 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice Conversion Improves Cross-Domain Robustness for Spoken Arabic Dialect Identification
May 30, 2025Arabic dialect identification (ADI) systems are essential for large-scale data collection pipelines that enable the development of inclusive speech technologies for Arabic language varieties. However, the reliability of current ADI systems is limited by poor generalization to out-of-domain speech. In this paper, we present an effective approach based on voice conversion for training ADI models that achieves state-of-the-art performance and significantly improves robustness in cross-domain scenarios. Evaluated on a newly collected real-world test set spanning four different domains, our approach yields consistent improvements of up to +34.1% in accuracy across domains. Furthermore, we present an analysis of our approach and demonstrate that voice conversion helps mitigate the speaker bias in the ADI dataset. We release our robust ADI model and cross-domain evaluation dataset to support the development of inclusive speech technologies for Arabic.
kNN-SVC: Robust Zero-Shot Singing Voice Conversion with Additive Synthesis and Concatenation Smoothness Optimization
Apr 08, 2025



Robustness is critical in zero-shot singing voice conversion (SVC). This paper introduces two novel methods to strengthen the robustness of the kNN-VC framework for SVC. First, kNN-VC's core representation, WavLM, lacks harmonic emphasis, resulting in dull sounds and ringing artifacts. To address this, we leverage the bijection between WavLM, pitch contours, and spectrograms to perform additive synthesis, integrating the resulting waveform into the model to mitigate these issues. Second, kNN-VC overlooks concatenative smoothness, a key perceptual factor in SVC. To enhance smoothness, we propose a new distance metric that filters out unsuitable kNN candidates and optimize the summing weights of the candidates during inference. Although our techniques are built on the kNN-VC framework for implementation convenience, they are broadly applicable to general concatenative neural synthesis models. Experimental results validate the effectiveness of these modifications in achieving robust SVC. Demo: http://knnsvc.com Code: https://github.com/SmoothKen/knn-svc
MARS6: A Small and Robust Hierarchical-Codec Text-to-Speech Model
Jan 10, 2025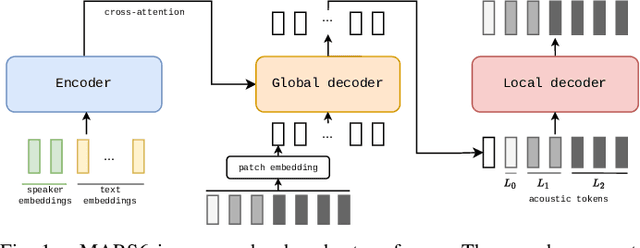
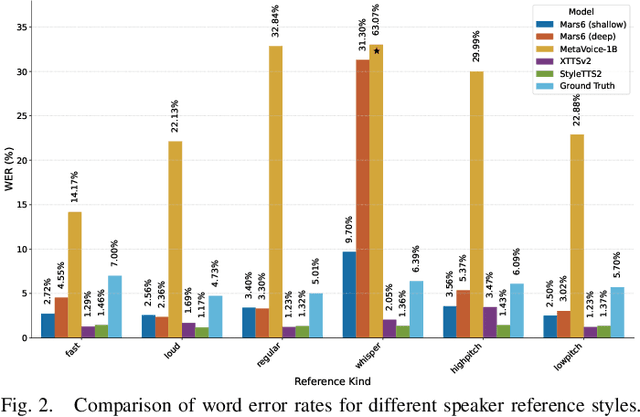
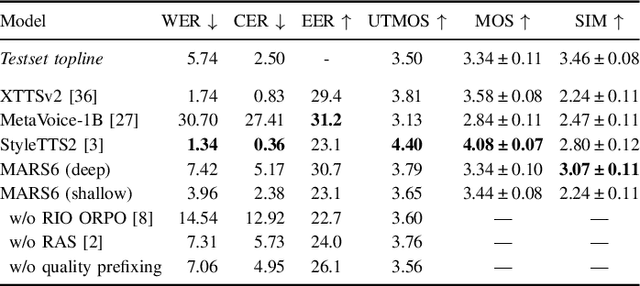
