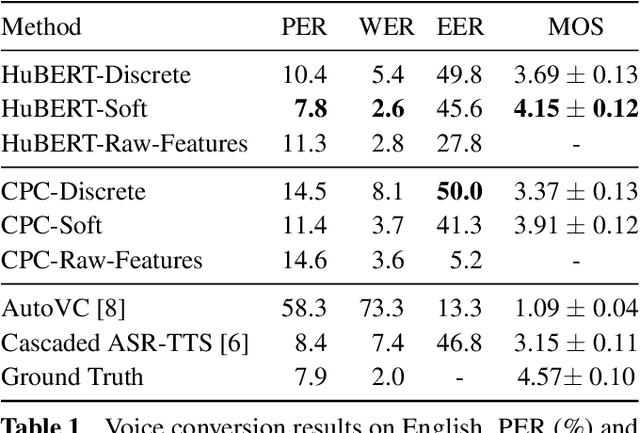

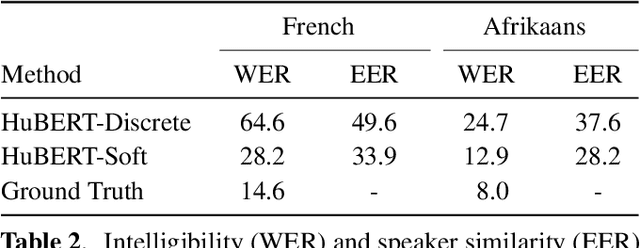
The goal of voice conversion is to transform source speech into a target voice, keeping the content unchanged. In this paper, we focus on self-supervised representation learning for voice conversion. Specifically, we compare discrete and soft speech units as input features. We find that discrete representations effectively remove speaker information but discard some linguistic content - leading to mispronunciations. As a solution, we propose soft speech units. To learn soft units, we predict a distribution over discrete speech units. By modeling uncertainty, soft units capture more content information, improving the intelligibility and naturalness of converted speech. Samples available at https://ubisoft-laforge.github.io/speech/soft-vc/
Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
Aug 04, 2021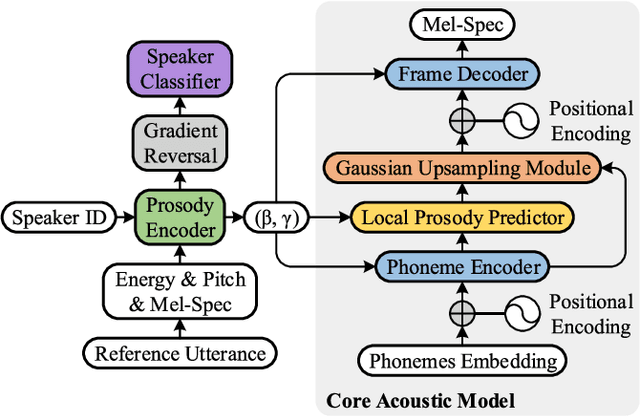

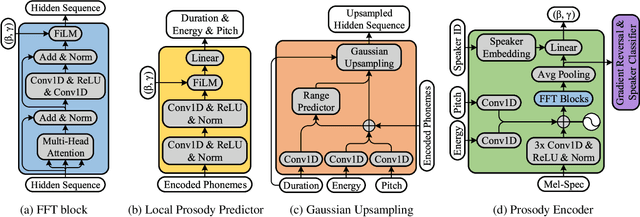

This paper presents Daft-Exprt, a multi-speaker acoustic model advancing the state-of-the-art on inter-speaker and inter-text prosody transfer. This improvement is achieved using FiLM conditioning layers, alongside adversarial training that encourages disentanglement between prosodic information and speaker identity. The acoustic model inherits attractive qualities from FastSpeech 2, such as fast inference and local prosody attributes prediction for finer grained control over generation. Experimental results show that Daft-Exprt significantly outperforms strong baselines on prosody transfer tasks, while yielding naturalness comparable to state-of-the-art expressive models. Moreover, results indicate that adversarial training effectively discards speaker identity information from the prosody representation, which ensures Daft-Exprt will consistently generate speech with the desired voice. We publicly release our code and provide speech samples from our experiments.
Analyzing Speaker Information in Self-Supervised Models to Improve Zero-Resource Speech Processing
Aug 02, 2021
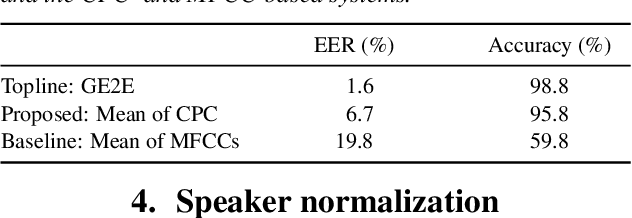
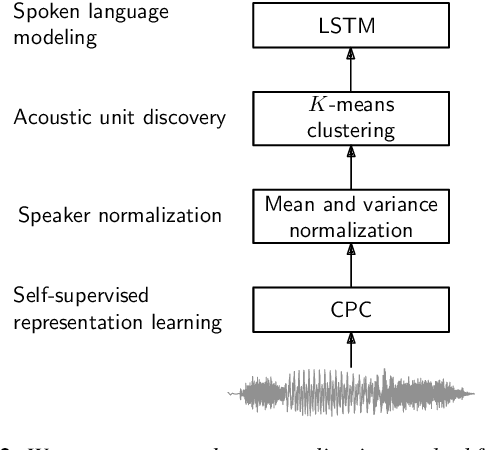
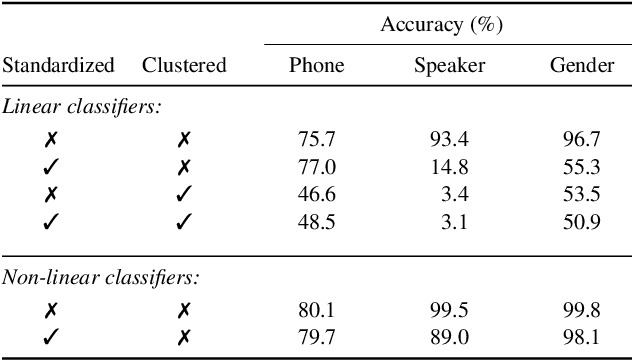
Contrastive predictive coding (CPC) aims to learn representations of speech by distinguishing future observations from a set of negative examples. Previous work has shown that linear classifiers trained on CPC features can accurately predict speaker and phone labels. However, it is unclear how the features actually capture speaker and phonetic information, and whether it is possible to normalize out the irrelevant details (depending on the downstream task). In this paper, we first show that the per-utterance mean of CPC features captures speaker information to a large extent. Concretely, we find that comparing means performs well on a speaker verification task. Next, probing experiments show that standardizing the features effectively removes speaker information. Based on this observation, we propose a speaker normalization step to improve acoustic unit discovery using K-means clustering of CPC features. Finally, we show that a language model trained on the resulting units achieves some of the best results in the ZeroSpeech2021~Challenge.