 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Speaker Information in Self-Supervised Models to Improve Zero-Resource Speech Processing
Paper and Code

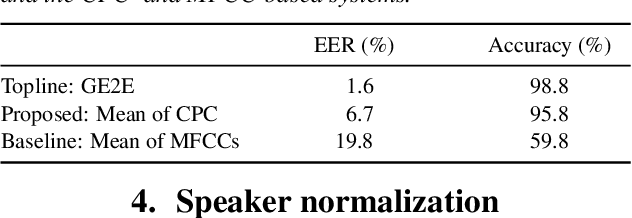
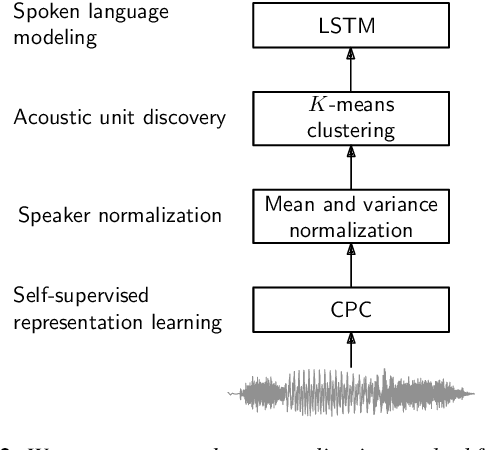
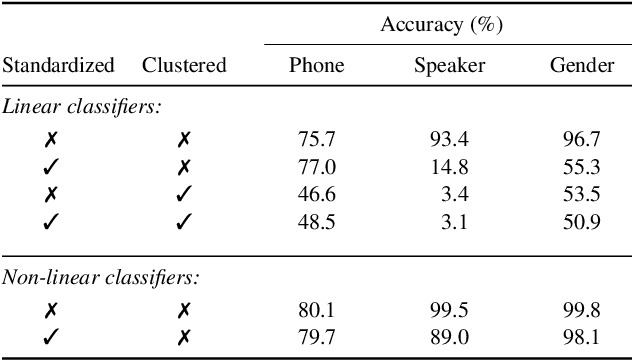
Contrastive predictive coding (CPC) aims to learn representations of speech by distinguishing future observations from a set of negative examples. Previous work has shown that linear classifiers trained on CPC features can accurately predict speaker and phone labels. However, it is unclear how the features actually capture speaker and phonetic information, and whether it is possible to normalize out the irrelevant details (depending on the downstream task). In this paper, we first show that the per-utterance mean of CPC features captures speaker information to a large extent. Concretely, we find that comparing means performs well on a speaker verification task. Next, probing experiments show that standardizing the features effectively removes speaker information. Based on this observation, we propose a speaker normalization step to improve acoustic unit discovery using K-means clustering of CPC features. Finally, we show that a language model trained on the resulting units achieves some of the best results in the ZeroSpeech2021~Challenge.