Codec-based text-to-speech (TTS) models have shown impressive quality with zero-shot voice cloning abilities. However, they often struggle with more expressive references or complex text inputs. We present MARS6, a robust encoder-decoder transformer for rapid, expressive TTS. MARS6 is built on recent improvements in spoken language modelling. Utilizing a hierarchical setup for its decoder, new speech tokens are processed at a rate of only 12 Hz, enabling efficient modelling of long-form text while retaining reconstruction quality. We combine several recent training and inference techniques to reduce repetitive generation and improve output stability and quality. This enables the 70M-parameter MARS6 to achieve similar performance to models many times larger. We show this in objective and subjective evaluations, comparing TTS output quality and reference speaker cloning ability. Project page: https://camb-ai.github.io/mars6-turbo/
Voice Conversion for Stuttered Speech, Instruments, Unseen Languages and Textually Described Voices
Oct 12, 2023
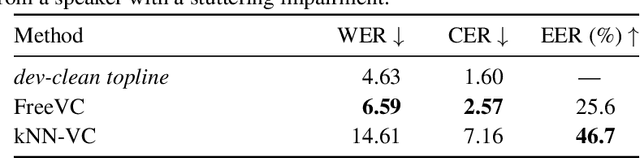
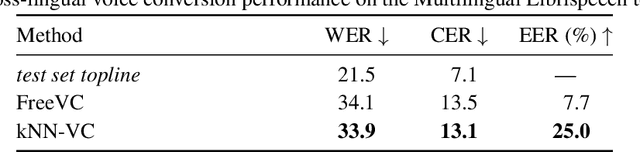
Voice conversion aims to convert source speech into a target voice using recordings of the target speaker as a reference. Newer models are producing increasingly realistic output. But what happens when models are fed with non-standard data, such as speech from a user with a speech impairment? We investigate how a recent voice conversion model performs on non-standard downstream voice conversion tasks. We use a simple but robust approach called k-nearest neighbors voice conversion (kNN-VC). We look at four non-standard applications: stuttered voice conversion, cross-lingual voice conversion, musical instrument conversion, and text-to-voice conversion. The latter involves converting to a target voice specified through a text description, e.g. "a young man with a high-pitched voice". Compared to an established baseline, we find that kNN-VC retains high performance in stuttered and cross-lingual voice conversion. Results are more mixed for the musical instrument and text-to-voice conversion tasks. E.g., kNN-VC works well on some instruments like drums but not on others. Nevertheless, this shows that voice conversion models - and kNN-VC in particular - are increasingly applicable in a range of non-standard downstream tasks. But there are still limitations when samples are very far from the training distribution. Code, samples, trained models: https://rf5.github.io/sacair2023-knnvc-demo/.
Disentanglement in a GAN for Unconditional Speech Synthesis
Jul 04, 2023



Can we develop a model that can synthesize realistic speech directly from a latent space, without explicit conditioning? Despite several efforts over the last decade, previous adversarial and diffusion-based approaches still struggle to achieve this, even on small-vocabulary datasets. To address this, we propose AudioStyleGAN (ASGAN) -- a generative adversarial network for unconditional speech synthesis tailored to learn a disentangled latent space. Building upon the StyleGAN family of image synthesis models, ASGAN maps sampled noise to a disentangled latent vector which is then mapped to a sequence of audio features so that signal aliasing is suppressed at every layer. To successfully train ASGAN, we introduce a number of new techniques, including a modification to adaptive discriminator augmentation which probabilistically skips discriminator updates. We apply it on the small-vocabulary Google Speech Commands digits dataset, where it achieves state-of-the-art results in unconditional speech synthesis. It is also substantially faster than existing top-performing diffusion models. We confirm that ASGAN's latent space is disentangled: we demonstrate how simple linear operations in the space can be used to perform several tasks unseen during training. Specifically, we perform evaluations in voice conversion, speech enhancement, speaker verification, and keyword classification. Our work indicates that GANs are still highly competitive in the unconditional speech synthesis landscape, and that disentangled latent spaces can be used to aid generalization to unseen tasks. Code, models, samples: https://github.com/RF5/simple-asgan/
Voice Conversion With Just Nearest Neighbors
May 30, 2023


Any-to-any voice conversion aims to transform source speech into a target voice with just a few examples of the target speaker as a reference. Recent methods produce convincing conversions, but at the cost of increased complexity -- making results difficult to reproduce and build on. Instead, we keep it simple. We propose k-nearest neighbors voice conversion (kNN-VC): a straightforward yet effective method for any-to-any conversion. First, we extract self-supervised representations of the source and reference speech. To convert to the target speaker, we replace each frame of the source representation with its nearest neighbor in the reference. Finally, a pretrained vocoder synthesizes audio from the converted representation. Objective and subjective evaluations show that kNN-VC improves speaker similarity with similar intelligibility scores to existing methods. Code, samples, trained models: https://bshall.github.io/knn-vc
TransFusion: Transcribing Speech with Multinomial Diffusion
Oct 14, 2022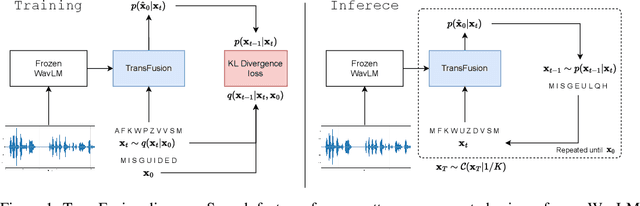
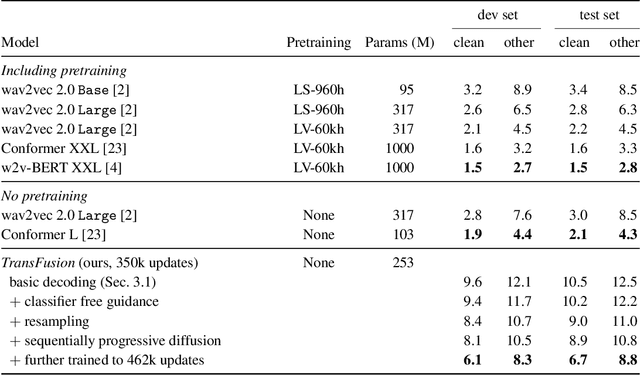
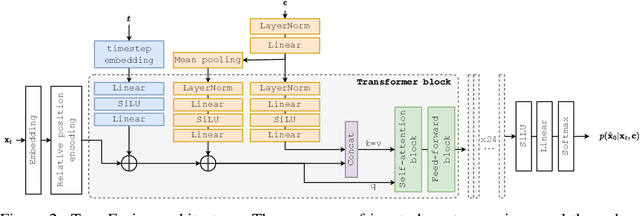
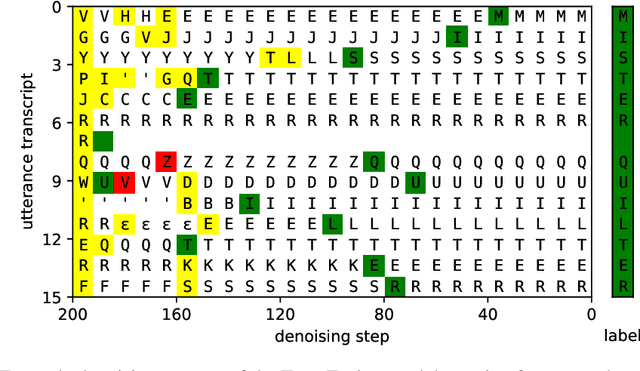
Diffusion models have shown exceptional scaling properties in the image synthesis domain, and initial attempts have shown similar benefits for applying diffusion to unconditional text synthesis. Denoising diffusion models attempt to iteratively refine a sampled noise signal until it resembles a coherent signal (such as an image or written sentence). In this work we aim to see whether the benefits of diffusion models can also be realized for speech recognition. To this end, we propose a new way to perform speech recognition using a diffusion model conditioned on pretrained speech features. Specifically, we propose TransFusion: a transcribing diffusion model which iteratively denoises a random character sequence into coherent text corresponding to the transcript of a conditioning utterance. We demonstrate comparable performance to existing high-performing contrastive models on the LibriSpeech speech recognition benchmark. To the best of our knowledge, we are the first to apply denoising diffusion to speech recognition. We also propose new techniques for effectively sampling and decoding multinomial diffusion models. These are required because traditional methods of sampling from acoustic models are not possible with our new discrete diffusion approach. Code and trained models are available: https://github.com/RF5/transfusion-asr
GAN You Hear Me? Reclaiming Unconditional Speech Synthesis from Diffusion Models
Oct 11, 2022
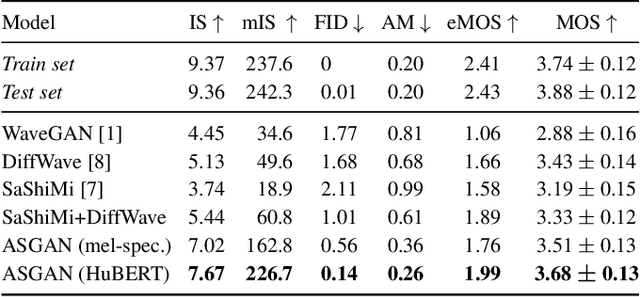
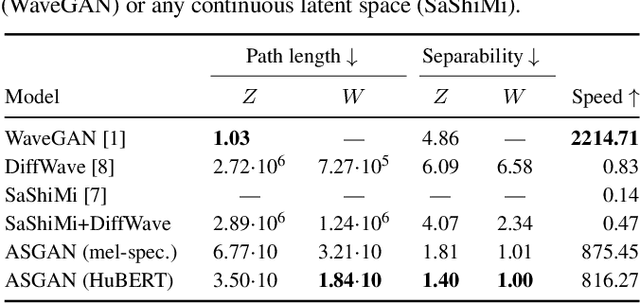
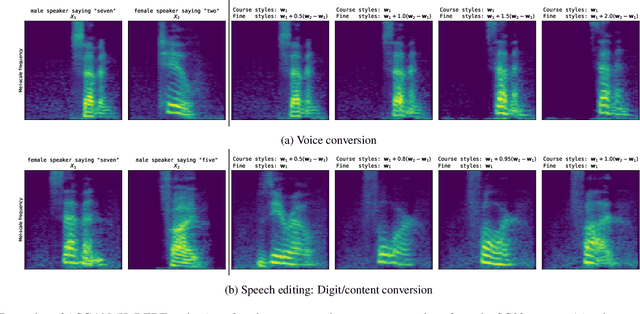
We propose AudioStyleGAN (ASGAN), a new generative adversarial network (GAN) for unconditional speech synthesis. As in the StyleGAN family of image synthesis models, ASGAN maps sampled noise to a disentangled latent vector which is then mapped to a sequence of audio features so that signal aliasing is suppressed at every layer. To successfully train ASGAN, we introduce a number of new techniques, including a modification to adaptive discriminator augmentation to probabilistically skip discriminator updates. ASGAN achieves state-of-the-art results in unconditional speech synthesis on the Google Speech Commands dataset. It is also substantially faster than the top-performing diffusion models. Through a design that encourages disentanglement, ASGAN is able to perform voice conversion and speech editing without being explicitly trained to do so. ASGAN demonstrates that GANs are still highly competitive with diffusion models. Code, models, samples: https://github.com/RF5/simple-asgan/.
Voice Conversion Can Improve ASR in Very Low-Resource Settings
Nov 04, 2021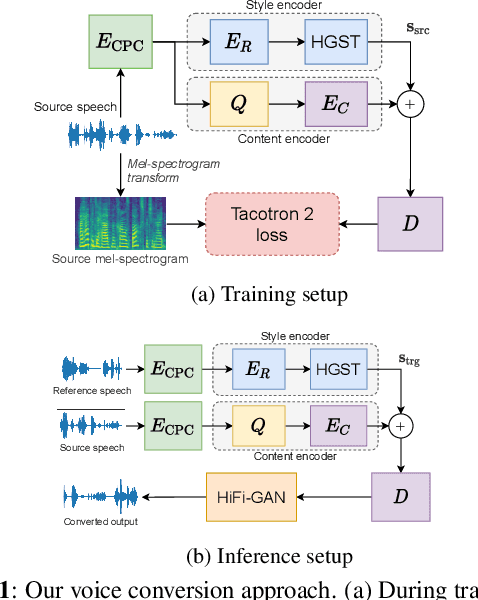
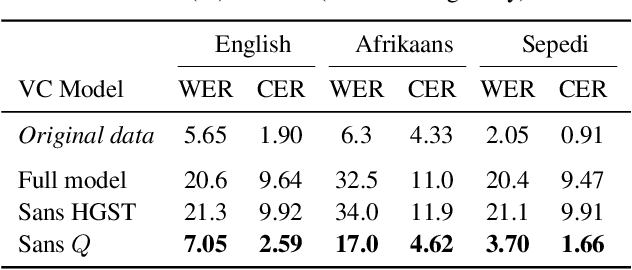
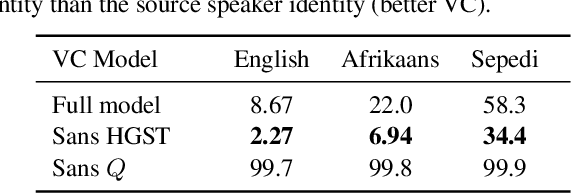

Voice conversion (VC) has been proposed to improve speech recognition systems in low-resource languages by using it to augment limited training data. But until recently, practical issues such as compute speed have limited the use of VC for this purpose. Moreover, it is still unclear whether a VC model trained on one well-resourced language can be applied to speech from another low-resource language for the purpose of data augmentation. In this work we assess whether a VC system can be used cross-lingually to improve low-resource speech recognition. Concretely, we combine several recent techniques to design and train a practical VC system in English, and then use this system to augment data for training a speech recognition model in several low-resource languages. We find that when using a sensible amount of augmented data, speech recognition performance is improved in all four low-resource languages considered.
Analyzing Speaker Information in Self-Supervised Models to Improve Zero-Resource Speech Processing
Aug 02, 2021
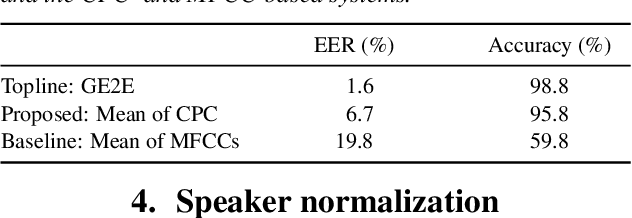
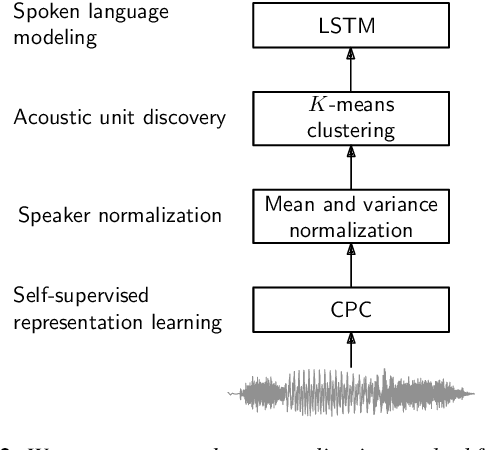
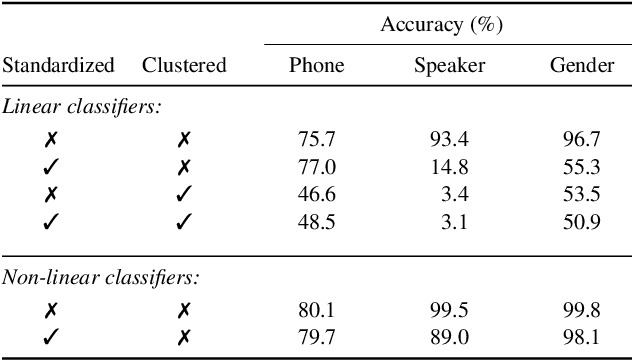
Contrastive predictive coding (CPC) aims to learn representations of speech by distinguishing future observations from a set of negative examples. Previous work has shown that linear classifiers trained on CPC features can accurately predict speaker and phone labels. However, it is unclear how the features actually capture speaker and phonetic information, and whether it is possible to normalize out the irrelevant details (depending on the downstream task). In this paper, we first show that the per-utterance mean of CPC features captures speaker information to a large extent. Concretely, we find that comparing means performs well on a speaker verification task. Next, probing experiments show that standardizing the features effectively removes speaker information. Based on this observation, we propose a speaker normalization step to improve acoustic unit discovery using K-means clustering of CPC features. Finally, we show that a language model trained on the resulting units achieves some of the best results in the ZeroSpeech2021~Challenge.